
 Github
Github Huggingface
Huggingface 论文
论文
📷 EVF-SAM
用于文本提示分割任意物体模型的早期视觉语言融合
张宇轩1,*, 程天恒1,*, 刘磊2, 刘恒2, 冉龙进2, 陈晓鑫2, 刘文预1, 王兴刚1,📧
1 华中科技大学, 2 vivo AI 实验室
(* 贡献相同, 📧 通讯作者)
新闻
我们已将EVF-SAM扩展到强大的SAM-2。除了在图像预测方面的改进外,我们的新模型在视频预测方面(由SAM-2驱动)也表现出色。仅仅通过在RES数据集上进行简单的图像训练过程,我们发现我们的EVF-SAM具有零样本视频文本提示能力。试试我们的代码吧!
亮点
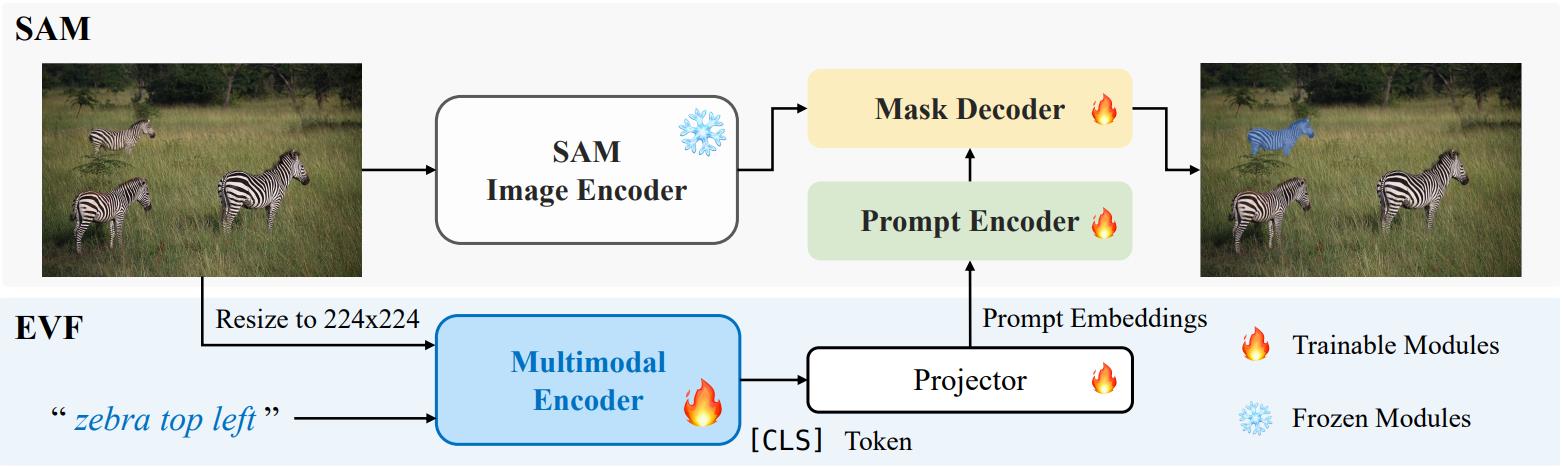
- EVF-SAM通过文本提示分割扩展了SAM的功能,在指代表达分割任务中实现了高准确率。
- EVF-SAM设计用于高效计算,能够在T4 GPU上实现每张图像几秒钟的快速推理。
更新
- 发布代码
- 发布权重
- 发布演示 👉 🤗 HuggingFace演示
- 发布基于SAM-2的代码和权重
- 更新支持SAM-2的演示
可视化
| 输入文本 | 输入图像 | 输出 |
| "左上角的斑马" |  |  |
| "上面有黄色标志的披萨" |  |  |
| "最靠近番茄酱瓶的西兰花" |  |  |
| "开往南部公共区域的公交车" |  |  |
| "中间3根带冰和绿叶的胡萝卜" |  |  |
安装
- 克隆此仓库
- 根据你的CUDA版本安装pytorch。注意,如果你要使用SAM-2,需要torch>=2.0.0,如果你想启用flash-attention,需要torch>=2.2。(我们使用torch==2.0.1和CUDA 11.7,运行良好。)
- pip install -r requirements.txt
- 如果你要使用视频预测功能,请运行:
cd model/segment_anything_2
python setup.py build_ext --inplace
权重
| 名称 | SAM | BEIT-3 | 参数 | 提示编码器 & 掩码解码器 | 参考分数 |
| EVF-SAM2 | SAM-2-L | BEIT-3-L | 898M | 冻结 | 83.6 |
| EVF-SAM | SAM-H | BEIT-3-L | 1.32B | 训练 | 83.7 |
| EVF-Effi-SAM-L | EfficientSAM-S | BEIT-3-L | 700M | 训练 | 83.5 |
| EVF-Effi-SAM-B | EfficientSAM-T | BEIT-3-B | 232M | 训练 | 80.0 |
推理
1. 图像预测
python inference.py \
--version <evf-sam路径> \
--precision='fp16' \
--vis_save_path "<输出目录路径>" \
--model_type <"ori" 或 "effi" 或 "sam2", 取决于你加载的检查点> \
--image_path <输入图像路径> \
--prompt <自定义文本提示>
--load_in_8bit 和 --load_in_4bit 是可选的
例如:
python inference.py \
--version evf-sam2 \
--precision='fp16' \
--vis_save_path "vis" \
--model_type sam2 \
--image_path "assets/zebra.jpg" \
--prompt "左上方的斑马"
2. 视频预测
首先将视频切分为帧
ffmpeg -i <你的视频>.mp4 -q:v 2 -start_number 0 <帧目录>/'%05d.jpg'
然后:
python inference_video.py \
--version <evf-sam2路径> \
--precision='fp16' \
--vis_save_path "vis/" \
--image_path <帧目录> \
--prompt <自定义文本提示> \
--model_type sam2
你可以使用frame2video.py将预测的帧连接成视频。
演示
图像演示
python demo.py <evf-sam路径>
视频演示
python demo_video.py <evf-sam2路径>
数据准备
指代分割数据集:refCOCO、refCOCO+、refCOCOg、refCLEF(saiapr_tc-12)和COCO2014train
├── dataset
│ ├── refer_seg
│ │ ├── images
│ │ | ├── saiapr_tc-12
│ │ | └── mscoco
│ │ | └── images
│ │ | └── train2014
│ │ ├── refclef
│ │ ├── refcoco
│ │ ├── refcoco+
│ │ └── refcocog
评估
torchrun --standalone --nproc_per_node <GPU数量> eval.py \
--version <evf-sam路径> \
--dataset_dir <数据根目录路径> \
--val_dataset "refcoco|unc|val" \
--model_type <"ori" 或 "effi" 或 "sam2", 取决于你加载的检查点>
致谢
我们借鉴了LISA、unilm、SAM、EfficientSAM、SAM-2的部分代码。
引用
@article{zhang2024evfsamearlyvisionlanguagefusion,
title={EVF-SAM: Early Vision-Language Fusion for Text-Prompted Segment Anything Model},
author={Yuxuan Zhang and Tianheng Cheng and Rui Hu and Lei Liu and Heng Liu and Longjin Ran and Xiaoxin Chen and Wenyu Liu and Xinggang Wang},
year={2024},
eprint={2406.20076},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2406.20076},
}











