
GritLM:统一生成和表示学习的突破性语言模型
在自然语言处理领域,一个长期存在的挑战是如何设计一个既擅长生成任务又擅长表示学习任务的通用模型。传统上,这两类任务往往需要不同的模型架构和训练方法。然而,最近由ContextualAI团队开发的GritLM模型为解决这一难题带来了突破性进展。
什么是GritLM?
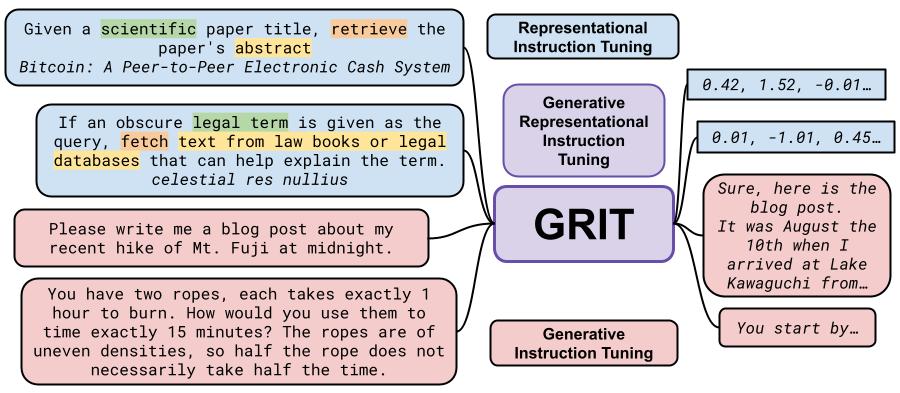
GritLM是一种基于生成式表示指令调优(Generative Representational Instruction Tuning, GRIT)技术开发的大型语言模型。它的核心创新在于通过指令来区分生成和表示学习任务,从而在一个统一的模型中实现两种能力的结合。
如上图所示,GritLM就像一只灵活的章鱼,能够同时处理多种不同类型的任务。这种统一的方法不仅简化了模型架构,还带来了性能上的显著提升。
GritLM的主要特点
-
统一的架构: GritLM使用相同的基础模型来处理生成和表示学习任务,通过指令来区分不同任务类型。
-
卓越的性能: 在多项基准测试中,GritLM展现出了优异的表现:
- GritLM 7B在大规模文本嵌入基准测试(MTEB)中创造了新的记录。
- 在各种生成任务中,GritLM 7B的表现超过了同等规模的其他开源模型。
- 更大规模的GritLM 8x7B模型在生成任务中的表现甚至超过了所有测试过的开源生成语言模型。
-
高效的检索增强生成: 通过统一生成和表示学习,GritLM在处理长文档的检索增强生成(RAG)任务时,速度提升了60%以上。
-
灵活的应用: GritLM可以根据不同的需求进行调整,既可以用于纯生成任务,也可以用于纯表示学习任务,或者两者兼顾。
GritLM的技术细节
GritLM的核心是GRIT技术,它通过特殊的训练方法使模型能够理解和执行不同类型的指令。例如:
- 对于表示学习任务,模型会收到类似这样的指令:"给定一篇科学论文的标题,检索该论文的摘要"
- 对于生成任务,模型可能会收到这样的指令:"请用莎士比亚的风格写一首关于我最近午夜爬富士山的诗"
通过这种方式,GritLM学会了在同一个模型中灵活切换不同的任务模式。
GritLM的应用示例
让我们来看几个GritLM实际应用的例子:
- 文本嵌入:
from gritlm import GritLM
model = GritLM("GritLM/GritLM-7B", torch_dtype="auto")
instruction = "Given a scientific paper title, retrieve the paper's abstract"
queries = ['Bitcoin: A Peer-to-Peer Electronic Cash System', 'Generative Representational Instruction Tuning']
documents = [
"A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution...",
"All text-based language problems can be reduced to either generation or embedding. Current models only perform well at one or the other..."
]
d_rep = model.encode(documents, instruction=gritlm_instruction(""))
q_rep = model.encode(queries, instruction=gritlm_instruction(instruction))
# 计算余弦相似度...
- 文本生成:
messages = [
{"role": "user", "content": "Please write me a poem about my recent hike of Mt. Fuji at midnight in the style of Shakespeare."},
]
encoded = model.tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
encoded = encoded.to(model.device)
gen = model.generate(encoded, max_new_tokens=256, do_sample=False)
decoded = model.tokenizer.batch_decode(gen)
print(decoded[0])
这些例子展示了GritLM在不同任务中的灵活应用能力。
GritLM的未来发展
GritLM的成功为自然语言处理领域开辟了新的研究方向。未来,我们可能会看到:
-
更大规模的统一模型: 随着计算资源的增加,可能会出现更大、更强大的GritLM版本。
-
跨模态应用: GRIT技术可能会扩展到处理图像、音频等多模态数据。
-
特定领域的优化: 针对医疗、法律等特定领域的GritLM变体可能会出现。
-
更高效的训练方法: 研究人员可能会开发出更高效的GRIT训练技术,进一步提升模型性能。
结论
GritLM代表了自然语言处理领域的一个重要里程碑。通过统一生成和表示学习任务,它不仅提高了模型的效率和性能,还为未来的研究和应用开辟了新的可能性。随着技术的不断发展,我们可以期待看到更多基于GRIT的创新应用,进一步推动人工智能在理解和生成人类语言方面的能力。
GritLM的开源性质也意味着整个AI社区都可以参与到这项技术的改进和应用中来。无论是研究人员、开发者还是企业用户,都可以利用GritLM来探索新的应用场景,推动自然语言处理技术的边界。
随着GritLM的不断发展和完善,我们可以期待看到更多令人兴奋的应用出现在各个领域,从智能客服到创意写作,从信息检索到自动摘要,GritLM都有潜力带来革命性的变化。这个统一的语言模型正在为我们开启一个更智能、更高效的语言处理新时代。









