
 访问官网
访问官网 Github
Github 文档
文档 论文
论文简单高效的Transformer




EET(简单高效的Transformer)是一个友好的Pytorch推理插件,专注于基于Transformer的模型,使得大规模模型变得可负担。
特点
- 新功能🔥:支持百川、LLaMA和其他大语言模型。
- 新功能🔥:支持int8量化。
- 支持在单个GPU上运行超大规模模型。
- 专门用于多模态和自然语言处理任务的推理(CLIP/GPT-3/Bert/Seq2seq等)。
- 高性能。通过CUDA内核优化和量化/稀疏算法的效果,使基于transformer的模型变得更快。
- 为Transformers和Fairseq提供开箱即用的解决方案。省去繁琐的配置,只需几行代码即可让你的模型运行起来。
模型矩阵
| 模型类型 | Transformers | Fairseq | 量化 | 加速比 | 支持版本 |
|---|---|---|---|---|---|
| GPT-3 | ✅ | ✅ | ✅ | 2~8倍 | 0.0.1 beta |
| Bert | ✅ | ✅ | X | 1~5倍 | 0.0.1 beta |
| ALBert | ✅ | ✅ | X | 1~5倍 | 0.0.1 beta |
| Roberta | ✅ | X | X | 1~5倍 | 0.0.1 beta |
| T5 | ✅ | X | X | 4~8倍 | 1.0 |
| ViT | ✅ | X | X | 1~5倍 | 1.0 |
| CLIP(GPT+ViT) | ✅ | X | X | 2~4倍 | 1.0 |
| Distillbert | ✅ | X | X | 1~2倍 | 1.0 |
| Baichuan | ✅ | X | ✅ | 1~2倍 | 2.0 |
| LLaMA | ✅ | X | ✅ | 1~2倍 | 2.0 |
快速开始
环境要求
- cuda:>=11.4
- python:>=3.7
- gcc:>= 7.4.0
- torch:>=1.12.0
- numpy:>=1.19.1
- fairseq:==0.10.0
- transformers:>=4.31.0
以上环境为最低配置,最好使用更新版本。
安装
推荐使用docker镜像。
从源码安装
如果您从源码安装,您需要先安装必要的环境。然后按以下步骤进行:
$ git clone https://github.com/NetEase-FuXi/EET.git
$ pip install .
建议使用nvcr.io/nvidia/pytorch:23.04-py3及其他系列镜像,您也可以使用提供的Dockerfile文件。
从Docker开始
$ git clone https://github.com/NetEase-FuXi/EET.git
$ docker build -t eet_docker:0.1 .
$ nvidia-docker run -it --net=host -v /your/project/directory/:/root/workspace eet_docker:0.1 bash
EET及其所需环境已在docker中安装。
运行
我们提供三种类型的API:
- 算子API,如embedding、masked-multi-head-attention、ffn等。使您能够定义自定义模型。
- 模型API,如TransformerDecoder、BertEncoder等。使您能够将EET集成到您的PyTorch项目中。
- 应用API,如Transformers Pipeline。使您能够用几行代码运行模型。
算子API
算子API是C++/CUDA和Python的中间表示。我们提供了Transformer模型所需的几乎所有算子。您可以组合不同的OP来构建其他模型结构。
-
算子API表格
算子 Python API 备注 multi_head_attention EETSelfAttention 自注意力 masked_multi_head_attention EETSelfMaskedAttention 因果注意力 cross_multi_head_attention EETCrossAttention 交叉注意力 ffn EETFeedforward 前馈网络 embedding EETBertEmbedding 对应Fairseq和Transformers layernorm EETLayerNorm 与nn.LayerNorm相同 -
如何使用
这些OP的定义在文件EET/csrc/py11/eet2py.cpp中, 一些使用示例显示在python/eet下的文件中,告诉我们如何使用这些OP来组成经典模型。
模型API
作为插件,EET提供了友好的模型API(python/eet)以集成到Fairseq和Transformers中。
您只需根据下表找到相应的类(通常带有'EET'前缀),并使用from_torch和from_pretrained函数初始化对象。
注意:我们目前仅支持GPT-3的预填充。
EET和fairseq类比较表:
| EET | fairseq | 备注 |
|---|---|---|
| EETTransformerDecoder | TransformerDecoder | |
| EETTransformerDecoderLayer | TransformerDecoderLayer | |
| EETTransformerAttention | MultiheadAttention | |
| EETTransformerFeedforward | TransformerDecoderLayer | 多个小算子的融合 |
| EETTransformerEmbedding | Embedding + PositionalEmbedding | |
| EETTransformerLayerNorm | nn.LayerNorm |
EET和Transformers类比较表:
| EET | transformers | 备注 |
|---|---|---|
| EETBertModel | BertModel | |
| EETBertEmbedding | BertEmbeddings | |
| EETGPT2Model | GPT2Model | |
| EETGPT2Decoder | GPT2Model | Transformers没有GPT2Decoder |
| EETGPT2DecoderLayer | Block | |
| EETGPT2Attention | Attention | |
| EETGPT2Feedforward | MLP | |
| EETGPT2Embedding | nn.Embedding | |
| EETLayerNorm | nn.LayerNorm |
除了上述基本模型类型外,我们还扩展了一些特定任务的API以支持不同的任务。下表是我们部分特定任务模型API:
| EET | transformers | 备注 |
|---|---|---|
| EETBertForPreTraining | BertForPreTraining | |
| EETBertLMHeadModel | BertLMHeadModel | |
| EETBertForMaskedLM | BertForMaskedLM | |
| EETBertForNextSentencePrediction | BertForNextSentencePrediction | |
| EETBertForSequenceClassification | BertForSequenceClassification | |
| EETBertForMultipleChoice | BertForMultipleChoice | |
| EETBertForTokenClassification | BertForTokenClassification | |
| EETBertForQuestionAnswering | BertForQuestionAnswering |
- 如何使用
这是一个展示如何使用模型API的代码片段:
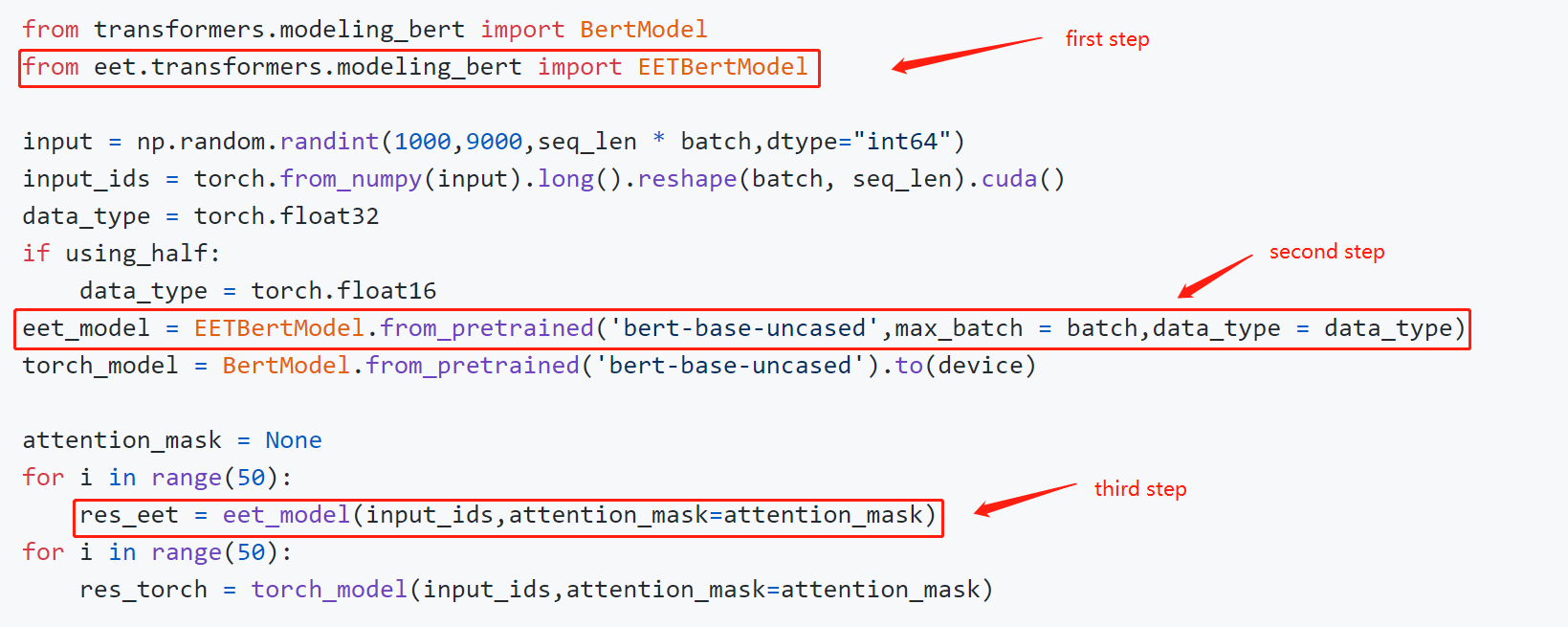
您可以直接使用特定任务的API构建应用程序。 这是一个填充掩码的示例:
from eet import EETRobertaForMaskedLM
from transformers import RobertaTokenizer
input = ["My <mask> is Sarah and I live in London"]
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
eet_roberta_model = EETRobertaForMaskedLM.from_pretrained('roberta-base',max_batch = max_batch_size,data_type = data_type)
# 第一步:分词
model_inputs = tokenizer(input,return_tensors = 'pt')
masked_index = torch.nonzero(model_inputs['input_ids'][0] == tokenizer.mask_token_id, as_tuple=False).squeeze(-1)
# 第二步:预测
prediction_scores = eet_roberta_model(model_inputs['input_ids'].cuda(),attention_mask = model_inputs['attention_mask'])
# 第三步:argmax
predicted_index = torch.argmax(prediction_scores.logits[0, masked_index]).item()
predicted_token = tokenizer.convert_ids_to_tokens(predicted_index)
更多示例请参考 example/python/models。
应用程序API
EET提供了现成的管道方法,简化了不同任务的应用程序构建,无需使用上述模型API。
以下是一个示例:
import torch
from eet import pipeline
max_batch_size = 1
model_path = 'roberta-base'
data_type = torch.float16
input = ["我的<mask>是Sarah,我住在伦敦"]
nlp = pipeline("fill-mask",model = model_path,data_type = data_type,max_batch_size = max_batch_size)
out = nlp(input)
目前我们支持以下任务:
| 任务 | 支持版本 |
|---|---|
| 文本分类 | 1.0 |
| 词符分类 | 1.0 |
| 问答 | 1.0 |
| 填充掩码 | 1.0 |
| 文本生成 | 1.0 |
| 图像分类 | 1.0 |
| 零样本图像分类 | 1.0 |
更多示例请参考 example/python/pipelines。
性能
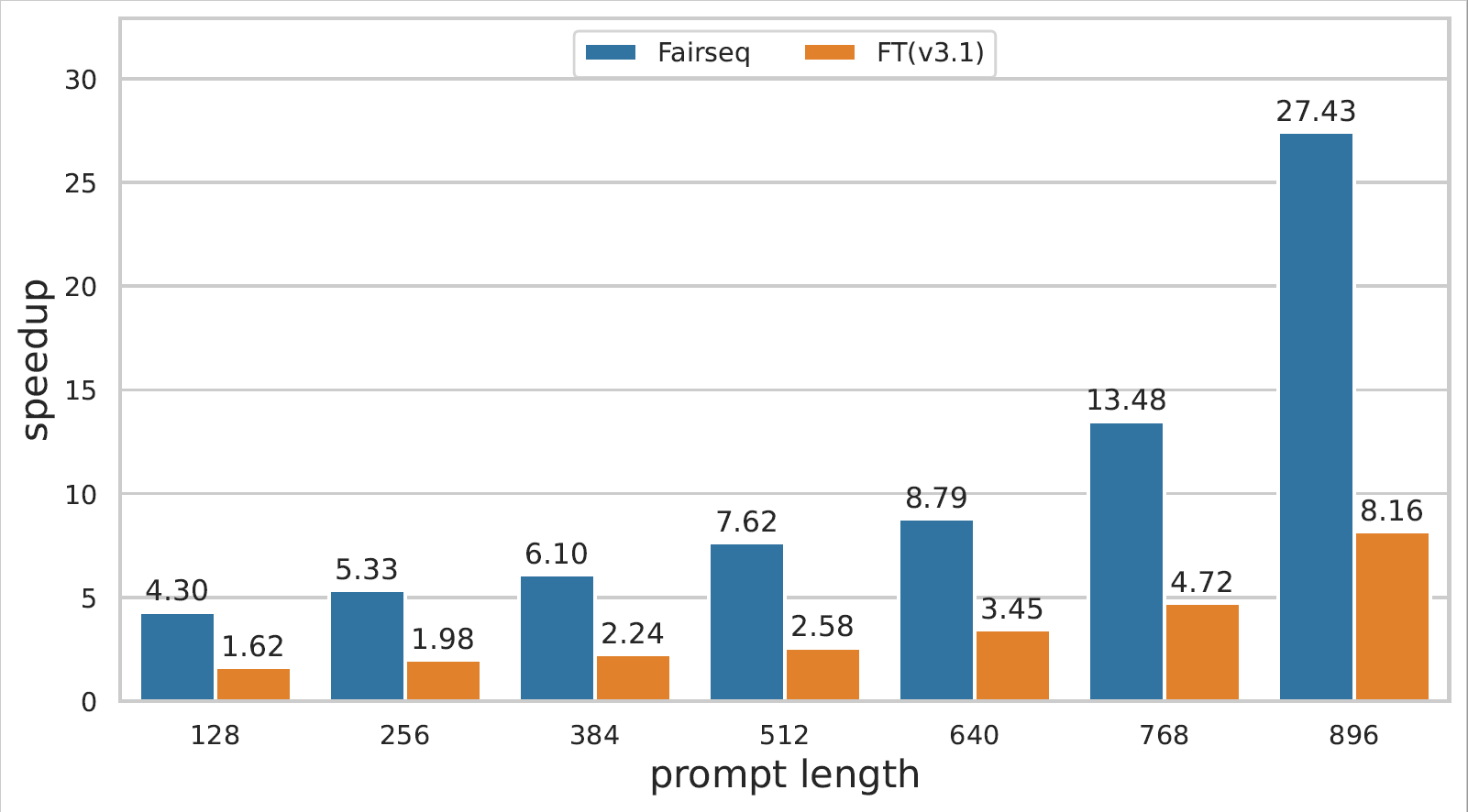
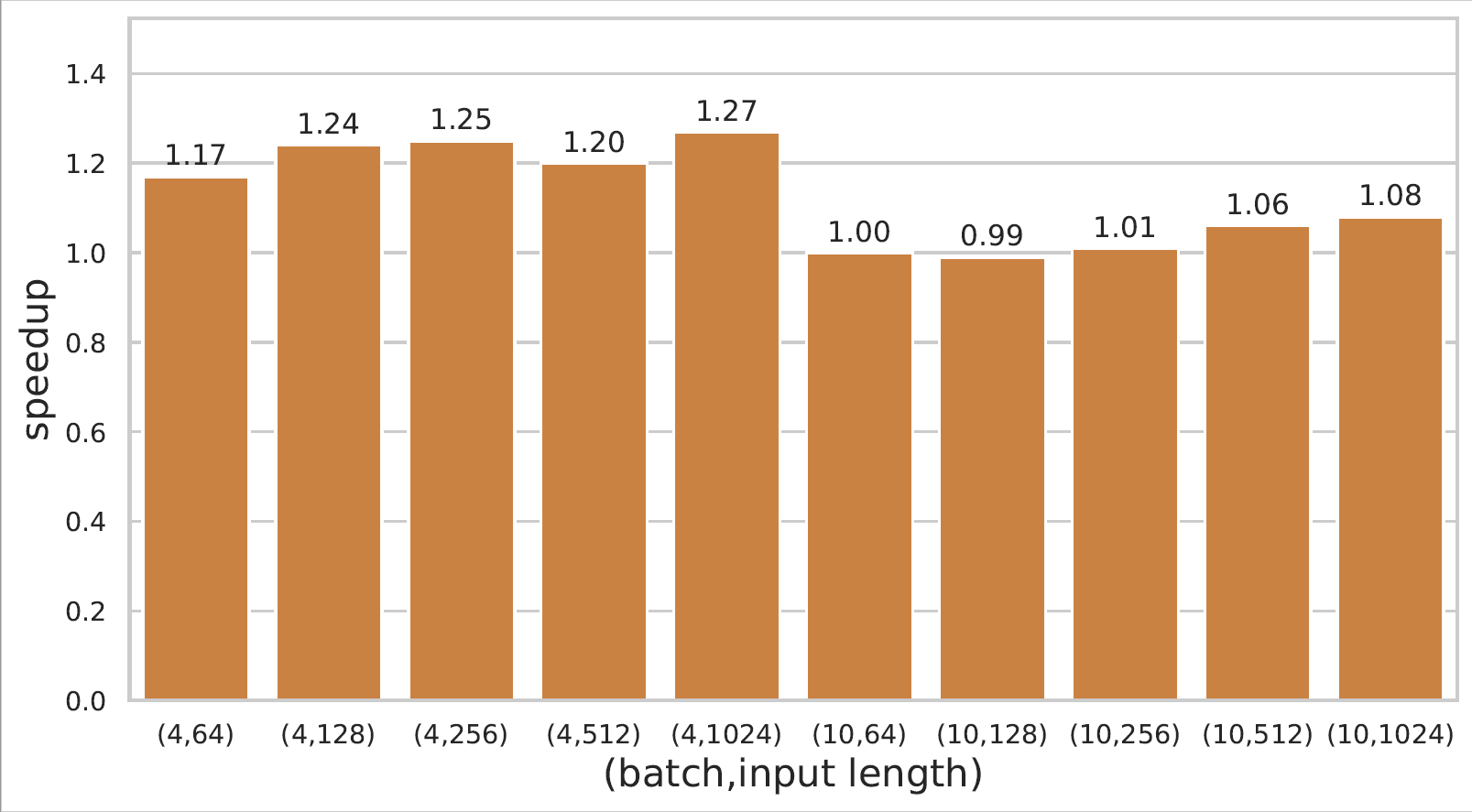
GPT-3和Bert模型推理的详细性能数据可以在链接查看。
- A100上的GPT-3
- 2080ti上的Bert
- 3090上的Llama13B
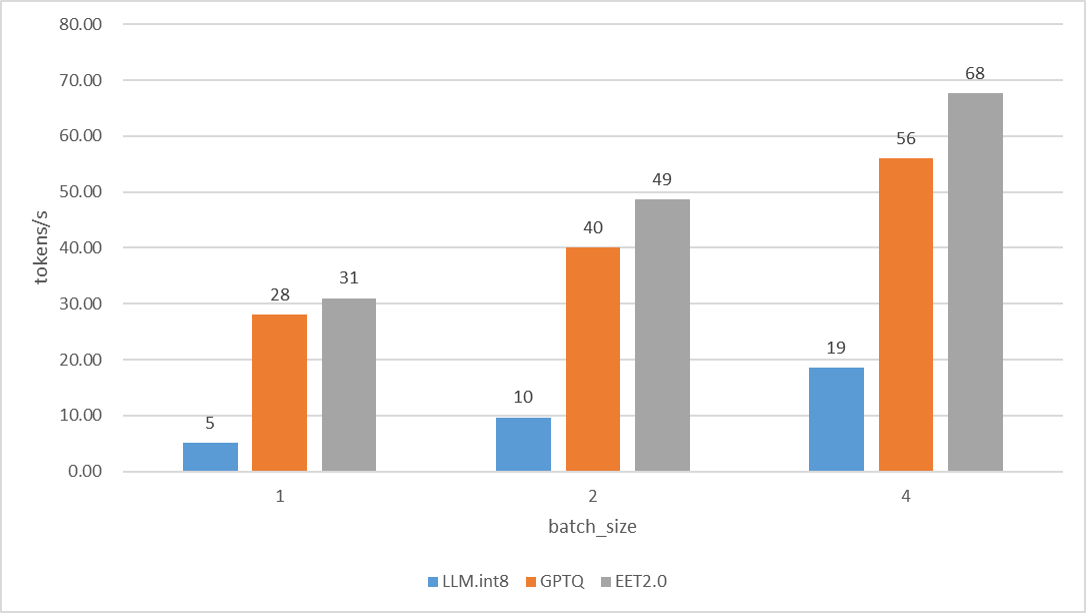
引用我们
如果您在研究中使用了EET,请引用以下论文。
@misc{https://doi.org/10.48550/arxiv.2104.12470,
doi = {10.48550/ARXIV.2104.12470},
url = {https://arxiv.org/abs/2104.12470},
author = {Li, Gongzheng and Xi, Yadong and Ding, Jingzhen and Wang, Duan and Liu, Bai and Fan, Changjie and Mao, Xiaoxi and Zhao, Zeng},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Easy and Efficient Transformer : Scalable Inference Solution For large NLP model},
视频
我们在知源LIVE上有一场分享,链接:https://event.baai.ac.cn/activities/325。
联系我们
您可以通过GitHub issues发布您的问题。
您也可以通过电子邮件联系我们:
ligongzheng@corp.netease.com, dingjingzhen@corp.netease.com, zhaosida@corp.netease.com











