
 Github
Github Huggingface
Huggingface 论文
论文

FLUTE:用于LUT量化LLM的灵活查找表引擎



更新
- 2024年8月5日 添加量化的LLaMA-3.1(8B/70B)模型。
- 2024年8月2日 添加对RTX4090的支持。
- 2024年7月27日 添加对LLaMA-3.1(405B)的支持,并优化了BF16性能。FP16仍然是推荐的数据类型,尤其是在3比特设置下。
安装
通过pip安装FLUTE或从源代码构建:
# 对于CUDA 12.1
pip install flute-kernel
# 对于CUDA 11.8
pip install flute-kernel -i https://flute-ai.github.io/whl/cu118
前往入门指南并尝试使用!
背景
均匀量化将全精度权重转换为等大小的低精度区间。查找表(LUT)量化是非均匀量化的一种灵活变体,可以通过查找表将区间映射到任意值。
| 均匀(整数)量化 | 查找表量化 |
|---|---|
|
$$\widehat{\mathbf{W}} = \mathtt{float}(\mathbf{Q}) \cdot \mathbf{s}$$ |
$$\widehat{\mathbf{W}} = \mathtt{tableLookup}(\mathbf{Q}, \mathtt{table}) \cdot \mathbf{s}$$ |
其中$\mathbf{Q}$表示量化权重,$\mathbf{s}$表示(分组)缩放,$\widehat{\mathbf{W}}$表示反量化权重。以下是FLUTE支持的一些查找表示例。
| 示例 | 说明 |
|---|---|
|
|
恢复均匀/整数量化 |
|
| |
|
|
泛化QLoRA引入的 |
|
任意表 |
甚至可以学习它! |
FLUTE支持的新模型
内核的灵活性可能会带来新的量化算法。作为概念证明,我们发布了一些使用**学习正态浮点(NFL)**量化的模型 — 这是对QLoRA引入的nf4数据格式的简单扩展。NFL使用NF量化的查找表和缩放初始化查找表和缩放。然后,它使用校准数据通过直通估计来学习缩放,以获得关于缩放的梯度。
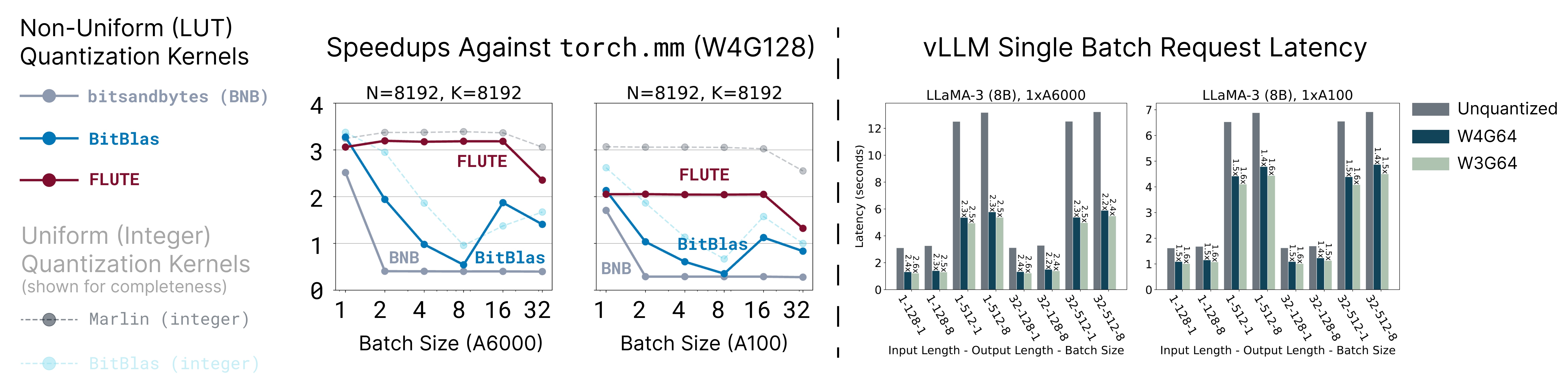
基准测试
有关其他基准测试、详细分析和相应的指令调优模型,请参阅论文和模型库。
LLaMA-3.1
| Wiki PPL | C4 PPL | LLM评估平均值 | Wiki PPL | C4 PPL | LLM评估平均值 | ||
|---|---|---|---|---|---|---|---|
| LLaMA-3.1 (8B) | 6.31 | 9.60 | 69.75 | LLaMA-3.1 (70B) | 2.82 | 7.18 | 75.45 |
| + NFL W4G64 | 6.24 | 10.06 | 69.13 | + NFL W4G64 | 3.09 | 7.53 | 74.84 |
| + NFL W3G64 | 7.23 | 11.83 | 65.66 | + NFL W3G64 | 4.29 | 8.91 | 72.65 |
Gemma-2
| Wiki PPL | C4 PPL | LLM评估平均值 | Wiki PPL | C4 PPL | LLM评估平均值 | ||
|---|---|---|---|---|---|---|---|
| Gemma-2 (9B) | 6.88 | 10.12 | 73.12 | Gemma-2 (27B) | 5.70 | 8.98 | 75.71 |
| + NFL W4G64 | 6.49 | 10.35 | 72.50 | + NFL W4G64 | 5.69 | 9.31 | 74.11 |
入门指南
FLUTE + vLLM
FLUTE量化模型(模型库)可以直接使用现有框架(如vLLM)进行服务。
- python -m vllm.entrypoints.openai.api_server \
+ python -m flute.integrations.vllm vllm.entrypoints.openai.api_server \
--model [模型] \
--revision [版本] \
--tensor-parallel-size [TP大小] \
+ --quantization flute
例如,以下命令在单个GPU上运行FLUTE量化的LLaMA-3.1(8B)。
python -m flute.integrations.vllm vllm.entrypoints.openai.api_server \
--model radi-cho/Meta-Llama-3.1-8B-FLUTE \
--quantization flute
然后我们可以像往常一样查询vLLM服务器。
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "radi-cho/Meta-Llama-3.1-8B-FLUTE",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
FLUTE + HuggingFace
FLUTE也可以与HuggingFace及其accelerate扩展无缝配合。这种集成主要是实验性的,尚未优化。对性能考虑敏感的用户应该使用vLLM集成。
以下示例对密集模型执行简单量化。之后,模型可以正常使用。(即将支持加载预量化模型!)
import flute.integrations.base
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers, # 适用于LLaMA-3和Gemma-2
num_bits=num_bits,
group_size=group_size,
fake=False,
handle_hooks=True) # 用于`accelerate`钩子
支持和兼容性
内核
| 描述 | 支持(通过pip) | 支持(从源代码构建) |
|---|---|---|
| 输入数据类型 | torch.float16 torch.bfloat16 | |
| 位数 | 4位 3位 | 2位 |
| 分组大小 | 32 64 128 256 | ❓ |
| GPU | A100 A6000 RTX 4090 | H100(未优化) |
[!警告] 在当前版本中,我们注意到
torch.bfloat16比torch.float16慢。这可能是由于缺乏调优,以及Ampere GPU缺少对bfloat16矢量化原子加法的硬件加速。
[!警告] 我们注意到在使用
位数=4,分组大小=256,GPU=A100时出现了一些数值不稳定的情况,尽管这种情况相对罕见(9360个测试用例中有8个失败)。我们还注意到在某些情况下使用位数=4,分组大小=256,数据类型=bfloat16,GPU=RTX4090时存在正确性问题(52个测试用例中有1个失败)。我们将对此进行调查,但目前建议避免使用这些特定配置(W4G256)。
模型
[!注意] 在当前版本中,由于历史原因,内核是形状专用的(即我们为每个矩阵形状调整tile大小等)。请参阅下表了解支持的用例,因为不同的平台和张量并行大小会改变矩阵形状。我们计划在不久的将来添加对广泛形状的支持。同时,如果您有任何特定的模型需求,请告诉我们,我们很乐意为其添加支持。
| 模型 | 单GPU / 流水线并行 | 张量并行 |
|---|---|---|
| LLaMA-3/3.1 (8B) | ✅ | |
| LLaMA-3/3.1 (70B) | ✅ | 2或4个GPU |
| LLaMA-3.1 (405B) | ✅ | 4或8个GPU |
| Gemma-2 (9B) | ✅ | |
| Gemma-2 (27B) | ✅ | 2或4个GPU |
模型库
[!注意] 我们在此发布的模型是在更多数据上训练的,因此与论文中的模型不同。
[!提示] HuggingFace Hub链接默认使用
NFL W4G64量化。要使用NFL W3G64量化,请添加--revision nfl_w3g64。
LLaMA-3.1 (8B)
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 未量化 | 6.31 | 9.60 | 79.16 | 82.20 | 52.65 | 60.71 | 74.03 | 69.75 |
| NFL W4G64 | 6.24 | 10.06 | 79.38 | 81.61 | 51.54 | 59.57 | 73.56 | 69.13 |
| NFL W3G64 | 7.23 | 11.83 | 77.91 | 76.98 | 46.33 | 56.74 | 70.32 | 65.66 |
LLaMA-3.1 (70B)
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 未量化 | 2.82 | 7.18 | 82.81 | 85.31 | 59.64 | 67.49 | 82.00 | 75.45 |
| NFL W4G64 | 3.09 | 7.53 | 83.03 | 85.52 | 58.19 | 67.04 | 80.43 | 74.84 |
| NFL W3G64 | 4.29 | 8.91 | 82.04 | 83.29 | 54.78 | 64.99 | 78.14 | 72.65 |
LLaMA-3.1 Instruct (8B)
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 6.78 | 11.11 |
| NFL W3G64 | 7.73 | 12.83 |
LLaMA-3.1 Instruct (70B)
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 4.15 | 9.18 |
| NFL W3G64 | 4.74 | 9.48 |
LLaMA-3 (8B)
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 未量化 | 6.1 | 9.2 | 79.9 | 80.1 | 50.4 | 60.2 | 72.8 | 68.6 |
| NFL W4G64 | 6.11 | 9.38 | 79.33 | 79.79 | 49.74 | 59.22 | 73.95 | 68.41 |
| NFL W3G64 | 7.13 | 11.06 | 78.78 | 76.22 | 44.37 | 56.69 | 70.32 | 65.28 |
LLaMA-3 (70B)
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 未量化 | 2.9 | 6.9 | 82.4 | 86.9 | 60.3 | 66.4 | 80.6 | 75.3 |
| NFL W4G64 | 3.03 | 7.03 | 82.15 | 85.98 | 57.85 | 66.17 | 79.79 | 74.39 |
| NFL W3G64 | 4.15 | 8.10 | 80.74 | 83.71 | 55.29 | 64.05 | 78.45 | 72.45 |
LLaMA-3 Instruct (8B)
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 6.78 | 10.61 |
| NFL W3G64 | 7.75 | 12.28 |
LLaMA-3 Instruct (70B)
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 3.67 | 7.95 |
| NFL W3G64 | 4.90 | 10.86 |
Gemma-2 (9B)
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 未量化 | 6.88 | 10.12 | 81.39 | 87.37 | 61.35 | 61.23 | 74.27 | 73.12 |
| NFL W4G64 | 6.49 | 10.35 | 81.28 | 86.24 | 59.30 | 60.40 | 75.30 | 72.50 |
| NFL W3G64 | 7.06 | 11.14 | 80.52 | 83.16 | 55.46 | 58.28 | 72.69 | 70.02 |
Gemma-2 (27B)
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 未量化 | 5.70 | 8.98 | 83.24 | 87.84 | 62.88 | 65.35 | 79.24 | 75.71 |
| NFL W4G64 | 5.69 | 9.31 | 82.53 | 86.45 | 59.22 | 64.13 | 78.21 | 74.11 |
Gemma-2 Instruct (9B)
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 6.88 | 11.02 |
| NFL W3G64 | 7.35 | 11.72 |
Gemma-2 Instruct (27B)
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 5.91 | 9.71 |
量化您自己的模型
我们提供了两个API来量化自定义模型。最简单的方法是使用命令行界面。
简单正态浮点量化
python -m flute.integrations.base \
--pretrained_model_name_or_path meta-llama/Meta-Llama-3-70B-Instruct \
--save_directory Meta-Llama-3-70B-Instruct-NF4 \
--num_bits 4 \
--group_size 128
CLI本质上包装了以下Python API,
from transformers import (
LlamaForCausalLM,
Gemma2ForCausalLM,
AutoModelForCausalLM)
import flute.integrations.base
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path,
device_map="cpu",
torch_dtype="auto")
if isinstance(model, (LlamaForCausalLM, Gemma2ForCausalLM)):
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers,
num_bits=num_bits,
group_size=group_size,
fake=False)
else:
# 更多模型即将推出
raise NotImplementedError
学习正态浮点量化
即将推出!
从源代码构建
- 克隆CUTLASS库。
# 不幸的是,目前路径是硬编码的。如果您在不同的目录中安装CUTLASS,
# 请确保更新了`setup.py`中相应的路径。
cd /workspace
git clone https://github.com/NVIDIA/cutlass.git
cd cutlass
git checkout v3.4.1
- 构建。
git clone https://github.com/HanGuo97/flute
cd flute
pip install -e .
**注意:**构建过程要求本地CUDA版本(nvcc --version)与PyTorch的CUDA匹配。在构建过程中出现与CUDA版本不匹配相关错误的情况下,请尝试添加--no-build-isolation。
致谢和引用
特别感谢Dmytro Ivchenko、Yijie Bei和Fireworks AI团队的有益讨论。如果您发现本仓库中的任何模型或代码有用,请随意引用:
@article{flute2024,
title={Fast Matrix Multiplications for Lookup Table-Quantized LLMs},
author={Guo, Han and Brandon, William and Cholakov, Radostin and Ragan-Kelley, Jonathan and Xing, Eric P and Kim, Yoon},
journal={arXiv preprint arXiv:2407.10960},
year={2024}
}











