
FLUTE简介
FLUTE (Flexible Lookup Table Engine)是一个为查找表(LUT)量化大语言模型设计的灵活引擎。它可以实现快速矩阵乘法,支持多种量化方案,在保持模型性能的同时大大降低内存和计算需求。

FLUTE的主要特点包括:
- 支持多种量化方案,包括uniform、lookup table等
- 兼容多种主流模型,如LLaMA、Gemma等
- 与vLLM、Hugging Face等框架无缝集成
- 提供简单易用的API和命令行工具
- 在多个基准测试中表现出色
本文将详细介绍FLUTE的背景、特性、使用方法以及在各种模型上的表现。
背景
随着大语言模型的规模不断增长,如何在有限的计算资源下高效运行这些模型成为一个重要问题。量化是一种有效的模型压缩方法,可以将模型参数从高精度(如FP32)压缩到低精度(如INT8、INT4等),从而减少内存占用和计算量。
传统的uniform量化将全精度权重映射到等间隔的低精度区间。而lookup table(LUT)量化则是一种更灵活的非均匀量化方案,可以通过查找表将量化后的值映射到任意值。FLUTE就是基于LUT量化设计的一个高效引擎。
FLUTE支持多种量化方案:
int4,int3,int2: 对应uniform/integer量化fp4,fp3,fp2: 浮点量化nf4,nf3,nf2: 扩展了QLoRA中引入的nf4数据格式- 任意自定义查找表: 甚至可以学习得到最优表
这种灵活性使FLUTE能够适应不同模型和任务的需求,在压缩率和性能之间取得更好的平衡。
FLUTE的主要特性
1. 高效的矩阵乘法实现
FLUTE针对LUT量化模型优化了矩阵乘法实现,可以显著提高计算速度。下图展示了FLUTE在不同设置下的性能表现:
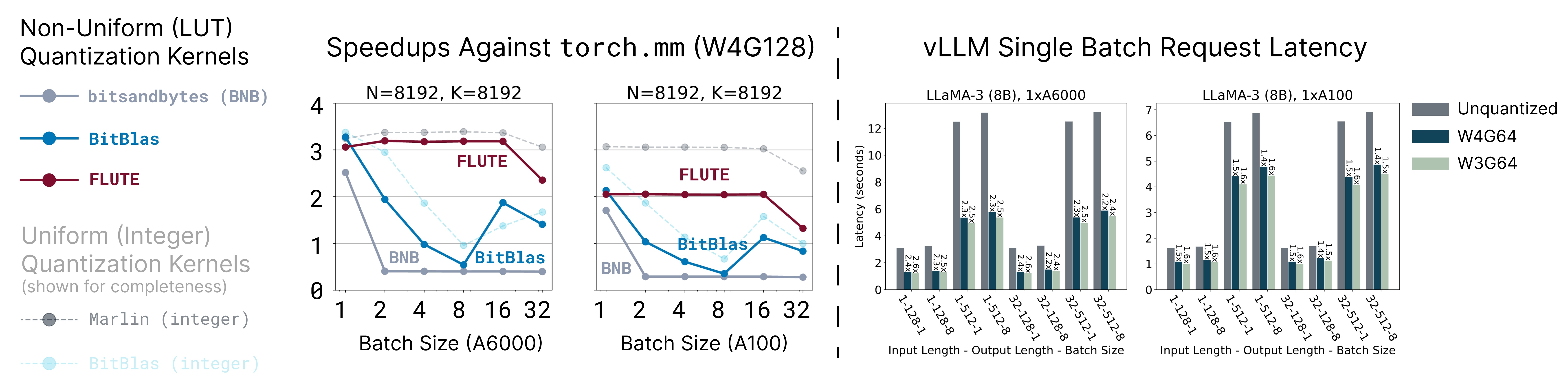
可以看到,FLUTE在各种量化位数和分组大小下都能保持较高的吞吐量。
2. 广泛的模型支持
FLUTE目前支持以下模型:
- LLaMA-3/3.1 (8B, 70B, 405B)
- Gemma-2 (9B, 27B)
这些模型覆盖了目前主流的大语言模型架构,使FLUTE能够广泛应用于各种场景。
3. 灵活的量化选项
FLUTE支持多种量化设置:
- 位数: 4-bit, 3-bit, 2-bit
- 分组大小: 32, 64, 128, 256
- 输入数据类型:
torch.float16,torch.bfloat16
用户可以根据具体需求选择合适的量化参数。
4. 与主流框架集成
FLUTE可以无缝集成到vLLM和Hugging Face等主流框架中。例如,使用FLUTE量化的模型可以直接通过vLLM部署服务:
python -m flute.integrations.vllm vllm.entrypoints.openai.api_server \
--model radi-cho/Meta-Llama-3.1-8B-FLUTE \
--quantization flute
这种集成使得FLUTE可以轻松融入现有的机器学习工作流程。
使用FLUTE
安装
FLUTE可以通过pip安装:
# For CUDA 12.1
pip install flute-kernel
# For CUDA 11.8
pip install flute-kernel -i https://flute-ai.github.io/whl/cu118
量化自定义模型
FLUTE提供了简单的API来量化自定义模型。以下是一个基本示例:
import flute.integrations.base
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path,
device_map="cpu",
torch_dtype="auto")
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers,
num_bits=4,
group_size=128,
fake=False)
FLUTE还支持从bitsandbytes模型转换,以及学习最优的量化参数。
模型性能
FLUTE团队在多个基准测试上评估了量化后模型的性能。以下是部分结果:
LLaMA-3.1 (8B)
| 模型 | Wiki PPL | C4 PPL | LLM Eval Avg. |
|---|---|---|---|
| 原始模型 | 6.31 | 9.60 | 69.75 |
| NFL W4G64 | 6.24 | 10.06 | 69.13 |
| NFL W3G64 | 7.23 | 11.83 | 65.66 |
Gemma-2 (9B)
| 模型 | Wiki PPL | C4 PPL | LLM Eval Avg. |
|---|---|---|---|
| 原始模型 | 6.88 | 10.12 | 73.12 |
| NFL W4G64 | 6.49 | 10.35 | 72.50 |
| NFL W3G64 | 7.06 | 11.14 | 70.02 |
可以看到,即使在3-bit量化下,FLUTE也能保持较好的模型性能。这表明FLUTE在模型压缩和性能保持之间取得了很好的平衡。
未来展望
FLUTE团队正在积极开发和改进这个项目。未来的计划包括:
- 支持更多模型架构
- 优化bfloat16数据类型的性能
- 增加对更多GPU型号的支持
- 改进量化算法,进一步提高性能
结论
FLUTE为大语言模型的量化和部署提供了一个强大而灵活的解决方案。通过支持多种量化方案、优化的矩阵乘法实现以及与主流框架的集成,FLUTE可以帮助研究人员和工程师更高效地运行大规模语言模型。
无论是在学术研究还是工业应用中,FLUTE都是一个值得关注的项目。它不仅可以帮助降低模型运行的硬件需求,还为探索新的量化算法提供了便利的平台。
如果你对大语言模型的高效运行感兴趣,不妨尝试使用FLUTE,探索它所带来的可能性。你可以在FLUTE的GitHub仓库中找到更多信息和使用指南。










