
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文
大规模转换数据集。 优化数据以加速AI模型训练。
转换 优化 ✅ 并行化数据处理 ✅ 流式传输大型云数据集 ✅ 创建向量嵌入 ✅ 将训练速度提高20倍 ✅ 运行分布式推理 ✅ 暂停和恢复数据流传输 ✅ 大规模抓取网站 ✅ 使用远程数据而无需本地加载




Lightning AI • 快速开始 • 优化数据 • 转换数据 • 主要特性 • 基准测试 • 模板 • 社区

大规模转换数据。优化以加速模型训练。
LitData可以在本地或云端机器上扩展数据处理任务(数据抓取、图像调整大小、分布式推理、嵌入创建)。它还能优化数据集以加速AI模型训练,并在不进行本地加载的情况下处理大型远程数据集。
快速开始
首先,安装LitData:
pip install litdata
选择您的工作流程:
高级安装
安装所有额外功能
pip install 'litdata[extras]'
加速模型训练
通过优化数据集以直接从云存储流式传输,加速模型训练(速度提高20倍)。无需本地下载即可处理远程数据,具备加载数据子集、访问单个样本和可恢复流式传输等功能。
第1步:优化数据 此步骤将格式化数据集以实现快速加载。数据将以分块二进制格式写入。
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
# 您可以使用任何键值对。请注意,它们的类型在样本之间不能改变,Python列表必须始终包含相同数量的相同类型的元素。
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
# optimize函数以优化格式写入数据。
ld.optimize(
fn=random_images, # 应用于每个输入的函数
inputs=list(range(1000)), # 函数的输入(这里是一个数字列表)
output_dir="my_optimized_dataset", # 优化后的数据存储在这里
num_workers=4, # 同一机器上的工作进程数
chunk_bytes="64MB" # 每个块的大小
)
第2步:将数据上传至云端
将数据上传到Lightning Studio(由S3支持)或您自己的S3存储桶:
aws s3 cp --recursive my_optimized_dataset s3://my-bucket/my_optimized_dataset
第3步:在训练期间流式传输数据
通过将PyTorch的DataSet和DataLoader替换为StreamingDataset和StreamingDataloader来加载数据
import litdata as ld
dataset = ld.StreamingDataset('s3://my-bucket/my_optimized_dataset', shuffle=True)
dataloader = ld.StreamingDataLoader(dataset)
for sample in dataloader:
img, cls = sample['image'], sample['class']
主要优势:
✅ 加速训练: 优化后的数据集加载速度提高20倍。
✅ 流式传输云数据集:无需下载即可处理云端数据。
✅ 以PyTorch为先: 与PyTorch Lightning、Lightning Fabric、Hugging Face等PyTorch库兼容。
✅ 便于协作: 在云端共享和访问数据集,简化团队项目。
✅ 跨GPU扩展: 流式传输的数据自动扩展到所有GPU。
✅ 灵活存储: 可使用S3、GCS、Azure或您自己的云账户存储数据。
✅ 压缩: 使用先进的压缩算法减少数据占用空间。
✅ 本地或云端运行: 可在自己的机器上运行,或通过Lightning Studios自动扩展到数千个云端GPU。
✅ 企业级安全: 可自行托管或在Lightning Studios上的云账户中处理数据。
转换数据集
通过在多台机器上并行化(映射)工作,加速数据处理任务(数据抓取、图像调整大小、嵌入创建、分布式推理)。
以下是一个调整大型图像数据集大小和裁剪的示例:
from PIL import Image
import litdata as ld
# 使用本地或S3文件夹
input_dir = "my_large_images" # 或 "s3://my-bucket/my_large_images"
output_dir = "my_resized_images" # 或 "s3://my-bucket/my_resized_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# 调整输入图像大小
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
ld.map(
fn=resize_image,
inputs=inputs,
output_dir="output_dir",
)
主要优势: ✅ 并行处理:通过在多台机器上同时转换数据来减少处理时间。 ✅ 扩展至大数据:增加您可以高效处理的数据集规模。 ✅ 灵活用例:调整图像大小、创建嵌入、抓取互联网等。 ✅ 本地或云端运行:在您自己的机器上运行,或通过Lightning Studios自动扩展至数千个云端GPU。 ✅ 企业级安全:使用Lightning Studios进行自托管或在您的云账户上处理数据。
主要特性
优化和流式处理数据集以用于模型训练的功能
✅ 流式处理大型云端数据集
✅ 多GPU、多节点流式处理
✅ 从多个云服务提供商进行流式处理
✅ 暂停、恢复数据流式处理
✅ 大语言模型预训练
import os
from litdata import StreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
# 因为我们还需要下一个词,所以增加1
dataset = StreamingDataset(
input_dir=f"./slimpajama-optimized/train",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
)
train_dataloader = StreamingDataLoader(dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# 遍历SlimPajama数据集
for batch in tqdm(train_dataloader):
pass
✅ 合并数据集
混合搭配不同的数据集以进行实验并创建更好的模型。
使用CombinedStreamingDataset合并数据集。例如,这种Slimpajama和StarCoder的混合在TinyLLAMA项目中被用来预训练一个1.1B的Llama模型,训练了3万亿个词元。
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
import os
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1), # LLM使用的优化词元加载器
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1), # LLM使用的优化词元加载器
shuffle=True,
drop_last=True,
),
]
# 按以下比例混合SlimPajama数据和Starcoder数据:
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights, iterate_over_all=False)
train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# 遍历合并后的数据集
for batch in tqdm(train_dataloader):
pass
✅ 将数据集分割为训练、验证、测试集
使用train_test_split将数据集分割为训练、验证、测试集。
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data") # 数据存储在云端
print(len(dataset)) # 显示数据的长度
# 输出: 100,000
train_dataset, val_dataset, test_dataset = train_test_split(dataset, splits=[0.3, 0.2, 0.5])
print(train_dataset)
# 输出: 30,000
print(val_dataset)
# 输出: 20,000
print(test_dataset)
# 输出: 50,000
✅ 加载远程数据集的子集
处理数据的一个较小、可管理的部分,以节省时间和资源。
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01) # 数据存储在云端
print(len(dataset)) # 显示数据的长度
# 输出: 1000
✅ 轻松修改优化后的云端数据集
向现有数据集添加新数据或在需要时重新开始,提供灵活的数据管理。
LitData优化后的数据集被假定为不可变的。但是,你可以通过将模式更改为append或overwrite来决定修改它们。
from litdata import optimize, StreamingDataset
def compress(index):
return index, index**2
if __name__ == "__main__":
# 添加一些数据
optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
)
# 稍后,你添加更多数据
optimize(
fn=compress,
inputs=list(range(100, 200)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
mode="append",
)
ds = StreamingDataset("./my_optimized_dataset")
assert len(ds) == 200
assert ds[:] == [(i, i**2) for i in range(200)]
overwrite模式将删除现有数据并重新开始。
✅ 使用压缩
通过使用高级压缩算法减少数据占用空间。
import litdata as ld
def compress(index):
return index, index**2
if __name__ == "__main__":
# 添加一些数据
ld.optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
num_workers=1,
compression="zstd"
)
使用zstd,你可以在这个简单示例中达到4.34倍的高压缩率。
| 不使用 | 使用 |
|---|---|
| 2.8kb | 646b |
✅ 无需完整下载数据即可访问样本
无需下载整个数据集或将其加载到本地机器上,即可查看大型数据集的特定部分。
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data") # 数据存储在云端
print(len(dataset)) # 显示数据的长度
print(dataset[42]) # 显示数据集的第42个元素
✅ 使用任何数据转换
自定义数据处理方式以更好地满足你的需求。
继承StreamingDataset并重写其__getitem__方法来添加任何额外的数据转换。
from litdata import StreamingDataset, StreamingDataLoader
import torchvision.transforms.v2.functional as F
class ImagenetStreamingDataset(StreamingDataset):
def __getitem__(self, index):
image = super().__getitem__(index)
return F.resize(image, (224, 224))
dataset = ImagenetStreamingDataset(...)
dataloader = StreamingDataLoader(dataset, batch_size=4)
for batch in dataloader:
print(batch.shape)
# 输出: (4, 3, 224, 224)
✅ 分析数据加载速度
测量并优化数据加载速度,提高效率。
StreamingDataLoader支持对数据加载过程进行分析。只需使用profile_batches参数指定要分析的批次数:
from litdata import StreamingDataset, StreamingDataLoader
StreamingDataLoader(..., profile_batches=5)
这将生成一个名为result.json的Chrome跟踪文件。然后,通过在Chrome浏览器中打开chrome://tracingURL并加载该跟踪文件来可视化这个跟踪。
✅ 减少大文件的内存使用
高效处理大型数据文件,不会过度占用计算机内存。
处理大型文件(如压缩的 parquet 文件)时,使用 Python 的 yield 关键字一次处理和存储一个项目,从而减少整个程序的内存占用。
from pathlib import Path
import pyarrow.parquet as pq
from litdata import optimize
from tokenizer import Tokenizer
from functools import partial
# 1. 定义一个函数,将 parquet 文件中的文本转换为标记
def tokenize_fn(filepath, tokenizer=None):
parquet_file = pq.ParquetFile(filepath)
# 按批次处理以减少内存使用
for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]):
for text in batch.to_pandas()["content"]:
yield tokenizer.encode(text, bos=False, eos=True)
# 2. 生成输入
input_dir = "/teamspace/s3_connections/tinyllama-template"
inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")]
# 3. 将优化后的数据存储在 "/teamspace/datasets" 或 "/teamspace/s3_connections" 下的任何位置
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # 注意:使用 HF tokenizer 或其他任何 tokenizer
inputs=inputs,
output_dir="/teamspace/datasets/starcoderdata",
chunk_size=(2049 * 8012), # 每个块存储的标记数。这大约是每个块 64MB 的标记。
)
✅ 限制本地缓存空间
限制临时文件使用的磁盘空间,防止存储问题。
调整 StreamingDataset 的本地缓存限制。这有助于确保下载的数据块在使用后被删除,并保持磁盘使用量较低。
from litdata import StreamingDataset
dataset = StreamingDataset(..., max_cache_size="10GB")
✅ 更改缓存目录路径
指定缓存文件应存储的目录,确保高效的数据检索和管理。这对于组织数据存储和提高访问时间特别有用。
from litdata import StreamingDataset
from litdata.streaming.cache import Dir
cache_dir = "/path/to/your/cache"
data_dir = "s3://my-bucket/my_optimized_dataset"
dataset = StreamingDataset(input_dir=Dir(path=cache_dir, url=data_dir))
✅ 优化网络驱动器上的加载
优化本地网络上计算机的数据处理,以提高现场设置的性能。
本地计算节点可以挂载和使用网络驱动器。网络驱动器是本地局域网上的共享存储设备。为了减少网络负载,StreamingDataset 支持对数据块进行 缓存。
from litdata import StreamingDataset
dataset = StreamingDataset(input_dir="local:/data/shared-drive/some-data")
✅ 在分布式环境中优化数据集
Lightning 可以将大型工作负载并行分配到数百台机器上。通过扩展到足够多的机器,可以将完成数据处理任务的时间从数周缩短到几分钟。
要在多台机器上应用优化操作,只需向其提供 num_nodes 和 machine 参数,如下所示:
import os
from litdata import optimize, Machine
def compress(index):
return (index, index ** 2)
optimize(
fn=compress,
inputs=list(range(100)),
num_workers=2,
output_dir="my_output",
chunk_bytes="64MB",
num_nodes=2,
machine=Machine.DATA_PREP, # 你可以在几十种优化的机器之间选择
)
如果 output_dir 是本地路径,优化后的数据集将位于: /teamspace/jobs/{job_name}/nodes-0/my_output。否则,它将存储在指定的 output_dir 中。
读取优化后的数据集:
from litdata import StreamingDataset
output_dir = "/teamspace/jobs/litdata-optimize-2024-07-08/nodes.0/my_output"
dataset = StreamingDataset(output_dir)
print(dataset[:])
用于转换数据集的功能
✅ 并行化数据转换 (map)
同时对数据集的不同部分应用相同的更改,以节省时间和精力。
map 操作符可用于在输入列表上应用函数。
这里是一个使用 map 操作符在一个大图像文件夹上应用 resize_image 函数的示例。
from litdata import map
from PIL import Image
# 注意:输入也可以直接引用 s3 上的文件。
input_dir = "my_large_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# resize_image 函数接收一个输入(image_path)和输出目录。
# 写入 output_dir 的文件将被持久化。
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
map(
fn=resize_image,
inputs=inputs,
output_dir="s3://my-bucket/my_resized_images",
)
✅ 支持 S3 兼容的云对象存储
使用不同的云存储服务,提供数据存储灵活性和成本节省选项。
将 S3 兼容的对象存储服务器(如 MinIO)与 litdata 集成,非常适合本地基础设施设置。使用环境变量或配置文件配置端点和凭证。
设置环境变量以连接到 MinIO:
export AWS_ACCESS_KEY_ID=access_key
export AWS_SECRET_ACCESS_KEY=secret_key
export AWS_ENDPOINT_URL=http://localhost:9000 # MinIO 端点
或者,在 ~/.aws/{credentials,config} 中配置凭证和端点:
mkdir -p ~/.aws && \
cat <<EOL >> ~/.aws/credentials
[default]
aws_access_key_id = access_key
aws_secret_access_key = secret_key
EOL
cat <<EOL >> ~/.aws/config
[default]
endpoint_url = http://localhost:9000 # MinIO 端点
EOL
在 LitData with MinIO 仓库中探索 litdata 与 MinIO 的示例设置,以了解实际实现细节。
✅ 支持在块/样本级别对数据进行加密和解密
通过对单个样本或块应用加密来保护您的数据,确保敏感信息在存储过程中受到保护。
这个示例演示了如何使用 FernetEncryption 类进行样本级加密的数据优化函数。
from litdata import optimize
from litdata.utilities.encryption import FernetEncryption
import numpy as np
from PIL import Image
# 使用密码初始化FernetEncryption进行样本级加密
fernet = FernetEncryption(password="your_secure_password", level="sample")
data_dir = "s3://my-bucket/optimized_data"
def random_image(index):
"""生成一个随机图像用于演示目的。"""
fake_img = Image.fromarray(np.random.randint(0, 255, (32, 32, 3), dtype=np.uint8))
return {"image": fake_img, "class": index}
# 优化数据并应用加密
optimize(
fn=random_image,
inputs=list(range(5)), # 示例输入:[0, 1, 2, 3, 4]
num_workers=1,
output_dir=data_dir,
chunk_bytes="64MB",
encryption=fernet,
)
# 将加密密钥保存到文件以供日后使用
fernet.save("fernet.pem")
您可以使用StreamingDataset类加载加密数据,如下所示:
from litdata import StreamingDataset
from litdata.utilities.encryption import FernetEncryption
# 加载加密密钥
fernet = FernetEncryption(password="your_secure_password", level="sample")
fernet.load("fernet.pem")
# 创建一个流式数据集用于读取加密样本
ds = StreamingDataset(input_dir=data_dir, encryption=fernet)
如果您想实现自己的加密方法,可以继承Encryption类并定义必要的方法:
from litdata.utilities.encryption import Encryption
class CustomEncryption(Encryption):
def encrypt(self, data):
# 在此实现您的自定义加密逻辑
return data
def decrypt(self, data):
# 在此实现您的自定义解密逻辑
return data
通过这种设置,您可以确保数据安全的同时保持加密处理的灵活性。
基准测试
在本节中,我们展示了数据集优化速度和最终流式传输速度的基准测试(重现基准测试)。
流式传输速度
使用LitData优化和流式传输的数据比未优化的数据快20倍,比其他流式解决方案快2倍。
从AWS S3流式传输Imagenet 1.2M的速度:
| 框架 | 第1轮图像/秒(float32) | 第2轮图像/秒(float32) | 第1轮图像/秒(torch16) | 第2轮图像/秒(torch16) |
|---|---|---|---|---|
| PL Data | 5800 | 6589 | 6282 | 7221 |
| Web Dataset | 3134 | 3924 | 3343 | 4424 |
| Mosaic ML | 2898 | 5099 | 2809 | 5158 |
基准测试详情
- Imagenet-1.2M数据集包含
1,281,167张图像。 - 为了与其他基准测试保持一致,我们测量了从AWS S3加载的几个框架的流式传输速度(
每秒图像数)。
数据优化时间
LitData优化Imagenet数据集的速度比其他框架快3-5倍:
优化120万张ImageNet图像所需时间(越快越好):
| 框架 | 训练集转换时间 | 验证集转换时间 | 数据集大小 | 文件数量 |
|---|---|---|---|---|
| PL Data | 10:05分钟 | 00:30分钟 | 143.1 GB | 2,339 |
| Web Dataset | 32:36分钟 | 01:22分钟 | 147.8 GB | 1,144 |
| Mosaic ML | 49:49分钟 | 01:04分钟 | 143.1 GB | 2,298 |
在云端机器上并行化转换和数据优化
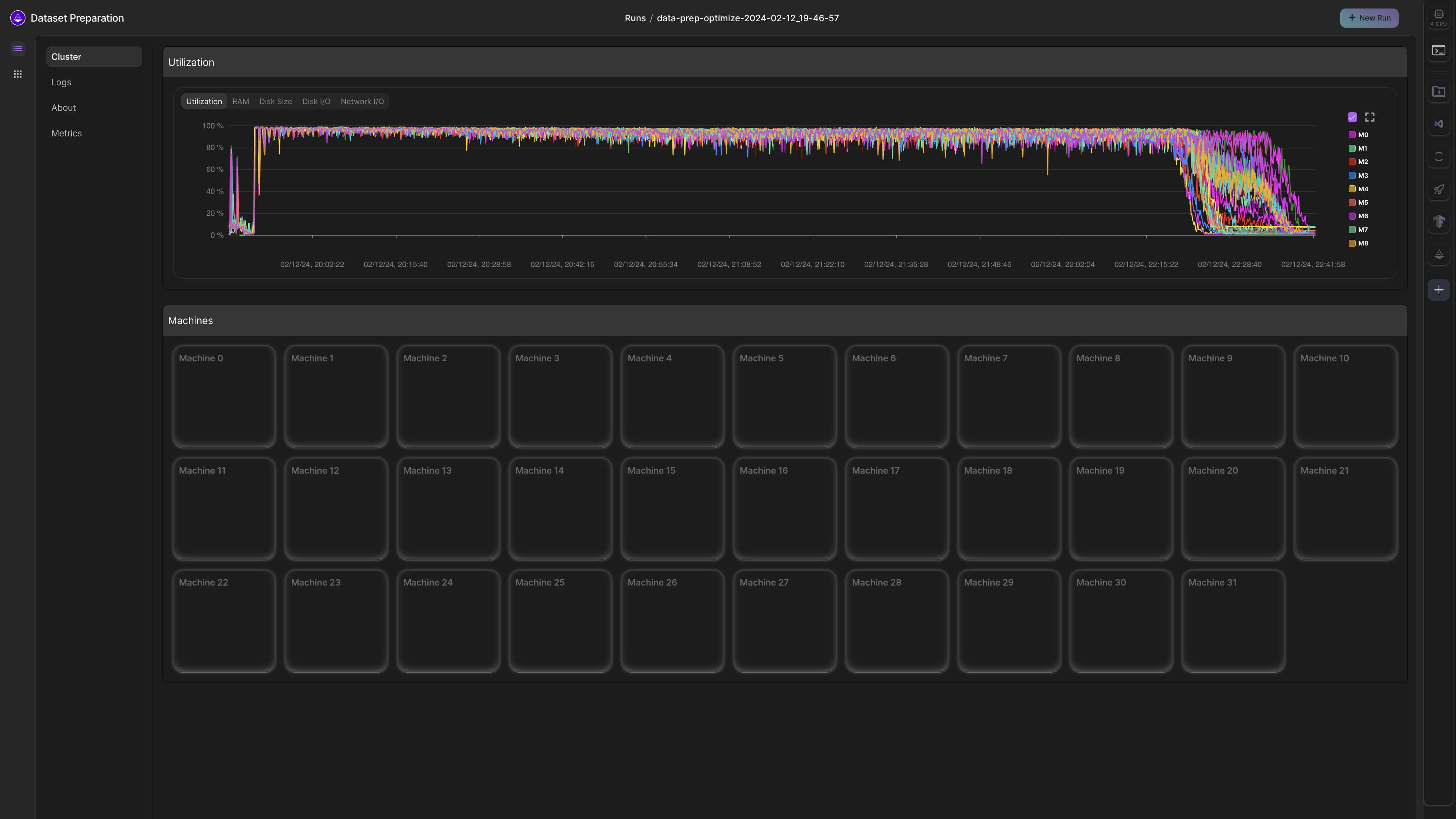
并行化数据转换
使用LitData的转换可以在多台机器上线性并行化。
例如,假设在单台A10G机器上嵌入一个数据集需要56小时。使用LitData,可以通过增加并行机器数量来加速这个过程
| 机器数量 | 耗时(小时) |
|---|---|
| 1 | 56 |
| 2 | 28 |
| 4 | 14 |
| ... | ... |
| 64 | 0.875 |
要扩展机器数量,请在Lightning Studios上运行处理脚本:
from litdata import map, Machine
map(
...
num_nodes=32,
machine=Machine.DATA_PREP, # 从数十种优化机器中选择
)
并行化数据优化
要扩展数据优化的机器数量,请使用Lightning Studios:
from litdata import optimize, Machine
optimize(
...
num_nodes=32,
machine=Machine.DATA_PREP, # 从数十种优化机器中选择
)
示例:在32台机器上(每台32个CPU)用2小时处理LAION 4亿图像数据集。
从模板开始
以下是LitData在大规模实际应用中的模板。
模板:转换数据集
| Studio | 数据类型 | 时间(分钟) | 机器数量 | 数据集 |
|---|---|---|---|---|
| 下载LAION-400MILLION数据集 | 图像和文本 | 120 | 32 | LAION-400M |
| 对200万篇瑞典维基百科文章进行分词 | 文本 | 7 | 4 | 瑞典维基百科 |
| 以不到5美元的成本嵌入英文维基百科 | 文本 | 15 | 3 | 英文维基百科 |
模板:优化 + 流式传输数据
| 工作室 | 数据类型 | 时间(分钟) | 机器数量 | 数据集 |
|---|---|---|---|---|
| 基准测试云数据加载库 | 图像与标签 | 10 | 1 | Imagenet 1M |
| 优化地理空间数据用于模型训练 | 图像与掩码 | 120 | 32 | 切萨皮克道路空间上下文 |
| 优化TinyLlama 1T数据集用于训练 | 文本 | 240 | 32 | SlimPajama 和 StarCoder |
| 优化Parquet文件用于模型训练 | Parquet文件 | 12 | 16 | 随机生成的数据 |
社区
LitData是一个接受贡献的社区项目 - 让我们一起打造世界上最先进的AI数据处理框架。











