
FlexGen简介
FlexGen是一个高吞吐量生成引擎,旨在使用有限的GPU内存运行大型语言模型(LLM)。它通过IO高效的卸载、压缩和大批量处理实现高吞吐量生成。
FlexGen的主要特点包括:
- 可在单个普通GPU上运行大型语言模型
- 通过灵活配置GPU、CPU和磁盘资源,适应各种硬件约束
- 使用线性规划优化器搜索最佳张量存储和访问模式
- 将权重和KV缓存压缩到4位精度,几乎不损失准确性
- 可实现比现有系统更高的最大吞吐量
快速开始
安装
FlexGen需要PyTorch >= 1.12版本。可以通过pip安装:
pip install flexgen
或从源码安装:
git clone https://github.com/FMInference/FlexGen.git
cd FlexGen
pip install -e .
单GPU入门示例
以OPT-1.3B模型为例:
python3 -m flexgen.flex_opt --model facebook/opt-1.3b
对于OPT-30B等大模型,需要使用CPU卸载:
python3 -m flexgen.flex_opt --model facebook/opt-30b --percent 0 100 100 0 100 0
主要应用场景
- 运行HELM基准测试
FlexGen可以作为HELM语言模型基准测试框架的执行后端。例如:
pip install crfm-helm
python3 -m flexgen.apps.helm_run --description mmlu:model=text,subject=abstract_algebra,data_augmentation=canonical --pad-to-seq-len 512 --model facebook/opt-30b --percent 20 80 0 100 0 100 --gpu-batch-size 48 --num-gpu-batches 3 --max-eval-instance 100
- 数据整理任务
可以运行论文"Can Foundation Models Wrangle Your Data?"中的示例。
- 分布式GPU扩展
FlexGen可以结合卸载和流水线并行来实现跨多台机器的GPU扩展。
API示例
FlexGen提供了类似Hugging Face的生成API:
output_ids = model.generate(
input_ids,
do_sample=True,
temperature=0.7,
max_new_tokens=32,
stop=stop
)
更多API使用示例可以参考completion.py。
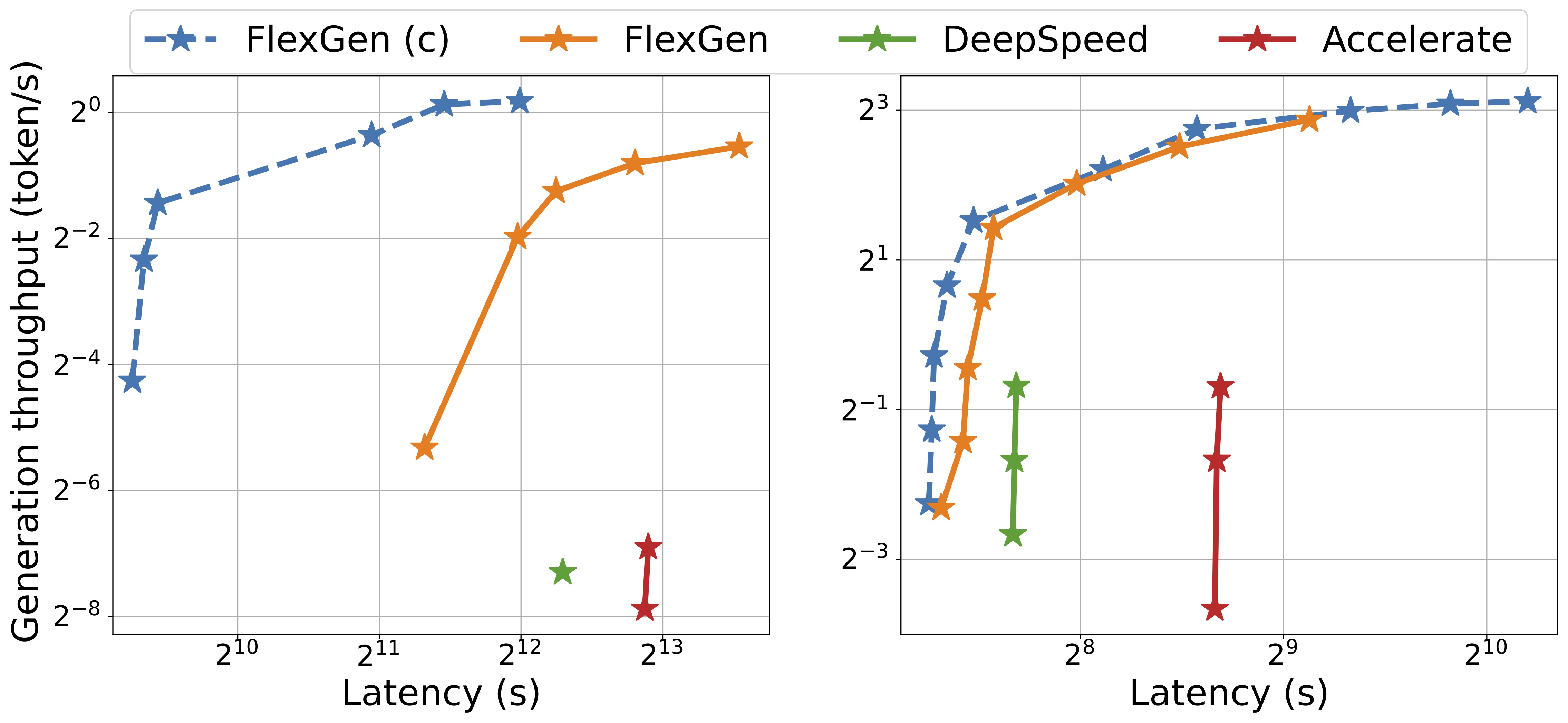
性能对比
在OPT-175B模型上,使用单个T4 GPU(16GB)、208GB内存和1.5TB SSD的配置下:
- Hugging Face Accelerate: 0.01 token/s
- DeepSpeed ZeRO-Inference: 0.01 token/s
- Petals: 0.08 token/s
- FlexGen: 0.69 token/s
- FlexGen with Compression: 1.12 token/s
FlexGen实现了显著更高的最大吞吐量。
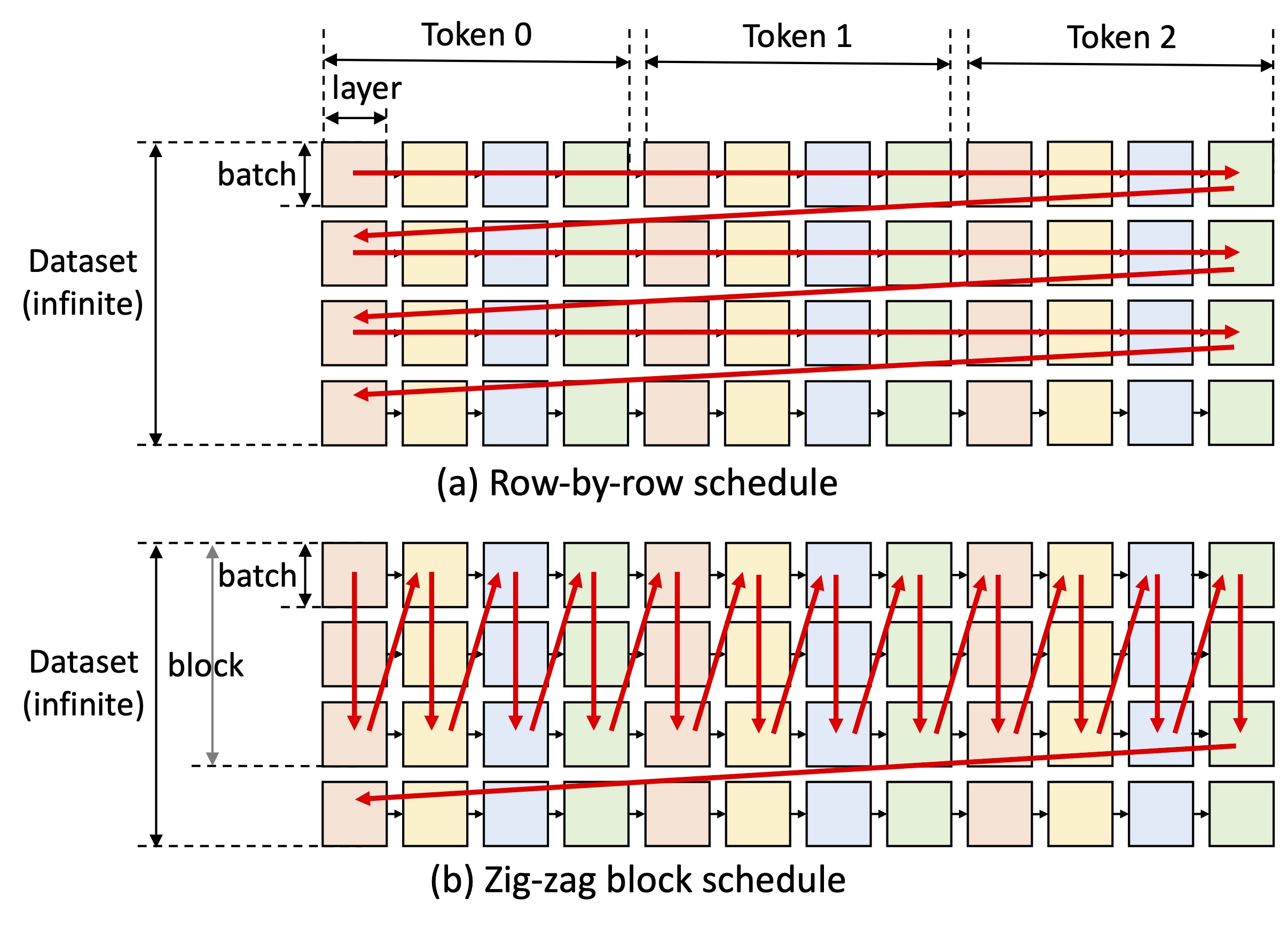
工作原理
FlexGen通过以下关键技术实现高吞吐量:
- 灵活聚合GPU、CPU和磁盘资源
- 使用线性规划优化器搜索最佳张量存储和访问模式
- 将权重和KV缓存压缩到4位
- 使用块调度来重用权重并重叠I/O与计算
更多资源
FlexGen为在普通硬件上高效运行大型语言模型开辟了新的可能。欢迎试用并为该开源项目做出贡献!










