EVF-SAM:视觉与语言的早期融合
EVF-SAM(Early Vision-Language Fusion for Text-Prompted Segment Anything Model)是由华中科技大学和vivo AI实验室联合开发的一种创新计算机视觉模型。它通过在早期阶段融合视觉和语言信息,实现了高效精确的文本引导图像分割。EVF-SAM的提出标志着计算机视觉领域的一个重要进展,为多模态图像理解开辟了新的方向。
EVF-SAM的核心理念
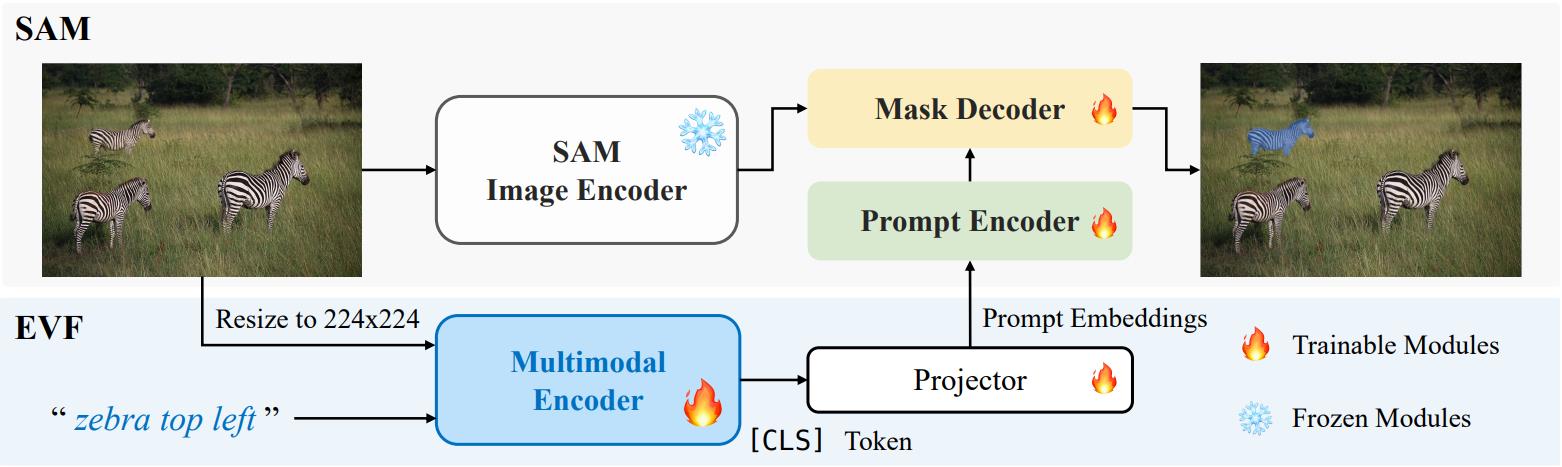
EVF-SAM的核心理念是在模型的早期阶段就融合视觉和语言信息。这种方法与传统的后期融合方法不同,能够更好地捕捉图像和文本之间的语义关联。具体来说,EVF-SAM在SAM(Segment Anything Model)的基础上进行了扩展,使其能够处理文本提示,从而实现更灵活和精确的图像分割。
EVF-SAM的主要特点
-
高精度文本引导分割: EVF-SAM在指代表达分割任务中展现出了卓越的性能,能够准确地根据文本描述定位和分割图像中的目标对象。
-
计算效率高: 模型设计注重计算效率,在T4 GPU上每张图片只需几秒钟就能完成推理。
-
灵活的应用范围: 不仅适用于图像分割,还可以进行视频预测,展现了很强的泛化能力。
-
零样本能力: 通过简单的图像训练过程,EVF-SAM展现出了零样本视频文本引导分割的能力。
EVF-SAM的工作原理
EVF-SAM的工作流程主要包括以下几个步骤:
-
输入处理: 模型接受图像和文本描述作为输入。
-
特征提取: 使用先进的视觉编码器(如SAM-2-L)和语言模型(如BEIT-3-L)分别提取图像和文本的特征。
-
早期特征融合: 在模型的早期阶段,将提取的视觉和语言特征进行融合。
-
分割生成: 基于融合后的特征,模型生成精确的分割掩码。
-
后处理: 对生成的分割结果进行必要的后处理,以提高分割的精度和视觉效果。
EVF-SAM的应用示例
EVF-SAM在各种复杂场景下都表现出色。以下是一些应用示例:
-
定位特定对象:
- 输入: "zebra top left"
- 结果: 模型准确定位并分割了图像左上角的斑马。
-
识别复杂描述:
- 输入: "a pizza with a yellow sign on top of it"
- 结果: 模型成功识别并分割出带有黄色标志的披萨。
-
理解相对位置:
- 输入: "the broccoli closest to the ketchup bottle"
- 结果: 模型正确识别出最靠近番茄酱瓶的西兰花。
-
识别动态场景:
- 输入: "bus going to south common"
- 结果: 模型能够准确分割出正在行驶的特定公交车。
-
处理复杂描述:
- 输入: "3carrots in center with ice and green leaves"
- 结果: 模型成功分割出中央的三根胡萝卜,包括周围的冰和绿叶。
这些例子展示了EVF-SAM在处理各种复杂文本描述和图像场景时的强大能力。
EVF-SAM的技术细节
EVF-SAM的技术实现涉及多个先进的深度学习组件:
-
视觉编码器: 使用SAM-2-L或SAM-H等先进的视觉模型。
-
语言编码器: 采用BEIT-3-L等强大的语言模型。
-
参数规模: 根据不同配置,模型参数从232M到1.32B不等。
-
训练策略: 采用了冻结和微调相结合的策略,以平衡性能和计算效率。
EVF-SAM的安装和使用
要使用EVF-SAM,需要按照以下步骤进行安装和配置:
- 克隆项目仓库
- 安装PyTorch(版本要求: >=2.0.0)
- 安装依赖:
pip install -r requirements.txt - 对于视频预测功能,需要额外编译某些组件
使用示例:
python inference.py \
--version YxZhang/evf-sam2 \
--precision='fp16' \
--vis_save_path "vis" \
--model_type sam2 \
--image_path "assets/zebra.jpg" \
--prompt "zebra top left"
EVF-SAM的未来发展
EVF-SAM的出现为计算机视觉和自然语言处理的结合开辟了新的可能性。未来的研究方向可能包括:
-
提高模型效率: 进一步优化模型结构,减少计算资源需求。
-
扩展应用场景: 探索在医疗影像、遥感图像等专业领域的应用。
-
增强交互能力: 开发更自然的人机交互界面,使非专业用户也能轻松使用。
-
多模态融合: 整合更多类型的输入,如音频、传感器数据等。
-
实时处理: 优化模型以支持实时视频流的处理。
结论
EVF-SAM代表了计算机视觉和自然语言处理交叉领域的最新进展。它不仅在技术上实现了突破,还为实际应用提供了强大的工具。随着技术的不断发展和完善,我们可以期待看到EVF-SAM在更多领域发挥重要作用,推动人工智能技术向着更智能、更自然的方向发展。
🔗 相关链接:
通过不断的创新和优化,EVF-SAM正在为计算机视觉领域带来新的可能性,我们期待看到它在未来更广泛的应用和发展。









