
 访问官网
访问官网 Github
Github 文档
文档简体中文 | English



📖 目录
📝 简介
大型语言模型(LLMs)的评估已成为评估和改进LLMs的关键过程。为了更好地支持大模型评估,我们提出了EvalScope框架,它包括以下组件和特性:
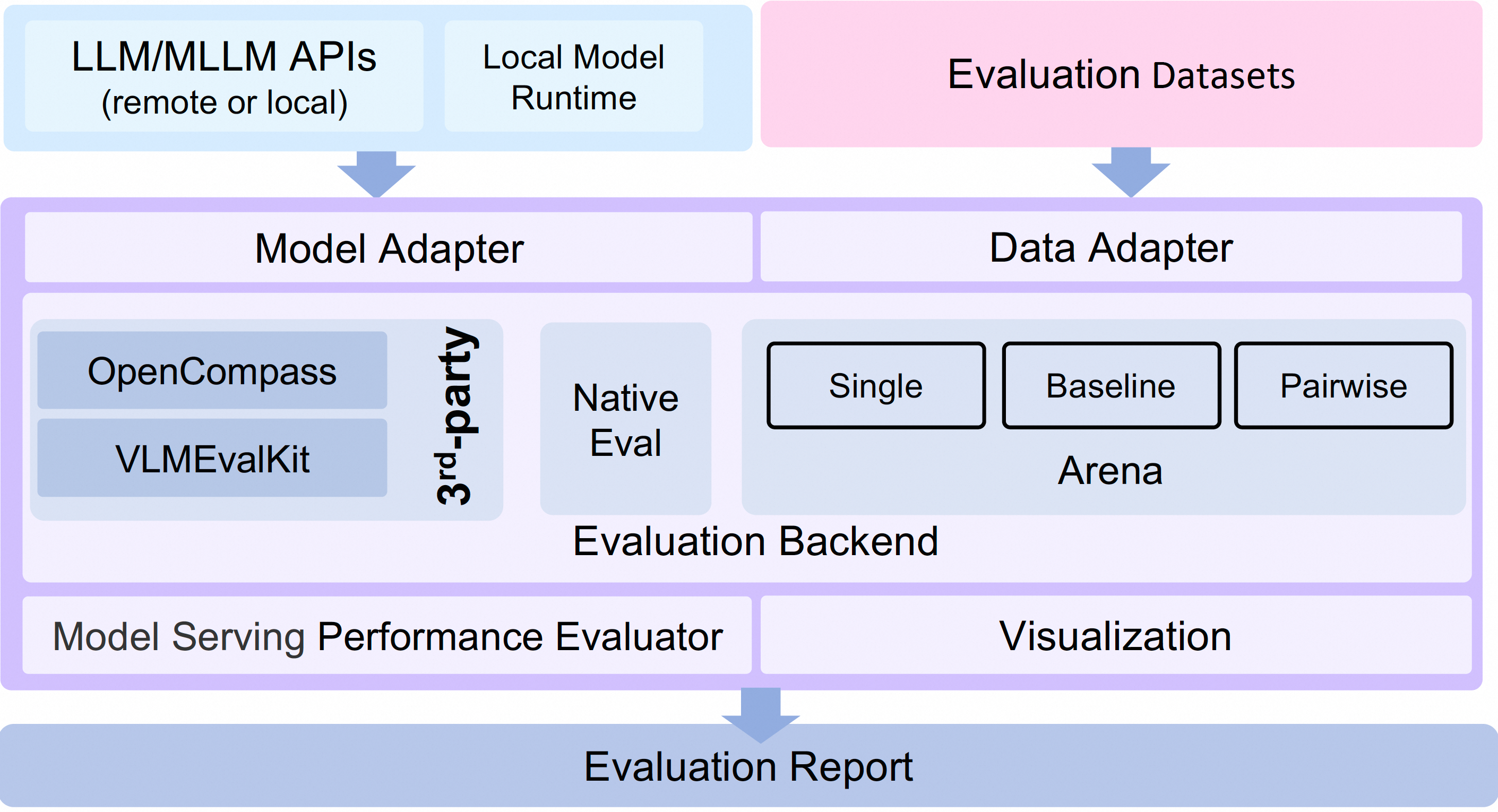 EvalScope框架。
EvalScope框架。
- 预配置常用基准数据集,包括:MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval等
- 实现常用评估指标
- 统一的模型集成,兼容多个模型系列的生成和对话接口
- 自动评估(评估器):
- 客观题自动评估
- 使用专家模型实现复杂任务评估
- 生成评估报告
- 竞技场模式
- 可视化工具
- 模型推理性能评估教程
- 支持OpenCompass作为评估后端,具有高级封装和任务简化功能,可轻松将任务提交给OpenCompass进行评估
- 支持VLMEvalKit作为评估后端。通过EvalScope启动VLMEvalKit的多模态评估任务,支持各种多模态模型和数据集
- 全流程支持:无缝集成SWIFT,轻松实现模型训练、部署服务、启动评估任务、查看评估报告,实现大模型开发的端到端流程
特性
- 轻量级,最小化不必要的抽象和配置
- 易于定制
- 只需实现一个类即可集成新数据集
- 模型可以托管在ModelScope上,只需模型ID即可启动评估
- 支持部署本地托管的模型
- 评估报告可视化
- 丰富的评估指标
- 基于模型的自动评估过程,支持多种评估模式
- 单模式:专家模型对单个模型评分
- 基线对比模式:与基线模型比较
- 全对比模式:所有模型两两对比
🎉 新闻
- [2024.07.31] 重大变更:SDK名称已从
llmuses更改为evalscope,请在代码中更新SDK名称。 - [2024.07.26] 支持VLMEvalKit作为第三方评估框架,启动多模态模型评估任务。使用指南 🔥🔥🔥
- [2024.06.29] 支持OpenCompass作为第三方评估框架。我们提供了高级封装,支持通过pip安装,并简化了评估任务配置。使用指南 🔥🔥🔥
- [2024.06.13] EvalScope已更新至0.3.x版本,支持ModelScope SWIFT框架进行LLMs评估。🚀🚀🚀
- [2024.06.13] 我们已支持ToolBench作为第三方评估后端,用于Agents评估。🚀🚀🚀
🛠️ 安装
通过pip安装
- 创建conda环境[可选]
conda create -n evalscope python=3.10
conda activate evalscope
- 安装EvalScope
pip install evalscope # 安装原生后端(默认)
pip install evalscope[opencompass] # 安装OpenCompass后端
pip install evalscope[vlmeval] # 安装VLMEvalKit后端
pip install evalscope[all] # 安装所有后端(原生、OpenCompass、VLMEvalKit)
弃用警告:对于0.4.3或更早版本,请使用以下命令进行安装:
pip install llmuses<=0.4.3
# 使用方法:
from llmuses.run import run_task
...
从源代码安装
- 下载源代码
git clone https://github.com/modelscope/evalscope.git
- 安装依赖
cd evalscope/
pip install -e .
🚀 快速开始
简单评估
使用pip安装后的命令行:
python -m evalscope.run --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --limit 100
使用源代码的命令行:
python evalscope/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets mmlu ceval --limit 10
参数:
- --model: ModelScope模型ID,模型链接:ZhipuAI/chatglm3-6b
使用模型参数进行评估
python evalscope/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --model-args revision=v1.0.2,precision=torch.float16,device_map=auto --datasets mmlu ceval --use-cache true --limit 10
python evalscope/run.py --model qwen/Qwen-1_8B --generation-config do_sample=false,temperature=0.0 --datasets ceval --dataset-args '{"ceval": {"few_shot_num": 0, "few_shot_random": false}}' --limit 10
参数:
- --model-args:模型参数:revision、precision、device_map,格式为key=value,key=value
- --datasets:数据集列表,用空格分隔
- --use-cache:
true或false,是否使用缓存,默认为false - --dataset-args:评估设置,json格式,键为数据集名称,值应为数据集的参数
- --few_shot_num:少样本数据数量
- --few_shot_random:是否使用随机少样本数据,默认为
true - --local_path:本地数据集路径
- --limit:每个子数据集评估的最大样本数
- --template-type:模型模板类型,参见模板类型列表
注意:您可以使用以下命令查看模型的模板类型列表:
from evalscope.models.template import TemplateType
print(TemplateType.get_template_name_list())
评估后端
EvalScope支持使用第三方评估框架来启动评估任务,我们称之为评估后端。目前支持的评估后端包括:
- Native:EvalScope自己的默认评估框架,支持各种评估模式,包括单模型评估、竞技场模式和基准模型比较模式。
- OpenCompass:通过EvalScope启动OpenCompass评估任务。轻量级,易于定制,支持与LLM微调框架ModelScope Swift无缝集成。
- VLMEvalKit:通过EvalScope启动VLMEvalKit多模态评估任务。支持各种多模态模型和数据集,并提供与LLM微调框架ModelScope Swift的无缝集成。
- ThirdParty:第三方任务,例如ToolBench,您可以将自己的评估任务作为第三方后端贡献给EvalScope。
OpenCompass评估后端
为了便于使用OpenCompass评估后端,我们对OpenCompass源代码进行了定制,并将其命名为ms-opencompass。这个版本包括基于原始版本对评估任务配置和执行的优化,并支持通过PyPI安装。这使用户能够通过EvalScope启动轻量级OpenCompass评估任务。此外,我们初步开放了基于API的OpenAI API格式评估任务。您可以使用ModelScope Swift部署模型服务,其中swift deploy支持使用vLLM启动模型推理服务。
安装
# 使用额外选项安装
pip install evalscope[opencompass]
数据准备
OpenCompass后端可用的数据集:
'obqa', 'AX_b', 'siqa', 'nq', 'mbpp', 'winogrande', 'mmlu', 'BoolQ', 'cluewsc', 'ocnli', 'lambada', 'CMRC', 'ceval', 'csl', 'cmnli', 'bbh', 'ReCoRD', 'math', 'humaneval', 'eprstmt', 'WSC', 'storycloze', 'MultiRC', 'RTE', 'chid', 'gsm8k', 'AX_g', 'bustm', 'afqmc', 'piqa', 'lcsts', 'strategyqa', 'Xsum', 'agieval', 'ocnli_fc', 'C3', 'tnews', 'race', 'triviaqa', 'CB', 'WiC', 'hellaswag', 'summedits', 'GaokaoBench', 'ARC_e', 'COPA', 'ARC_c', 'DRCD'
您可以使用以下代码列出所有可用的数据集:
from evalscope.backend.opencompass import OpenCompassBackendManager
print(f'** OpenCompass后端的所有数据集:{OpenCompassBackendManager.list_datasets()}')
数据集下载:
-
选项1:从ModelScope下载
git clone https://www.modelscope.cn/datasets/swift/evalscope_resource.git -
选项2:从OpenCompass GitHub下载
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
解压文件并将路径设置为当前工作目录中的data目录。
模型服务
我们使用ModelScope swift部署模型服务,参见:ModelScope Swift
# 安装ms-swift
pip install ms-swift
# 部署模型
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type llama3-8b-instruct --port 8000
模型评估
参考示例:example_eval_swift_openai_api配置和执行评估任务:
python examples/example_eval_swift_openai_api.py
VLMEvalKit评估后端
为了便于使用VLMEvalKit评估后端,我们对VLMEvalKit源代码进行了定制,并将其命名为ms-vlmeval。这个版本封装了基于原始版本的评估任务配置和执行,并支持通过PyPI安装,使用户能够通过EvalScope启动轻量级VLMEvalKit评估任务。此外,我们支持OpenAI API格式的基于API的评估任务。您可以使用ModelScope swift部署多模态模型服务。
安装
# 使用额外选项安装
pip install evalscope[vlmeval]
数据准备
目前支持的数据集包括:
'COCO_VAL', 'MME', 'HallusionBench', 'POPE', 'MMBench_DEV_EN', 'MMBench_TEST_EN', 'MMBench_DEV_CN', 'MMBench_TEST_CN', 'MMBench', 'MMBench_CN', 'MMBench_DEV_EN_V11', 'MMBench_TEST_EN_V11', 'MMBench_DEV_CN_V11', 'MMBench_TEST_CN_V11', 'MMBench_V11', 'MMBench_CN_V11', 'SEEDBench_IMG', 'SEEDBench2', 'SEEDBench2_Plus', 'ScienceQA_VAL', 'ScienceQA_TEST', 'MMT-Bench_ALL_MI', 'MMT-Bench_ALL', 'MMT-Bench_VAL_MI', 'MMT-Bench_VAL', 'AesBench_VAL', 'AesBench_TEST', 'CCBench', 'AI2D_TEST', 'MMStar', 'RealWorldQA', 'MLLMGuard_DS', 'BLINK', 'OCRVQA_TEST', 'OCRVQA_TESTCORE', 'TextVQA_VAL', 'DocVQA_VAL', 'DocVQA_TEST', 'InfoVQA_ VAL', 'InfoVQA_TEST', 'ChartQA_VAL', 'ChartQA_TEST', 'MathVision', 'MathVision_MINI', 'MMMU_DEV_VAL', 'MMMU_TEST', 'OCRBench', 'MathVista_MINI', 'LLaVABench', 'MMVet', 'MTVQA_TEST', 'MMLongBench_DOC', 'VCR_EN_EASY_500', 'VCR_EN_EASY_100', 'VCR_EN_EASY_ALL', 'VCR_EN_HARD_500', 'VCR_EN_HARD_100', 'VCR_EN_HARD_ALL', 'VCR_ZH_EASY_500', 'VCR_ZH_EASY_100', 'VCR_Z H_EASY_ALL', 'VCR_ZH_HARD_500', 'VCR_ZH_HARD_100', 'VCR_ZH_HARD_ALL', 'MMBench-Video', 'Video-MME', 'MMBench_DEV_EN', 'MMBench_TEST_EN', 'MMBench_DEV_CN', 'MMBench_TEST_CN', 'MMBench', 'MMBench_CN', 'MMBench_DEV_EN_V11', 'MMBench_TEST_EN_V11', 'MMBench_DEV_CN_V11', 'MMBench_TEST_CN_V11', 'MM Bench_V11', 'MMBench_CN_V11', 'SEEDBench_IMG', 'SEEDBench2', 'SEEDBench2_Plus', 'ScienceQA_VAL', 'ScienceQA_TEST', 'MMT-Bench_ALL_MI', 'MMT-Bench_ALL', 'MMT-Bench_VAL_MI', 'MMT-Bench_VAL', 'AesBench_VAL', 'AesBench_TEST', 'CCBench', 'AI2D_TEST', 'MMStar', 'RealWorldQA', 'MLLMGuard_DS', 'BLINK'
有关数据集的详细信息,请参考VLMEvalKit支持的多模态评估集。
你可以使用以下代码查看数据集名称列表:
from evalscope.backend.vlm_eval_kit import VLMEvalKitBackendManager
print(f'** VLMEvalKit后端的所有模型:{VLMEvalKitBackendManager.list_supported_models().keys()}')
如果在加载数据集时本地不存在数据集文件,它将自动下载到~/LMUData/目录。
模型评估
有两种方法可以评估模型:
1. 使用ModelScope Swift部署进行模型评估
模型部署 使用ModelScope Swift部署模型服务。详细说明请参考:ModelScope Swift MLLM部署指南
# 安装ms-swift
pip install ms-swift
# 部署qwen-vl-chat多模态模型服务
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type qwen-vl-chat --model_id_or_path models/Qwen-VL-Chat
模型评估 参考示例文件:example_eval_vlm_swift配置评估任务。 执行评估任务:
python examples/example_eval_vlm_swift.py
2. 本地模型推理评估
模型推理评估 跳过模型服务部署,直接在本地机器上进行推理。参考示例文件:example_eval_vlm_local配置评估任务。 执行评估任务:
python examples/example_eval_vlm_local.py
(可选)部署评判模型
使用ModelScope swift将本地语言模型部署为评判/提取器。详情请参考:ModelScope Swift LLM部署指南。如果未部署评判模型,将使用精确匹配。
# 将qwen2-7b部署为评判模型
CUDA_VISIBLE_DEVICES=1 swift deploy --model_type qwen2-7b-instruct --model_id_or_path models/Qwen2-7B-Instruct --port 8866
你必须配置以下环境变量以正确调用评判模型:
OPENAI_API_KEY=EMPTY
OPENAI_API_BASE=http://127.0.0.1:8866/v1/chat/completions # 评判模型的api_base
LOCAL_LLM=qwen2-7b-instruct # 评判模型的model_id
模型评估
参考示例文件:example_eval_vlm_swift配置评估任务。
执行评估任务:
python examples/example_eval_vlm_swift.py
本地数据集
你可以使用本地数据集在没有网络连接的情况下评估模型。
1. 下载并解压数据集
# 设置路径为/path/to/workdir
wget https://modelscope.oss-cn-beijing.aliyuncs.com/open_data/benchmark/data.zip
unzip data.zip
2. 使用本地数据集评估模型
python evalscope/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-args '{"arc": {"local_path": "/path/to/workdir/data/arc"}}' --limit 10
# 参数:
# --dataset-hub: 数据集来源:`ModelScope`、`Local`、`HuggingFace`(待实现),默认为`ModelScope`
# --dataset-args: json格式,键为数据集名称,值应为数据集的参数
3. (可选) 使用本地模式提交评估任务
# 1. 准备模型本地文件夹,文件夹结构参考chatglm3-6b,链接:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
# 例如,将模型文件夹下载到本地路径 /path/to/ZhipuAI/chatglm3-6b
# 2. 执行离线评估任务
python evalscope/run.py --model /path/to/ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-args '{"arc": {"local_path": "/path/to/workdir/data/arc"}}' --limit 10
使用run_task函数
1. 配置
import torch
from evalscope.constants import DEFAULT_ROOT_CACHE_DIR
# 配置示例
your_task_cfg = {
'model_args': {'revision': None, 'precision': torch.float16, 'device_map': 'auto'},
'generation_config': {'do_sample': False, 'repetition_penalty': 1.0, 'max_new_tokens': 512},
'dataset_args': {},
'dry_run': False,
'model': 'ZhipuAI/chatglm3-6b',
'template_type': 'chatglm3',
'datasets': ['arc', 'hellaswag'],
'work_dir': DEFAULT_ROOT_CACHE_DIR,
'outputs': DEFAULT_ROOT_CACHE_DIR,
'mem_cache': False,
'dataset_hub': 'ModelScope',
'dataset_dir': DEFAULT_ROOT_CACHE_DIR,
'stage': 'all',
'limit': 10,
'debug': False
}
2. 执行任务
from evalscope.run import run_task
run_task(task_cfg=your_task_cfg)
竞技场模式
竞技场模式允许通过两两对战的方式评估多个候选模型,可以选择使用AI增强自动评审员(AAR)自动评估流程或人工评估来获得评估报告。流程如下:
1. 环境准备
a. 数据准备,问题数据格式参考:evalscope/registry/data/question.jsonl
b. 如需使用自动评估流程(AAR),需要配置相关环境变量。以基于GPT-4的自动评审员流程为例,需要配置以下环境变量:
> export OPENAI_API_KEY=YOUR_OPENAI_API_KEY
2. 配置文件
参考:evalscope/registry/config/cfg_arena.yaml
参数说明:
questions_file: 问题数据路径
answers_gen: 候选模型预测结果生成,支持多个模型,可通过enable参数控制是否启用模型
reviews_gen: 评估结果生成,目前默认使用GPT-4作为Auto-reviewer,可通过enable参数控制是否启用该步骤
elo_rating: ELO评分算法,可通过enable参数控制是否启用该步骤,注意该步骤依赖review_file必须存在
3. 执行脚本
#用法:
cd evalscope
# 演练模式
python evalscope/run_arena.py -c registry/config/cfg_arena.yaml --dry-run
# 执行脚本
python evalscope/run_arena.py --c registry/config/cfg_arena.yaml
4. 可视化
# 用法:
streamlit run viz.py -- --review-file evalscope/registry/data/qa_browser/battle.jsonl --category-file evalscope/registry/data/qa_browser/category_mapping.yaml
单模型评估模式
在此模式下,我们仅对单个模型的输出进行评分,不进行两两比较。
1. 配置文件
参考:evalscope/registry/config/cfg_single.yaml
参数说明:
questions_file: 问题数据路径
answers_gen: 候选模型预测结果生成,支持多个模型,可通过enable参数控制是否启用模型
reviews_gen: 评估结果生成,目前默认使用GPT-4作为Auto-reviewer,可通过enable参数控制是否启用该步骤
rating_gen: 评分算法,可通过enable参数控制是否启用该步骤,注意该步骤依赖review_file必须存在
2. 执行脚本
#示例:
python evalscope/run_arena.py --c registry/config/cfg_single.yaml
基准模型比较模式
在此模式下,我们选择基准模型,并将其他模型与基准模型进行比较评分。这种模式可以方便地将新模型添加到排行榜中(只需要运行新模型与基准模型的评分即可)。
1. 配置文件
参考:evalscope/registry/config/cfg_pairwise_baseline.yaml
参数说明:
questions_file: 问题数据路径
answers_gen: 候选模型预测结果生成,支持多个模型,可通过enable参数控制是否启用模型
reviews_gen: 评估结果生成,目前默认使用GPT-4作为Auto-reviewer,可通过enable参数控制是否启用该步骤
rating_gen: 评分算法,可通过enable参数控制是否启用该步骤,注意该步骤依赖review_file必须存在
2. 执行脚本
# 示例:
python evalscope/run_arena.py --c registry/config/cfg_pairwise_baseline.yaml
数据集列表
| 数据集名称 | 链接 | 状态 | 备注 |
|---|---|---|---|
mmlu | mmlu | 活跃 | |
ceval | ceval | 活跃 | |
gsm8k | gsm8k | 活跃 | |
arc | arc | 活跃 | |
hellaswag | hellaswag | 活跃 | |
truthful_qa | truthful_qa | 活跃 | |
competition_math | competition_math | 活跃 | |
humaneval | humaneval | 活跃 | |
bbh | bbh | 活跃 | |
race | race | 活跃 | |
trivia_qa | trivia_qa | 待整合 |
排行榜
LLM排行榜旨在为研究人员和开发者提供一个客观全面的评估标准和平台,帮助他们了解和比较模型在ModelScope上各种任务中的表现。
参考:排行榜
实验和结果
参考:实验
模型服务性能评估
参考:性能
待办事项
- 代理评估
- vLLM
- 分布式评估
- 多模态评估
- 基准测试
- GAIA
- GPQA
- MBPP
- 自动审核员
- Qwen-max











