
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文 GPT-4V的集合标记视觉提示
GPT-4V的集合标记视觉提示
:grapes: [阅读我们的arXiv论文] :apple: [项目主页]
杨建伟*⚑, 张浩*, 李峰*, 邹雪燕*, 李春远, 高剑峰
* 核心贡献者 ⚑ 项目负责人
简介
我们提出了集合标记(SoM)提示,只需在图像上覆盖一些空间和可说出的标记,就能释放最强大的大型语言模型——GPT-4V的视觉定位能力。让我们用视觉提示来实现视觉任务吧!
GPT-4V + SoM 演示
https://github.com/microsoft/SoM/assets/3894247/8f827871-7ebd-4a5e-bef5-861516c4427b
🔥 新闻
- [04/25] 我们发布了SoM-LLaVA,这是一个新数据集,可以为开源多模态大语言模型赋予SoM提示能力。快来看看!SoM-LLaVA
- [11/21] 感谢Roboflow和@SkalskiP,一个huggingface演示的SoM + GPT-4V已上线!快来试试吧!
- [11/07] 我们发布了用于评估带SoM提示的GPT-4V的视觉基准测试!查看基准页面!
- [11/07] 现在GPT-4V API已经发布,我们正在发布一个将SoM集成到GPT-4V的演示!
export OPENAI_API_KEY=YOUR_API_KEY
python demo_gpt4v_som.py
- [10/23] 我们发布了SoM工具箱代码,用于为GPT-4V生成集合标记提示。快来试试吧!
🔗 有趣的应用
SoM在GPT-4V中的有趣应用:
- [2023/11/13] 通过集合标记提示增强的智能手机GUI导航
- [2023/11/05] 使用GPT-4V和SoM提示进行零样本异常检测
- [2023/10/21] 受集合标记提示启发的Web UI导航代理
- [2023/10/20] 由Roboflow的@SkalskiP重新实现的集合标记提示
🔗 相关工作
我们的方法编译了以下模型来生成一组标记:
- Mask DINO:最先进的封闭集图像分割模型
- OpenSeeD:最先进的开放词汇图像分割模型
- GroundingDINO:最先进的开放词汇目标检测模型
- SEEM:多功能、可提示、交互式和语义感知的分割模型
- Semantic-SAM:以任何粒度分割和识别任何物体
- Segment Anything:分割任何物体
我们站在巨人GPT-4V的肩膀上(playground)!
:rocket: 快速开始
- 安装分割包
# 安装SEEM
pip install git+https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once.git@package
# 安装SAM
pip install git+https://github.com/facebookresearch/segment-anything.git
# 安装Semantic-SAM
pip install git+https://github.com/UX-Decoder/Semantic-SAM.git@package
# 为Semantic-SAM安装可变形卷积
cd ops && sh make.sh && cd ..
# 常见错误修复:
python -m pip install 'git+https://github.com/MaureenZOU/detectron2-xyz.git'
- 下载预训练模型
sh download_ckpt.sh
- 运行演示
python demo_som.py
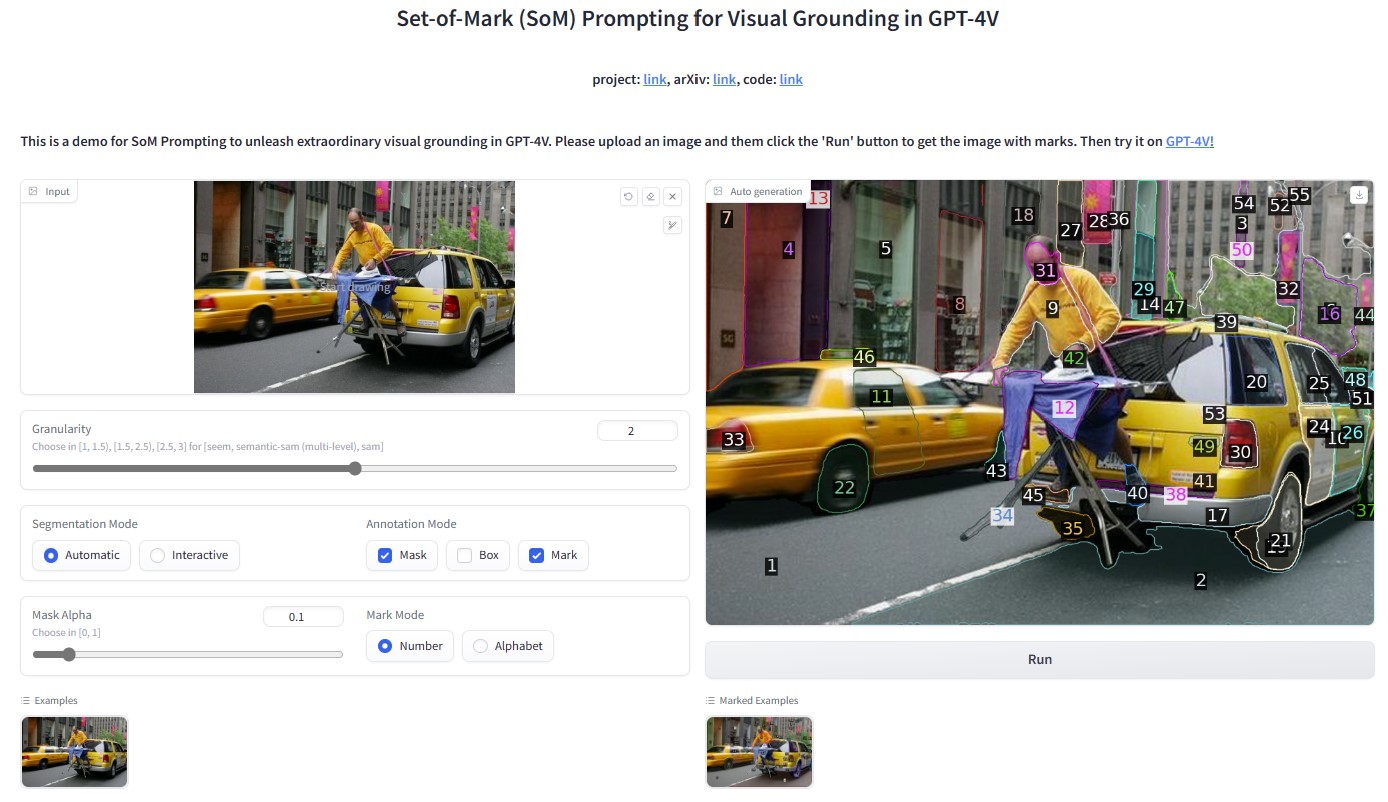
你将看到这个界面:
部署到AWS
通过Github Actions将SoM部署到AWS的EC2:
- Fork这个仓库并将你的fork克隆到本地机器。
- 按照
deploy.py顶部的说明操作。
:point_right: 比较标准GPT-4V和它与SoM提示的组合
:round_pushpin: 用于图像分割的SoM工具箱
用户可以选择生成哪种粒度的掩码,以及在自动(上)和交互(下)模式之间选择。为了更好的可视化效果,使用了更高的alpha混合值(0.4)。
:unicorn: 交错提示
SoM支持包含文本和视觉内容的交错提示。视觉内容可以使用区域索引表示。
:medal_military: SoM中使用的标记类型
:volcano: 评估任务示例
用例
:tulip: 基于图像的推理和跨图像引用
与不使用SoM的GPT-4V相比,添加标记使GPT-4V能够基于图像的详细内容进行推理(左图)。在右图中可以观察到清晰的跨图像对象引用。
:camping: 问题解决
解决验证码的案例研究。GPT-4V在没有正确数量的方块时给出了错误答案,而在使用SoM提示后,它能找到正确的方块并对应相应的标记。
:mountain_snow: 知识共享
对GPT-4V进行菜品图像的案例研究。GPT-4V无法为原始图像提供基于事实的答案。基于SoM提示,GPT-4V不仅能说出食材,还能将它们与图像中的区域对应起来。
:mosque: 个性化建议
使用SoM提示的GPT-4V能给出非常精确的建议,而原始版本则失败了,甚至出现了幻觉食物,如软饮料。
:blossom: 工具使用说明
:sunflower: 2D游戏规划
使用SoM的GPT-4V在游戏场景中给出了合理的建议,说明如何达成目标。
:mosque: 模拟导航
:deciduous_tree: 结果
我们在各种视觉任务上进行实验,验证了SoM的有效性。结果表明,GPT4V+SoM在大多数视觉任务上优于专家系统,并在COCO全景分割任务上与MaskDINO相当。
:black_nib: 引用
如果您发现我们的工作对您的研究有帮助,请考虑引用以下BibTeX条目。
@article{yang2023setofmark,
title={Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V},
author={Jianwei Yang and Hao Zhang and Feng Li and Xueyan Zou and Chunyuan Li and Jianfeng Gao},
journal={arXiv preprint arXiv:2310.11441},
year={2023},
}











