
EvalScope简介
EvalScope是一个专为评估大型模型(包括大型语言模型和多模态大型语言模型)而设计的开源框架。随着大型模型的快速发展,对模型进行全面、客观的评估变得越来越重要。EvalScope正是为了满足这一需求而诞生的,它提供了一套简化而高效的评估流程,帮助研究人员和开发者更好地理解和比较不同模型的性能。
框架特性
EvalScope具有以下主要特性:
-
丰富的基准数据集: 预加载了多个常用的测试基准,包括MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval等。这些数据集涵盖了多个领域和任务类型,可以全面评估模型的能力。
-
多样化的评估指标: 实现了多种常用的评估指标,可以从不同角度衡量模型的性能。
-
统一的模型接口: 提供了统一的模型访问机制,兼容多个模型系列的Generate和Chat接口,简化了评估过程。
-
自动化评估: 包括客观问题的自动评估,以及使用专家模型进行复杂任务评估,提高了评估效率。
-
评估报告生成: 可自动生成详细的评估报告,方便分析和比较。
-
Arena模式: 用于模型间的比较和客观评估,支持多种评估模式,包括:
- 单模式: 对单个模型进行评分
- 基线对比模式: 与基线模型进行比较
- 全对比模式: 所有模型间进行两两比较
-
可视化工具: 提供直观的评估结果展示,便于理解和分析。
-
模型性能评估: 提供模型推理服务的性能测试工具和详细统计信息。
-
OpenCompass集成: 支持使用OpenCompass作为评估后端,提供更高级的封装和任务简化。
-
VLMEvalKit集成: 支持使用VLMEvalKit作为评估后端,便于启动多模态评估任务。
-
全链路支持: 通过与ms-swift训练框架的无缝集成,提供从模型训练、部署、评估到报告查看的一站式开发流程。
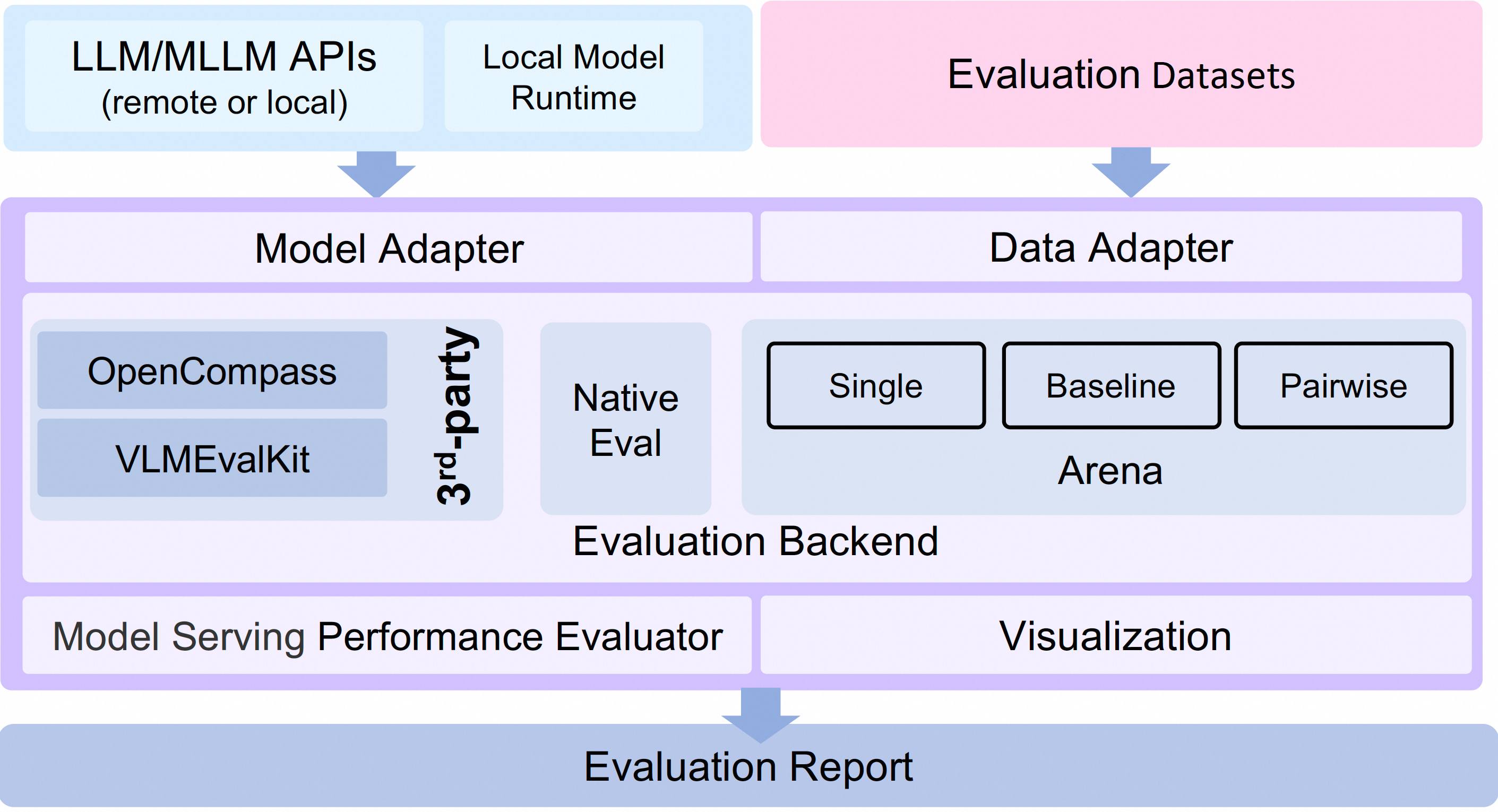
框架架构
EvalScope的架构包括以下主要模块:
-
模型适配器: 用于将特定模型的输出转换为框架所需的格式,支持API调用模型和本地运行模型。
-
数据适配器: 负责转换和处理输入数据,以满足各种评估需求和格式。
-
评估后端:
- Native: EvalScope自身的默认评估框架
- OpenCompass: 支持使用OpenCompass作为评估后端
- VLMEvalKit: 支持使用VLMEvalKit作为评估后端
- ThirdParty: 其他第三方评估任务,如ToolBench
-
性能评估器: 负责测量模型推理服务的性能,包括性能测试、压力测试、性能报告生成和可视化。
-
评估报告: 生成总结模型性能的最终评估报告。
-
可视化: 提供可视化结果,帮助用户直观理解评估结果。
快速开始
要开始使用EvalScope,您可以通过以下步骤快速进行简单的评估:
-
安装EvalScope:
pip install evalscope -
运行简单评估:
python -m evalscope.run \ --model qwen/Qwen2-0.5B-Instruct \ --template-type qwen \ --datasets arc
这个命令将使用默认设置在ARC数据集上评估Qwen2-0.5B-Instruct模型。
参数化评估
如果您想进行更加定制化的评估,可以使用更多参数:
python evalscope/run.py \
--model qwen/Qwen2-0.5B-Instruct \
--template-type qwen \
--model-args revision=v1.0.2,precision=torch.float16,device_map=auto \
--datasets mmlu ceval \
--use-cache true \
--limit 10
这个命令将在MMLU和CEval数据集上评估Qwen2-0.5B-Instruct模型,使用指定的模型参数和生成配置。
评估后端
EvalScope支持多种评估后端:
- Native: EvalScope自身的默认评估框架
- OpenCompass: 支持使用OpenCompass启动评估任务
- VLMEvalKit: 支持使用VLMEvalKit启动多模态评估任务
- ThirdParty: 其他第三方评估任务,如ToolBench
自定义数据集评估
EvalScope支持使用自定义数据集进行评估。您可以参考自定义数据集评估用户指南了解详细信息。
离线评估
EvalScope支持在没有网络连接的情况下使用本地数据集评估模型。详情请参考离线评估用户指南。
Arena模式
Arena模式允许通过两两对战的方式评估多个候选模型,并可以选择使用AI增强自动审核(AAR)自动评估过程或人工评估来获得评估报告。详情请参考Arena模式用户指南。
模型服务性能评估
EvalScope提供了一个专注于大型语言模型的压力测试工具,可以自定义支持各种数据集格式和不同的API协议格式。详情请参考模型服务性能评估用户指南。
排行榜
EvalScope还提供了LLM排行榜,旨在为研究人员和开发者提供一个客观、全面的评估标准和平台,帮助他们了解和比较ModelScope上各种模型在不同任务上的表现。您可以在这里查看最新的排行榜。
未来计划
EvalScope团队正在积极开发和改进框架,未来计划包括:
- Agents评估
- vLLM支持
- 分布式评估
- 多模态评估
- 更多基准测试(如GAIA、GPQA、MBPP等)
- 自动审核员功能增强
总的来说,EvalScope为大型模型评估提供了一个强大而灵活的框架。无论您是研究人员还是开发者,EvalScope都能帮助您更好地理解和比较不同模型的性能,从而做出更明智的决策。随着框架的不断发展和完善,相信EvalScope将在大型模型评估领域发挥越来越重要的作用。









