
 访问官网
访问官网 Github
Github Huggingface
Huggingface



数据是人工智能发展的基本要素之一。随着大规模预训练模型和相关技术的不断突破,在相应研究中使用高效的数据处理工具来提高数据质量变得越来越重要。因此,我们推出了FlagData,这是一个易用且易于扩展的数据处理工具包。FlagData集成了包括数据获取、数据准备、数据预处理和数据分析在内的多种数据处理工具和算法,为自然语言处理、计算机视觉等领域的模型训练和部署提供了强有力的数据层面支持。
FlagData支持以下功能:
-
实现各种原始格式数据的高质量内容提取,大大降低处理成本。
-
为大型模型提供数据微调视角的功能。
-
一站式高效分布式数据处理功能。
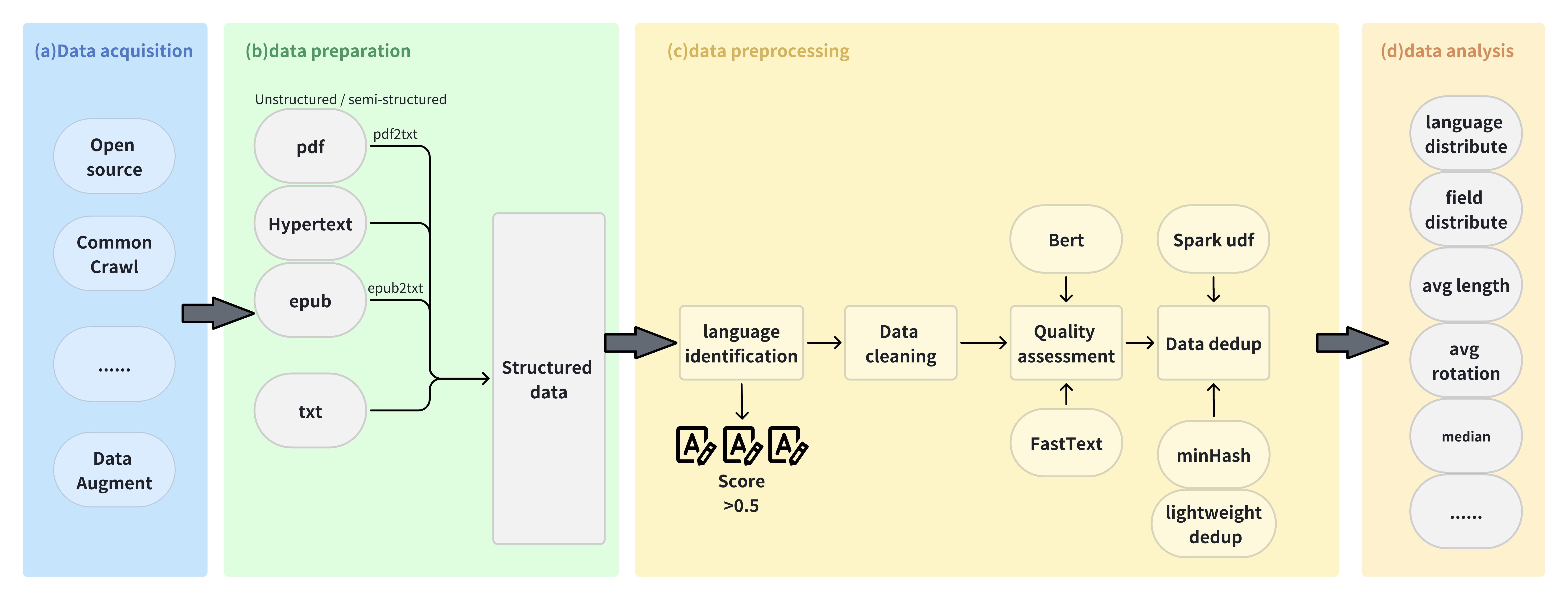
完整的流程和功能如下图所示:
新闻
- [2024年6月13日] FlagData v3.0.0更新,支持多种数据类型,提供数十个可自定义的算子池,一键生成高质量数据
- [2023年12月31日] FlagData v2.0.0已升级
- [2023年1月31日] FlagData v1.0.0上线!
V3.0.0 更新
根据社区反馈,FlagData已进行升级。此次更新提供了一套傻瓜式语言预训练数据构建工具。根据不同的数据类型,我们提供了Html、Text、Book、Arxiv、Qa等一键式数据质量提升任务。无论是新手用户还是高级用户都可以轻松生成高质量数据。
- 新手用户:只需确认数据类型即可生成高质量数据。
- 高级用户:我们提供数十个算子池,供用户自定义LLM预训练数据构建过程。
项目特点:
- 易用性:傻瓜式操作,只需简单配置即可生成高质量数据。
- 灵活性:高级用户可通过各种算子池自定义数据构建过程。
- 多样性:支持多种数据类型(HTML、Web、Wiki、Book、Paper、QA、Redpajama、Code)
主要亮点
- 🚀 一键生成高质量数据
- 🔧 数十个可自定义的算子池
- 🌐 支持多种数据类型
安装
- requirements.txt文件下,是FlagData项目的所有依赖包
pip install -r requirements.txt
安装主分支的最新版本
主分支是FlagData官方发布的版本。如果你想安装/更新到主分支的最新版本,使用以下命令:
git clone https://github.com/FlagOpen/FlagData.git
快速开始
数据获取阶段
利用LLM接口,通过三种不同的策略构建一系列针对不同能力的单轮SFT数据。策略包括:
- ImitateGenerator:使用几个案例样本作为模板来增强数据。支持同时生成多种语言的数据。
- AbilityExtractionGenerator:使用LLM接口,概括几个案例样本中包含的能力。基于这个能力集合生成新的样本和答案。
- AbilityDirectGenerator:直接生成与指定能力类型或任务类型相关的新样本。例如,如果你指定能力为"逻辑推理",就可以生成一系列逻辑推理问题和答案。为了增加生成样本的多样性,支持排除已生成的样本。
参见数据增强模块使用说明获取示例。
数据准备阶段
在all2txt模块下,可以将pdf2txt和epub2txt等非结构化/半结构化文件转换为txt,并能很好地解决单栏、双栏、中文文本与图表交错等导致的文本内容不连贯问题。
同时,解析后的元素类型有"Table"、"FigureCaption"、"NarrativeText"、"ListItem"、"Title [Chapter Title]"、"Address [E-mail]"、"PageBreak"、"Header [Header]"、"Footer [Footer]"、"UncategorizedText [arxiv vertical number]"、"Image、Formula等。工具脚本提供了保留全文和按类别解析保存两种形式。
参见all2txt模块使用说明获取示例。
数据预处理阶段
语言识别
在language_identification模块下,使用fastText的语言分类器进行分类。fastText的语言分类器基于维基百科、Tatoeba和SETimes进行训练。 上述训练使用n-gram作为特征,并使用分层softmax。支持176种语言分类,最终输出0到1之间的分数。
- 每个CPU核心每秒可以处理上千个文档。
- 对每个网页进行语言分类并获得分类分数。
- 对于一般清洗规则,如果分数大于0.5,则归类为特定语言,否则表示无法确定页面语言并丢弃该页面。
有关示例,请参阅语言识别模块使用说明。
数据清洗
我们提供Html、Text、Book、Arxiv、Qa等一键式数据质量提升任务。对于更多自定义功能,用户可以参考"data_operator"部分。
TextCleaner
TextCleaner提供快速且可扩展的文本数据清洗工具。它提供常用的文本清洗模块。 用户只需在cleaner_builder.py中选择text_clean.yaml文件即可处理文本数据。 详情请参阅TextCleaner使用说明
ArxivCleaner
ArxivCleaner提供常用的arxiv文本数据清洗工具。 用户只需在cleaner_builder.py中选择arxiv_clean.yaml文件即可处理arxiv数据。
HtmlCleaner
HtmlCleaner提供常用的Html格式文本提取和数据清洗工具。 用户只需运行main方法即可处理arxiv数据。
QaCleaner
QaCleaner提供常用的Qa格式文本提取和数据清洗工具。 用户只需运行main方法即可处理Qa数据。 详情请参阅Qa使用说明
BookCleaner
BookCleaner提供常用的书籍格式文本提取和数据清洗工具。 用户只需运行main方法即可处理书籍数据。 详情请参阅Book使用说明
质量评估
选择BERT和fasttext作为评估模型是因为它们具有以下优势:
- BERT模型在文本分类和理解任务中表现出色,具有强大的语言理解和表示能力,可以有效评估文本质量。
- FastText模型具有高效的训练和推理速度,同时保持分类性能,可以显著减少训练和推理时间。
本文比较了不同的文本分类模型,包括逻辑回归、BERT和FastText,以评估它们的性能。在实验中,BERTEval和FastText模型在文本分类任务中表现良好,FastText模型在准确率和召回率方面表现最佳。[实验结果来自ChineseWebText]
有关示例,请参阅质量评估模块使用说明。
数据去重
去重模块提供了大量文本数据去重的能力,使用MinHashLSH(局部敏感哈希的最小哈希)将文本转换为一系列哈希值,以比较文本之间的相似度。
我们可以控制参数threshold,它表示相似度阈值,取值范围为0到1。设置为1意味着完全匹配,不会过滤掉任何文本。相反,如果设置较低的相似度值,相似度稍高的文本也会被保留。我们可以根据需要设置较高的阈值,只保留非常相似的文本,同时丢弃相似度稍低的文本。经验默认值为0.87。同时,我们利用Spark的分布式计算能力处理大规模数据,采用MapReduce思想进行去重,并通过spark调优高效处理大规模文本数据集。
以下是数据去重过程中迭代的相似文本,在换行和名称编辑上有细微差异,但去重算法能够识别出两段高度相似的文本。
{
"__id__": 3023656977259,
"content": "\"2022海口三角梅花展\"已接待游客3万多名——\n三角梅富了边洋村\n一年四季,美丽的海南岛始终春意盎然、鲜花盛开,而作为海南省省花的三角梅就是其中最引人注目的鲜花品种之一,成为海南的一道亮丽风景线。\n\"可别小看这一盆盆普通的三角梅花,特别受游客喜爱。仅最近一个多月,我们就卖出了200多万元,盆栽三角梅销路火爆......吸引更多本地和外地游客来赏花、买花。(经济日报 记者 潘世鹏)\n(责任编辑:单晓冰)"
}
{
"__id__": 3934190045072,
"content": "记者 潘世鹏\n\"2022海口三角梅花展\"已接待游客3万多名——\n三角梅富了边洋村\n一年四季,美丽的海南岛始终春意盎然、鲜花盛开,而作为海南省省花的三角梅就是其中最引人注目的鲜花品种之一,成为海南的一道亮丽风景线。\n\"可别小看这一盆盆普通的三角梅花,特别受游客喜爱。仅最近一个多月,我们就卖出了200多万元,盆栽三角梅销路火爆。......吸引更多本地和外地游客来赏花、买花。(经济日报 记者 潘世鹏)"
}
spark单项能力集成: 大多数情况下,我们希望使用Spark的分布式数据处理能力。这里有一种方法可以将普通函数转换为Spark UDF函数,然后利用Spark的功能。
但对于想要转换为Spark任务的函数,需要满足以下条件:
- 数据并行性:函数的输入数据可以被分成多个部分并并行处理。
- 可序列化和不可变:Spark中的函数必须是可序列化的,以便在不同节点间传输。
- 不依赖特定计算节点:函数的执行不依赖于特定节点的计算资源或数据存储位置,以便可以在集群中的任何节点上执行。
- 无状态或可共享状态:函数不依赖外部状态或仅依赖可共享状态。这确保了在不同计算节点上并行执行函数时不会出现冲突或竞争条件。
使用UDF时,应考虑性能和优化。某些函数在本地Python环境中可能运行良好,但在分布式Spark环境中可能效率不高。 对于复杂的逻辑或需要大量内存的函数,可能需要进一步优化和考虑。UDF设计用于简单的逻辑和数据处理,对于更复杂的计算,可能需要使用Spark的原生算子进行处理。
去重模块提供了一个通用的Python函数(用于判断是否为其他字符串的子串)来使用Spark UDF重写,这使得使用Spark分布式功能变得容易。有关更多信息,请参见stringMatching.py和stringMatching.py。
如果用户简单地将Python函数更改为Spark任务,在没有Spark集群的情况下将无法工作。这里详细编写了构建集群的详细文档,方便新手用户使用。
有关示例,请参见Spark集群构建。
数据分析阶段
分析数据分析模块提供以下功能:
-
文本的平均回合分析代码,并计算平均回合数(以换行符为例)
-
文本的领域分布
-
文本的语言分布
-
文本的长度分析
有关示例,请参见分析模块使用说明。
配置
对于数据清洗和数据质量评估模块,
我们提供了配置文件模板:text_clean.yaml、arxiv_clean.yaml,bert_config.yaml。
配置文件采用可读的YAML格式,提供了详细的注释。在使用这些模块之前,请确保已在配置文件中修改了参数。
以下是一些你需要注意的重要参数:
数据清洗
# 待清洗的原始数据
input: ./demo/demo_input.jsonl
# 清洗后数据的保存路径
output: ./demo/output.jsonl
# 待处理的字段
source_key: text
# 输出文件中用于保存的键
result_key: cleanedContent
# 需要选择的Pipline类
cleaner_class: ArxivCleaner
数据质量评估
# 数据评估模型可以从[ChineseWebText下载](https://github.com/CASIA-LM/ChineseWebText)获取
pretrained_model_path: "models/bert-base-chinese"
checkpoint: "models/pretrain/2023-08-16-21-36/model-epoch_19-step_2999.pt"
# text_key字段是被评估的字段
text_key: "raw_content"
算子池
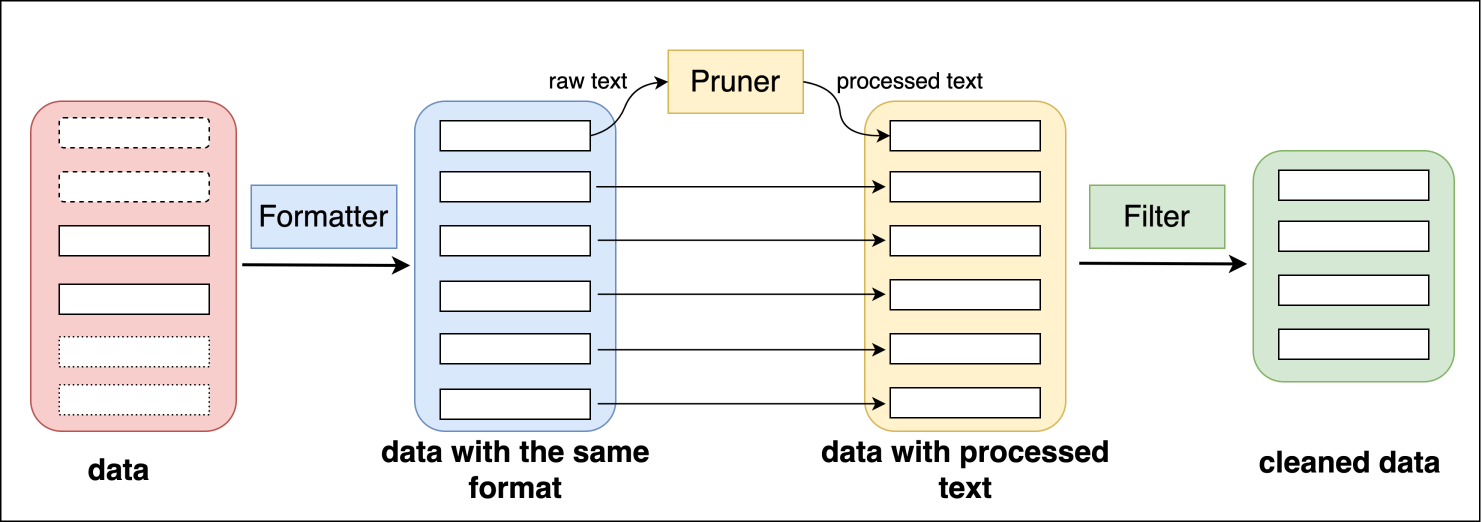
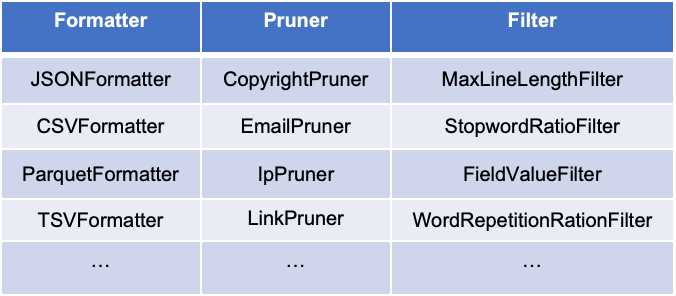
我们提供了一些基本的算子用于数据清洗、过滤、格式转换等,以帮助用户构建自己的数据构建流程。
提供的算子分为三类:Formatter、Pruner和Filter。Formatter用于处理结构化数据,可用于不同格式数据的相互转换;Pruner用于清洗文本数据;Filter用于样本过滤。 下图展示了这些算子在不同处理位置以及部分算子列表
详细说明请参见数据算子使用说明
强大的社区支持
社区支持
如果您对本项目的使用和代码有任何疑问,可以提交issue。您也可以直接通过邮箱data@baai.ac.cn与我们联系;
一个活跃的社区离不开您的贡献。如果您有新的想法,欢迎加入我们的社区,让我们成为开源的一部分,共同为开源做贡献!!!

或关注FlagOpen开源体系,FlagOpen官网 https://flagopen.baai.ac.cn/

问题与反馈
- 请通过GitHub Issues报告问题和提出建议,我们将在24小时内快速响应。
- 也欢迎在GitHub Discussions中积极讨论。
- 如果不方便使用GitHub,当然,FlagData开源社区中的每个人也可以畅所欲言。对于合理的建议,我们会在下一个版本中迭代。 我们将定期邀请领域专家举行线上和线下交流,分享最新的LLM研究成果。
用户

参考项目
本项目部分参考了以下代码: GeneralNewsExtractor, text-data-distillation, emoji, transformers, ChineseWebText, lid, unstructured, minHash。
许可证
FlagData项目基于Apache 2.0许可证。











