
FlagData:助力AI发展的数据处理利器
在人工智能快速发展的今天,高质量的数据已成为模型训练和部署的关键要素。为了满足这一需求,FlagData应运而生。这款由FlagOpen开发的开源数据处理工具包,为自然语言处理、计算机视觉等领域的模型训练提供了强大的数据层面支持。
全面的数据处理功能
FlagData的功能覆盖了数据处理的全流程:
-
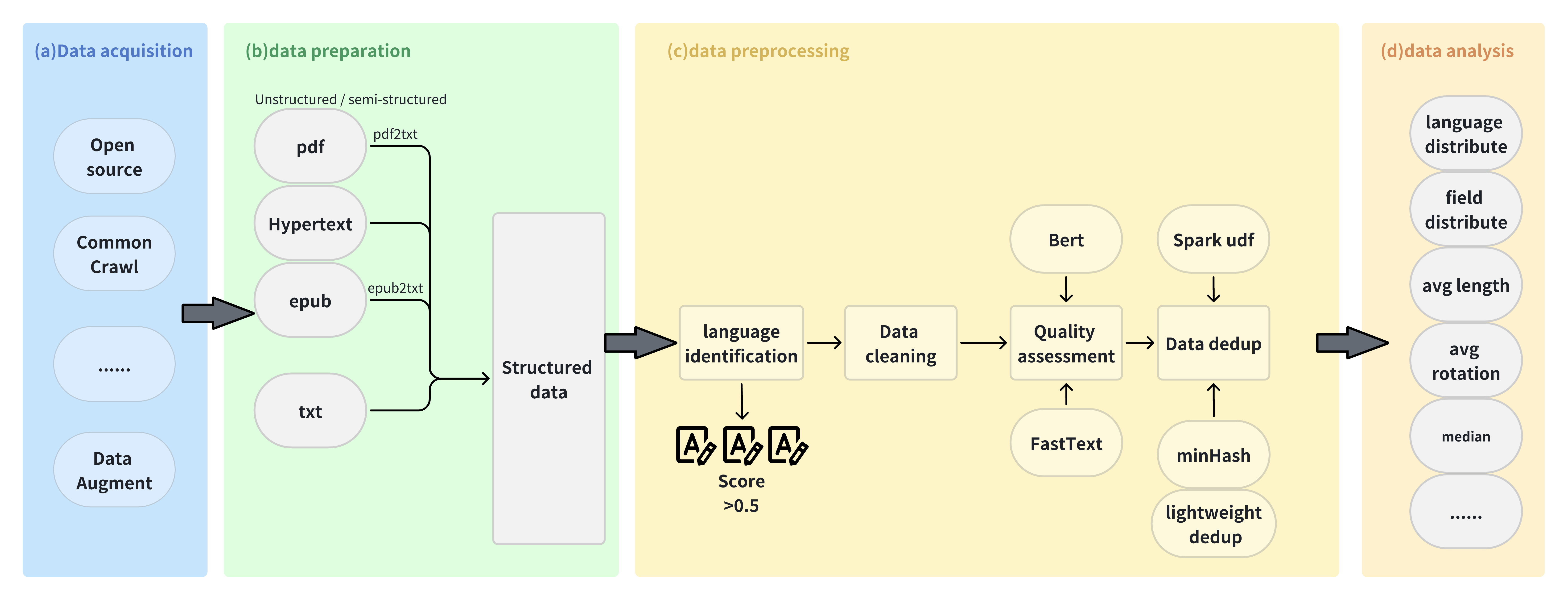
数据获取:利用大语言模型接口,FlagData能够生成多种能力的单轮对话数据。它支持三种策略:模仿生成、能力提取生成和能力直接生成,可以灵活地创建各类训练样本。
-
数据准备:FlagData的all2txt模块可以将PDF、EPUB等非结构化或半结构化文件转换为TXT格式。它能很好地处理单双栏混排、图表穿插等复杂排版问题,保证转换后的文本内容连贯清晰。
-
数据预处理:
- 语言识别:使用fastText的语言分类器,支持176种语言的分类。
- 数据清洗:提供多种清洗工具,如TextCleaner、ArxivCleaner、HtmlCleaner等,可满足不同类型数据的清洗需求。
- 质量评估:采用BERT和FastText模型进行文本质量评估。
- 数据去重:使用MinHashLSH算法进行大规模文本数据的去重。
-
数据分析:FlagData的分析模块可以进行文本平均回合分析、领域分布分析、语言分布分析以及文本长度分析等。
易用性和灵活性并重
FlagData不仅功能强大,还注重用户体验:
-
一键式操作:对于新手用户,只需确认数据类型,即可生成高质量数据。
-
高度可定制:对于高级用户,FlagData提供了数十种算子池,允许用户自定义数据构建流程。
-
多数据类型支持:支持HTML、Web、Wiki、Book、Paper、QA、Redpajama、Code等多种数据类型。
-
配置灵活:通过YAML格式的配置文件,用户可以轻松调整数据清洗和质量评估的参数。
分布式处理能力
FlagData集成了Spark分布式计算框架,能够高效处理海量数据。特别是在数据去重环节,FlagData利用Spark的MapReduce思想,显著提升了大规模文本数据集的处理效率。
开源社区支持
作为一个开源项目,FlagData得到了活跃社区的支持:
-
用户可以通过GitHub Issues提出问题和建议,项目维护者承诺24小时内快速响应。
-
定期举办线上线下交流活动,分享最新的大语言模型研究成果。
-
欢迎社区贡献,共同推动项目发展。

广泛的应用
FlagData已在多个知名企业和机构中得到应用,包括华为、小米、OPPO、vivo等。这些用户的实践证明了FlagData在实际场景中的价值和效果。

未来展望
随着v3.0.0版本的发布,FlagData进一步完善了其功能,提供了更加傻瓜式的语言预训练数据构建工具。未来,FlagData团队将继续致力于:
- 增强数据处理的智能化程度
- 扩展支持更多数据类型和处理算法
- 优化分布式处理性能
- 加强与主流AI框架的集成
结语
在大模型时代,高质量的数据处理工具愈发重要。FlagData作为一款全面、灵活、高效的数据处理工具包,正在为AI的发展贡献重要力量。无论您是AI研究人员、数据科学家,还是企业开发者,FlagData都能为您的工作提供有力支持。欢迎访问FlagData GitHub仓库,体验这款强大的数据处理利器,共同推动AI技术的进步!









