
GPT-Fast:高性能原生PyTorch文本生成的简洁实现
在人工智能领域,生成式AI技术正在经历爆炸式的发展。其中,大型语言模型(LLM)的文本生成能力尤其引人注目。然而,如何在保持模型质量的同时提高推理速度,成为了一个重要的挑战。针对这一问题,PyTorch团队开发了GPT-Fast项目,通过纯原生PyTorch实现,在不到1000行Python代码的情况下,将transformer文本生成的性能提升了近10倍。本文将深入介绍GPT-Fast的主要特性、优化技术及其性能表现。
主要特性
GPT-Fast具有以下几个突出的特点:
- 极低的延迟
- 代码量少于1000行Python
- 除PyTorch和sentencepiece外无其他依赖
- 支持int8/int4量化
- 实现了推测解码(Speculative Decoding)
- 支持张量并行(Tensor Parallelism)
- 同时支持NVIDIA和AMD GPU
值得注意的是,GPT-Fast并不是一个"框架"或"库",而是旨在展示原生PyTorch能够达到的性能水平。项目鼓励用户根据需要复制、粘贴和修改代码。
支持的模型
GPT-Fast主要支持LLaMA系列模型,包括LLaMA-2和LLaMA-3。此外,它还支持Mixtral 8x7B,这是一个高质量的稀疏混合专家(MoE)模型。
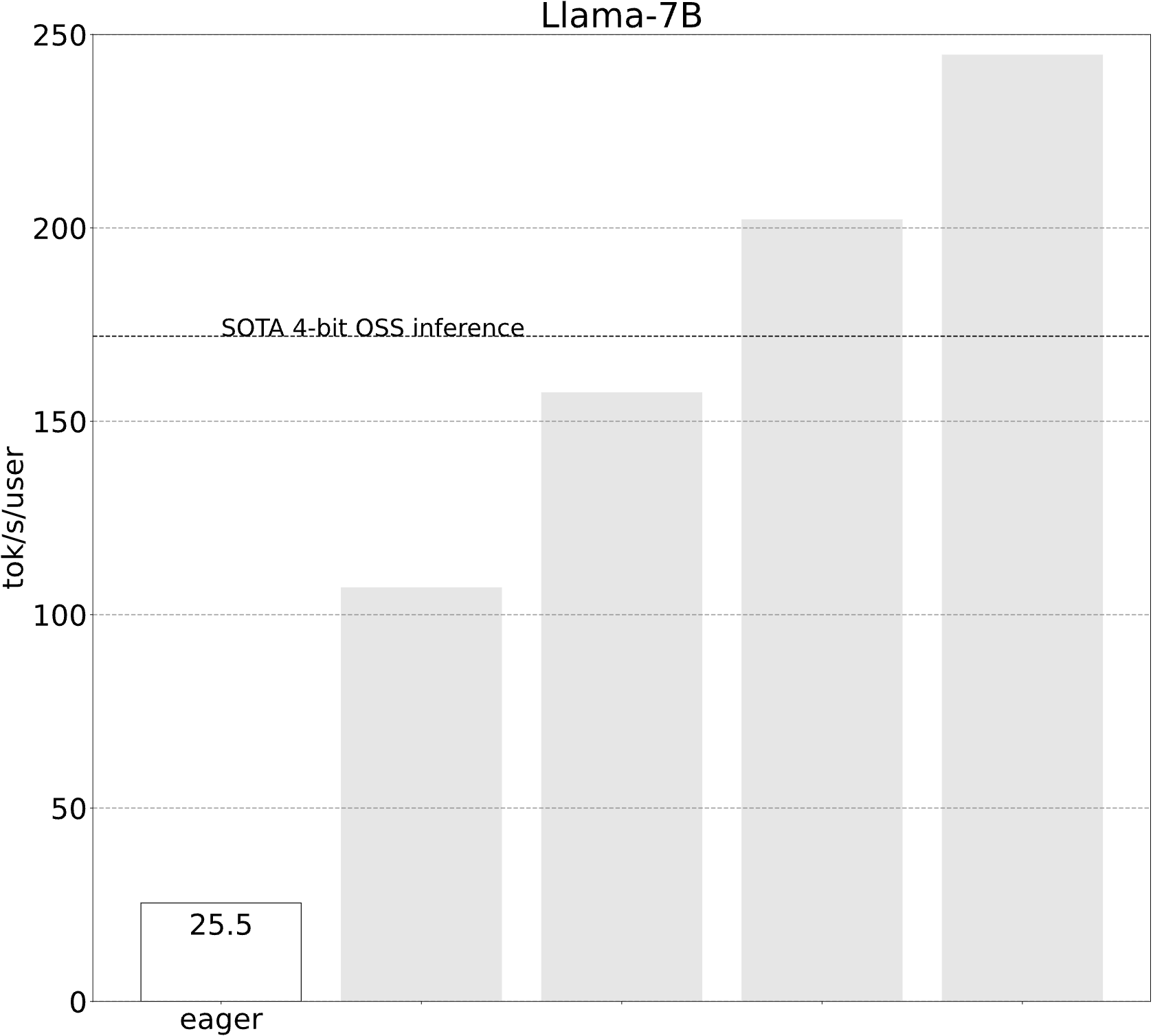
上图展示了Mixtral 8x7B在不同GPU数量和量化方式下的平均token生成速率。这些基准测试在8个A100-80GB GPU上运行,功率限制为330W,采用混合立方体网状拓扑。所有测试都在批处理大小为1的情况下进行,这意味着报告的tokens/s数字等同于"tokens/s/用户"。此外,测试使用了非常小的提示长度(仅5个token)。
核心优化技术
GPT-Fast采用了多种优化技术来提高性能:
- torch.compile: PyTorch模型的编译器
- GPU量化: 通过降低精度操作加速模型
- 推测解码: 使用小型"草稿"模型预测大型"目标"模型的输出来加速LLM
- 张量并行: 通过在多个设备上运行模型来加速
这些优化技术的组合使得GPT-Fast能够在保持模型质量的同时,显著提高推理速度。
性能基准测试
GPT-Fast在多种配置下进行了详细的性能测试。以下是一些关键的性能数据:
LLaMA-2-7B模型性能
| 技术 | Tokens/Second | 内存带宽 (GB/s) |
|---|---|---|
| 基准 | 104.9 | 1397.31 |
| 8位 | 155.58 | 1069.20 |
| 4位 (G=32) | 196.80 | 862.69 |
LLaMA-2-70B模型性能(8 GPU)
| 技术 | Tokens/Second | 内存带宽 (GB/s) |
|---|---|---|
| 基准 | 62.50 | 1135.29 |
| 8位 | 80.44 | 752.04 |
| 4位 (G=32) | 90.77 | 548.10 |
这些测试结果显示,通过量化和并行技术,GPT-Fast能够显著提高大型模型的推理速度。
使用方法
GPT-Fast的使用非常简单。首先,用户需要安装PyTorch nightly版本和其他必要的依赖包。然后,可以通过以下命令生成文本:
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --prompt "Hello, my name is"
对于量化模型,只需将checkpoint路径更改为相应的量化模型路径即可。
推测解码
GPT-Fast实现了推测解码技术,这是一种通过使用较小的"草稿"模型来加速大型模型生成的方法。例如:
export DRAFT_MODEL_REPO=meta-llama/Llama-2-7b-chat-hf
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --draft_checkpoint_path checkpoints/$DRAFT_MODEL_REPO/model_int8.pth
张量并行
对于多GPU环境,GPT-Fast支持张量并行,可以通过以下命令启用:
ENABLE_INTRA_NODE_COMM=1 torchrun --standalone --nproc_per_node=2 generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth
社区项目
GPT-Fast的简洁高效设计也激发了社区的创新。一些受GPT-Fast启发的项目包括:
- gpt-blazing: 将相同的性能优化策略应用于更多模型(如baichuan2)
- gptfast: 将部分性能优化应用于所有Huggingface模型
- gpt-accelera: 扩展GPT-Fast以支持SFT/RM/PPO训练和批量推理,以优化吞吐量
这些社区项目进一步扩展了GPT-Fast的应用范围,为更多场景提供了高性能的文本生成解决方案。
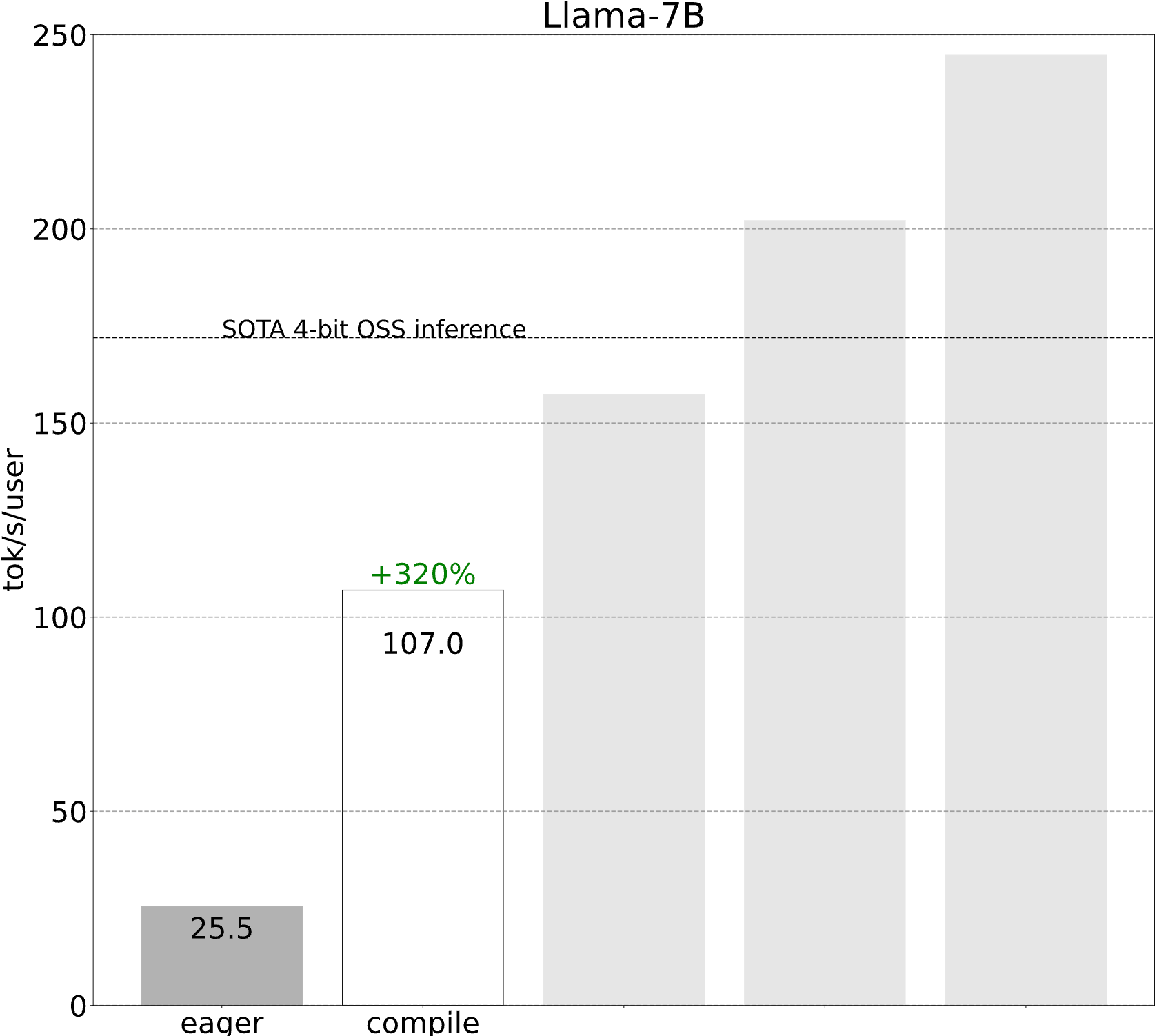
上图展示了GPT-Fast在不同优化技术下的性能提升。可以看到,通过组合多种优化技术,GPT-Fast实现了显著的性能提升。
结论
GPT-Fast项目展示了如何通过纯原生PyTorch实现高性能的transformer文本生成。通过结合多种优化技术,GPT-Fast在保持代码简洁性的同时,实现了接近甚至超越现有最先进(SOTA)性能的推理速度。这个项目不仅为研究人员和开发者提供了一个高效的文本生成工具,也为探索和实现AI模型性能优化提供了宝贵的参考。
GPT-Fast的成功表明,通过深入理解底层技术并巧妙地组合优化策略,即使是复杂的AI任务也可以在保持高性能的同时实现简洁的实现。这为未来AI模型的优化和部署提供了新的思路和可能性。
随着生成式AI技术的不断发展,像GPT-Fast这样的项目将在推动技术进步和实际应用中发挥重要作用。它不仅提高了模型的推理效率,也为更广泛的AI应用场景铺平了道路,让高性能的文本生成能力能够更容易地集成到各种应用中。









