
Feast简介
Feast(Feature Store)是一个开源的特征存储平台,专为机器学习而设计。它的主要目标是帮助数据科学家和机器学习工程师更高效地管理和使用特征数据,从而加速机器学习模型的开发和部署过程。Feast提供了一套完整的工具和框架,用于定义、存储、管理和服务特征数据,使团队能够在训练和推理过程中一致地访问特征。
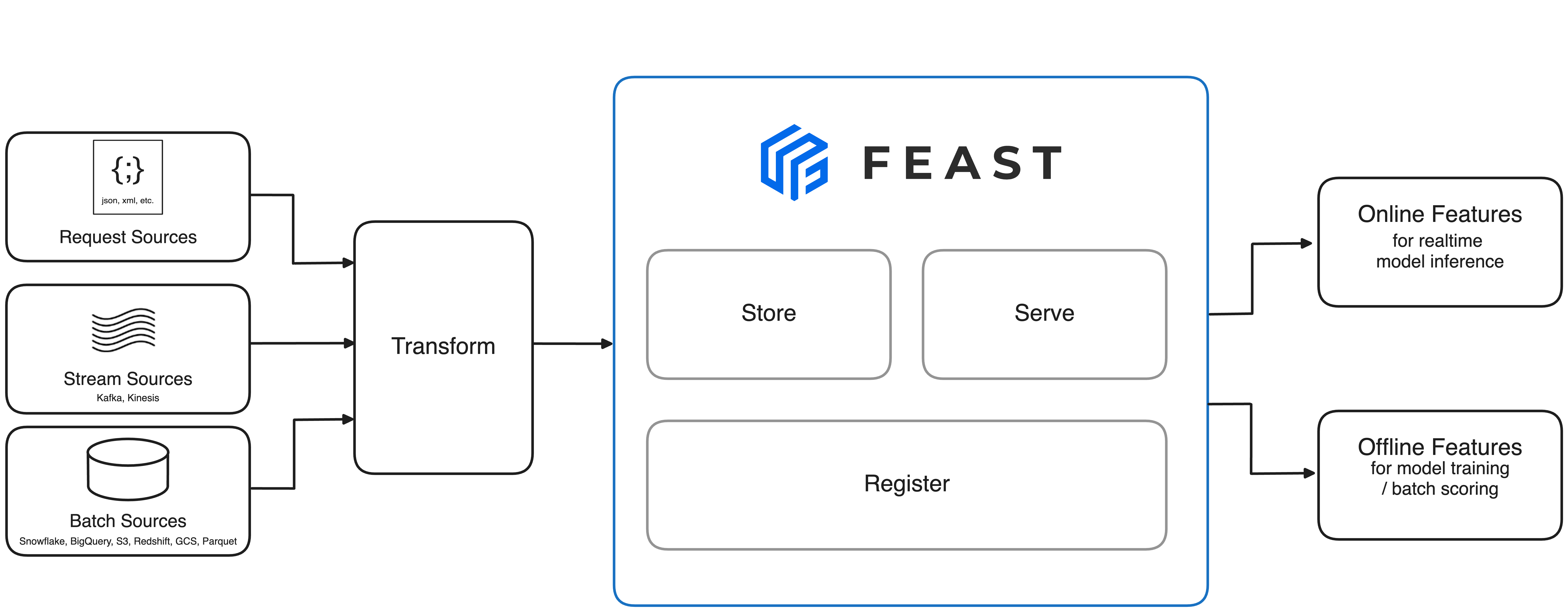
Feast的核心功能
1. 特征定义和管理
Feast允许用户通过Python API或YAML文件定义特征。用户可以指定特征的名称、类型、数据源等元数据信息。这些定义被存储在一个中央注册表中,方便团队成员查看和重用。
2. 离线存储
Feast支持多种离线存储选项,如Snowflake、BigQuery、Redshift等。这些存储用于处理大规模的历史数据,支持批量评分和模型训练。
3. 在线存储
为了支持低延迟的实时预测,Feast提供了多种在线存储选项,如Redis、DynamoDB、Bigtable等。这些存储可以快速服务预计算的特征值。
4. 特征服务
Feast提供了Python、Java和Go版本的特征服务器,可以快速检索在线特征。这使得实时预测变得简单高效。
5. 点击时间正确性
Feast确保在生成训练数据集时不会出现数据泄露,通过生成点击时间正确的特征集来实现这一点。
6. 数据源集成
Feast支持多种数据源,包括批处理源(如Parquet文件、SQL数据库)和流式源(如Kafka)。这种灵活性使得Feast可以适应各种数据基础设施。
Feast的优势
-
一致性: Feast确保在模型训练和在线推理过程中使用相同的特征定义和转换逻辑,减少了模型在生产环境中的不一致性。
-
可重用性: 通过中央化的特征定义,团队成员可以轻松地重用和共享特征,提高了工作效率。
-
可扩展性: Feast的架构设计支持大规模数据处理和服务,可以随着机器学习项目的增长而扩展。
-
灵活性: 支持多种存储后端和数据源,可以适应不同的技术栈和基础设施需求。
-
开源生态: 作为一个活跃的开源项目,Feast拥有庞大的社区支持和持续的功能更新。
如何开始使用Feast
1. 安装Feast
首先,通过pip安装Feast:
pip install feast
2. 创建特征仓库
使用以下命令初始化一个新的特征仓库:
feast init my_feature_repo
cd my_feature_repo/feature_repo
3. 定义特征
编辑example_repo.py文件,定义你的数据源和特征视图:
from feast import Entity, Feature, FeatureView, FileSource, ValueType
# 定义数据源
driver_hourly_stats = FileSource(
path="/path/to/driver_stats.parquet",
event_timestamp_column="event_timestamp",
created_timestamp_column="created",
)
# 定义实体
driver = Entity(name="driver_id", value_type=ValueType.INT64, description="driver id")
# 定义特征视图
driver_hourly_stats_view = FeatureView(
name="driver_hourly_stats",
entities=["driver_id"],
ttl=timedelta(seconds=86400 * 1),
features=[
Feature(name="conv_rate", dtype=ValueType.FLOAT),
Feature(name="acc_rate", dtype=ValueType.FLOAT),
Feature(name="avg_daily_trips", dtype=ValueType.INT64),
],
online=True,
batch_source=driver_hourly_stats,
tags={},
)
4. 应用特征定义
运行以下命令应用特征定义:
feast apply
5. 加载特征数据到在线存储
使用以下命令将特征数据加载到在线存储:
CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
feast materialize-incremental $CURRENT_TIME
6. 检索在线特征
现在你可以使用Feast SDK检索在线特征:
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(
features=[
'driver_hourly_stats:conv_rate',
'driver_hourly_stats:acc_rate',
'driver_hourly_stats:avg_daily_trips'
],
entity_rows=[{"driver_id": 1001}]
).to_dict()
print(feature_vector)
Feast的未来发展
Feast正在不断发展和改进,未来的发展方向包括:
-
增强特征工程能力: 计划增加更多的在线和离线特征转换功能。
-
改进流式处理: 增强对实时数据流的支持,提供更灵活的流式特征更新机制。
-
扩展数据质量管理: 集成更多的数据验证和监控工具,确保特征数据的质量。
-
增强特征发现和治理: 改进特征注册表,提供更好的搜索和元数据管理功能。
-
云原生部署: 提供更多云原生部署选项,简化在各种云平台上的安装和管理。
结论
Feast作为一个强大的开源特征存储平台,正在改变机器学习团队管理和使用特征数据的方式。通过提供一致的特征定义、存储和服务机制,Feast帮助团队提高了工作效率,减少了错误,加速了机器学习模型从开发到部署的整个生命周期。随着机器学习在各个行业的应用不断深入,Feast这样的工具将在构建可扩展、可维护的机器学习系统中发挥越来越重要的作用。
无论你是刚开始探索机器学习,还是正在寻求优化现有ML流程,Feast都值得一试。它不仅可以帮助你更好地组织和管理特征数据,还能为你的团队提供一个统一的特征管理平台,促进协作和知识共享。随着Feast的不断发展和社区的持续贡献,我们可以期待看到更多创新功能和改进,进一步推动机器学习工程的发展。
如果你想了解更多关于Feast的信息或参与到项目中来,可以访问Feast的GitHub仓库或官方文档。加入Feast的社区,你将有机会与其他数据科学家和ML工程师交流,分享经验,共同推动特征存储技术的发展。让我们一起探索Feast,为机器学习项目带来更高的效率和更好的结果! 🚀









