
Granite代码模型:开启代码智能新纪元
在当今软件驱动的世界中,代码开发效率和质量的提升至关重要。为了应对这一挑战,IBM研究院推出了Granite代码模型系列 - 一组专为代码智能任务设计的开源基础模型。这些模型不仅在多项代码相关任务上展现出卓越的性能,还为企业级AI应用树立了新标杆。让我们深入了解这个令人兴奋的项目。
模型概览:全方位的代码智能助手
Granite代码模型是一系列专门针对代码生成任务(如修复bug、解释代码、编写文档等)设计的解码器模型。这些模型经过116种编程语言的代码训练,在多种代码相关任务上展现出最先进的性能。
Granite代码模型家族主要包含两大类:
- Granite代码基础模型:用于代码修复、解释和合成等基础任务的模型。
- Granite代码指令模型:通过Git提交记录和人工指令等方式微调的指令跟随模型。
这两类模型都提供了3B、8B、20B和34B参数规模的版本,可适应不同的应用场景。

卓越优势:全能型代码AI的新标杆
Granite代码模型的主要优势包括:
-
全能型代码LLM:在代码生成、解释、修复、编辑和翻译等多种任务上都达到了极具竞争力的性能水平,展现了解决多样化编码任务的能力。
-
可信赖的企业级LLM:所有模型都遵循IBM的AI伦理原则进行训练数据收集,并得到IBM法务团队的指导,确保企业使用的可信度。所有Granite代码模型都以Apache 2.0许可发布,可用于研究和商业用途。
数据与训练:精心设计的数据处理流程
Granite团队对训练数据的处理非常严谨,主要包括以下步骤:
-
数据收集:结合公开数据集(如GitHub Code Clean、Starcoder数据)、公共代码仓库和GitHub issues。
-
数据过滤:基于编程语言和代码质量进行筛选。
-
去重:采用精确和模糊去重策略,移除相似或重复的代码内容。
-
内容过滤:应用HAP内容过滤器,降低模型生成有害、滥用或亵渎性语言的可能性。
-
隐私保护:通过替换个人身份信息(如姓名、邮箱、密码等)为对应的标记,保护用户隐私。
-
安全检查:使用ClamAV扫描所有数据集,识别和移除源代码中的恶意软件实例。
除代码数据外,团队还整理了高质量的自然语言数据集,以提高模型的语言理解和数学推理能力。
预训练与指令微调:两阶段训练策略
Granite代码基础模型的训练采用了两个阶段:
-
第一阶段(纯代码训练):
- 3B和8B模型:在4万亿个代码token上训练,涵盖116种语言。
- 20B模型:在3万亿个代码token上训练。
- 34B模型:在20B模型的1.6万亿token检查点基础上,经过深度扩展后再训练1.4万亿token。
-
第二阶段(代码+语言训练):
- 所有模型:在5000亿个token上进行混合训练,其中80%为代码,20%为高质量的自然语言数据。
对于Granite代码指令模型,团队使用了以下数据进行微调:
- 来自CommitPackFT的代码提交数据。
- 高质量数学数据集,如MathInstruct和MetaMathQA。
- 代码指令数据集,包括Glaive-Code-Assistant-v3、Self-OSS-Instruct-SC2等。
- 高质量语言指令数据集,如HelpSteer和Platypus的开源许可过滤版本。
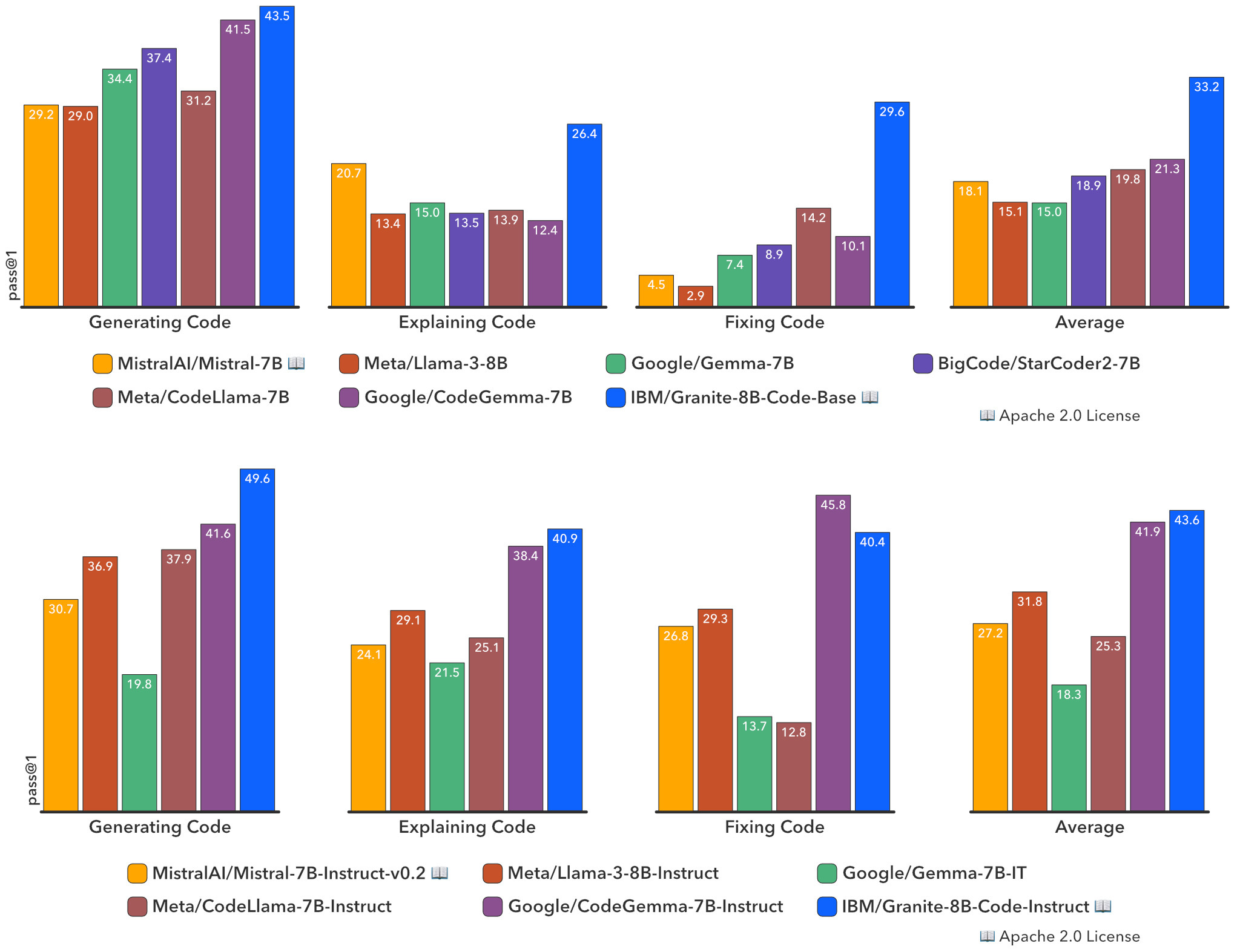
评估结果:全面超越开源代码模型
Granite团队对模型进行了广泛的评估,包括但不限于HumanEvalPack、MBPP和MBPP+等基准测试。这些测试涵盖了各种常用编程语言(如Python、JavaScript、Java、Go、C++、Rust)的不同编码任务。
结果显示,Granite代码模型在各种模型规模下都优于强大的开源模型。例如,Granite-8B-Code-Base在三项编码任务上的表现超过了Mistral-7B、LLama-3-8B等模型。
如何使用Granite代码模型?
Granite代码模型可通过Hugging Face轻松使用。以下是一个简单的推理示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # 或 "cpu"
model_path = "ibm-granite/granite-3b-code-base-2k" # 从列表中选择合适的模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device)
model.eval()
input_text = "def generate():"
input_tokens = tokenizer(input_text, return_tensors="pt")
for i in input_tokens:
input_tokens[i] = input_tokens[i].to(device)
output = model.generate(**input_tokens)
output = tokenizer.batch_decode(output)
for i in output:
print(i)
对于模型微调,Granite团队推荐使用Dolomite Engine。这个工具专门为Granite代码模型设计,可以轻松进行指令微调或其他定制化训练。
开源贡献与反馈
Granite代码模型项目欢迎社区贡献。如果您想参与项目开发,请查看贡献指南和行为准则。
对于模型使用反馈,您可以访问Hugging Face集合页面选择相应模型仓库,在"Community"标签下发起讨论。或者,您也可以在GitHub讨论页面提出问题或评论。
结语:代码智能的新纪元
Granite代码模型系列代表了代码智能领域的重大突破。通过提供一系列高性能、可信赖的开源模型,IBM不仅推动了代码开发效率的提升,还为企业级AI应用树立了新的标准。随着这些模型在研究和商业领域的广泛应用,我们有理由期待看到更多创新性的代码智能工具和解决方案的涌现。
无论您是研究人员、开发者还是企业用户,Granite代码模型都为您提供了探索和利用先进代码智能技术的绝佳机会。让我们共同期待这项技术将如何重塑软件开发的未来!









