
Hamilton: 革新数据流处理的开源框架
在当今数据驱动的世界中,高效、可靠地处理大规模数据流已成为许多组织面临的关键挑战。为了应对这一挑战,一个名为Hamilton的开源框架应运而生,它正在革新数据科学家和工程师构建数据转换流程的方式。
Hamilton的核心理念
Hamilton是一个轻量级的Python库,专门用于构建有向无环图(DAG)的数据转换流程。它的核心理念是通过简单的Python函数定义来实现可读性强、易于理解的DAG。这种方法不仅提高了代码的可维护性,还使得整个数据处理流程更加透明和可追踪。
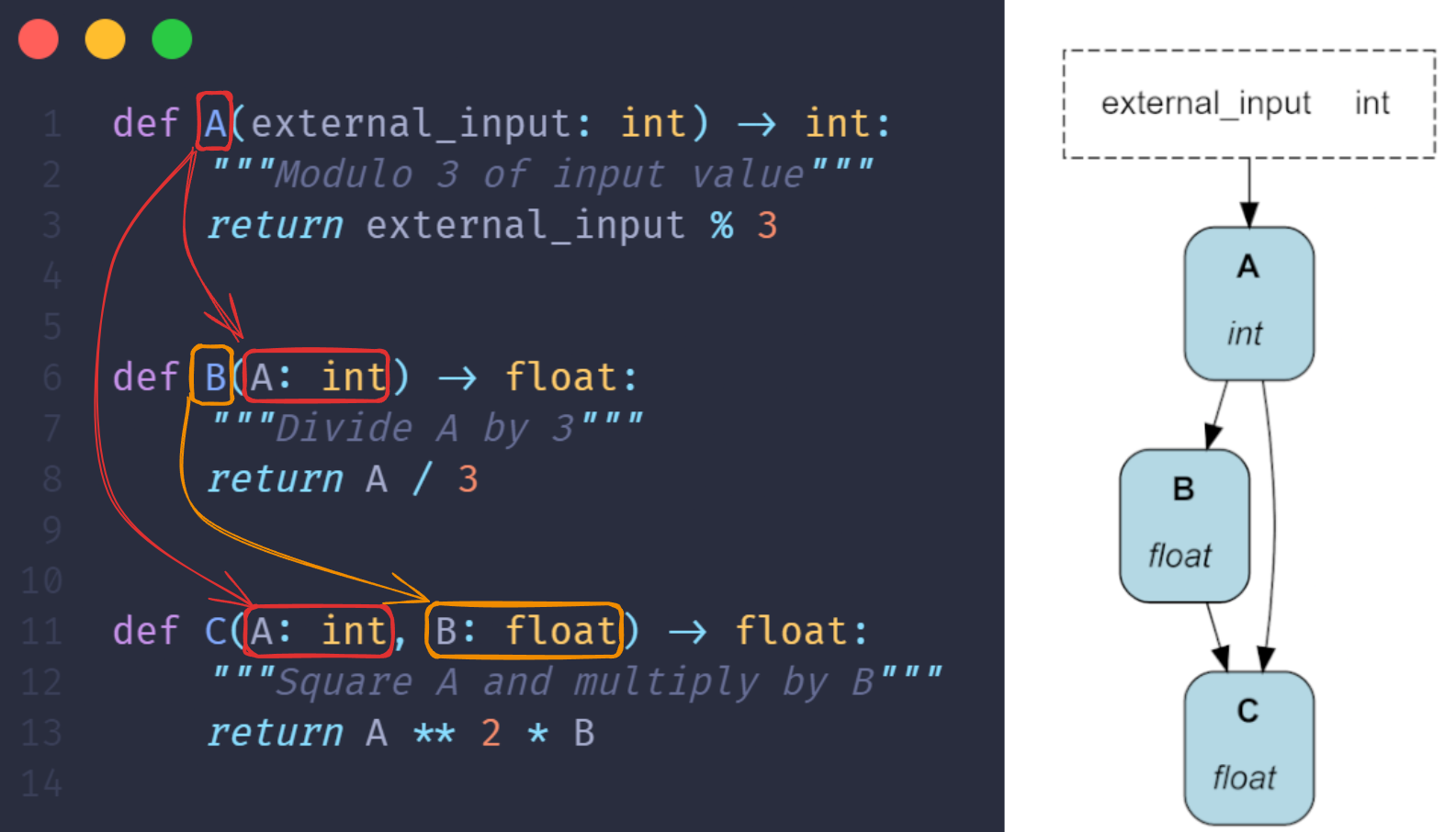
如上图所示,Hamilton允许开发者通过函数参数来明确定义数据依赖关系。这种直观的方式使得即使是复杂的数据流程也能被清晰地表达和理解。
Hamilton的主要特性
-
模块化设计: Hamilton鼓励将数据转换拆分成小型、独立的函数,这大大提高了代码的复用性和可测试性。
-
自动DAG构建: 基于函数定义,Hamilton能自动构建整个数据流的DAG,无需手动指定节点间的关系。
-
可视化能力: Hamilton提供了强大的可视化工具,使得复杂的数据流程变得一目了然。
-
灵活性: 它可以在任何Python环境中运行,从本地脚本到大规模生产环境都适用。
-
内置数据验证: Hamilton支持在数据流中添加验证逻辑,确保数据质量。
-
丰富的生态系统: 它与多种数据处理库(如pandas、polars等)兼容,并提供了丰富的插件支持。
Hamilton UI: 增强可视化和监控
为了进一步提升用户体验,Hamilton团队开发了Hamilton UI。这是一个强大的可视化和监控工具,它提供了以下关键功能:
-
自动数据目录: Hamilton UI自动生成数据流中各节点的目录,包括血缘关系和元数据。
-
执行监控: 实时追踪DAG的执行过程,快速定位潜在问题。
-
结果检查: 方便地查看和分析每个节点的输出结果。
-
错误调试: 提供详细的错误信息,加速问题诊断和修复。
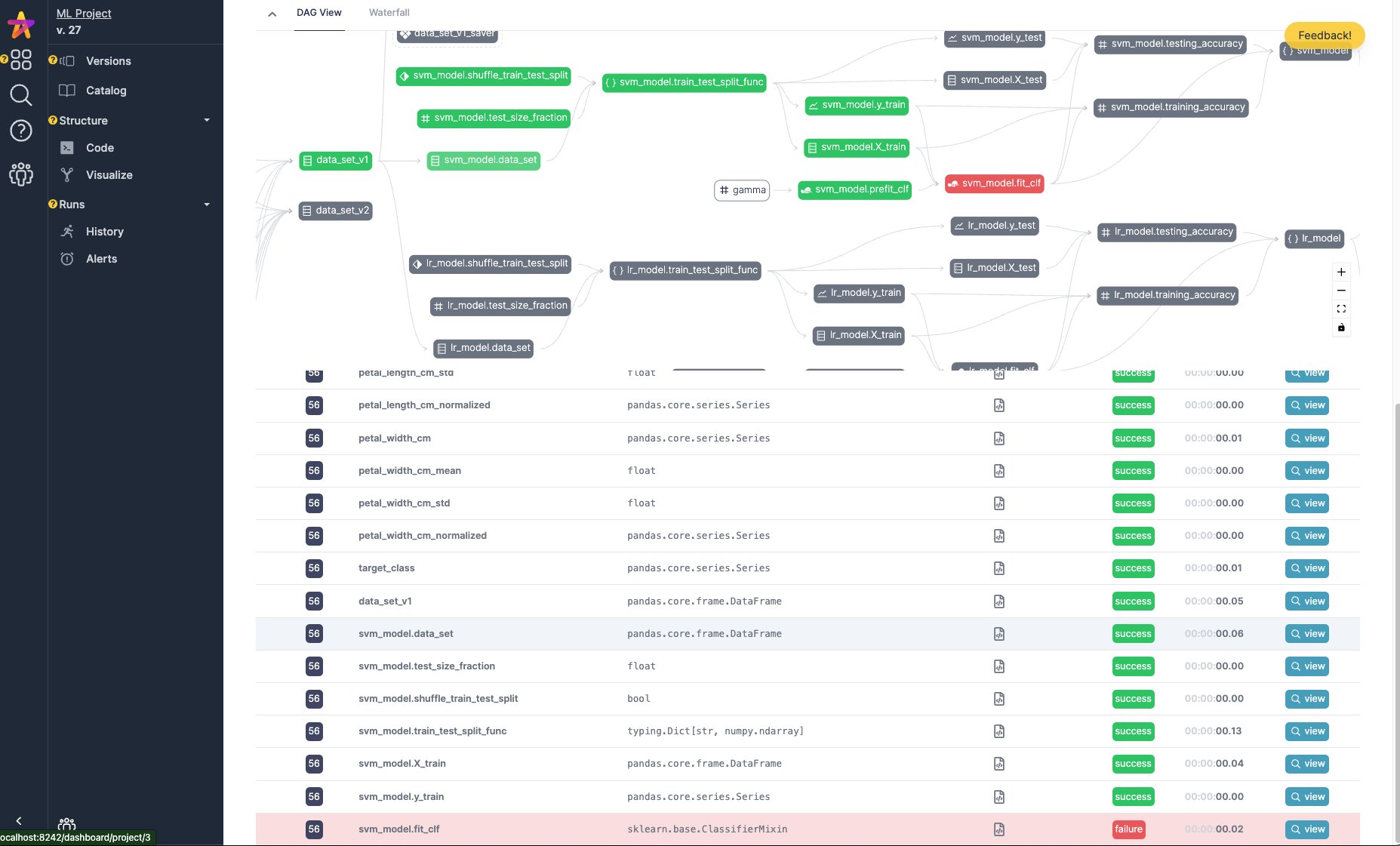
Hamilton的应用场景
Hamilton的灵活性使其适用于多种数据处理场景:
-
ETL流程: 用于构建复杂的数据提取、转换和加载流程。
-
机器学习工作流: 从特征工程到模型训练,Hamilton都能胜任。
-
大语言模型(LLM)应用: 用于构建和管理LLM的处理流程。
-
RAG系统: 在检索增强生成(RAG)系统中管理数据流。
-
商业智能(BI)仪表板: 用于数据准备和转换,为BI工具提供支持。
Hamilton的优势
-
关注点分离: Hamilton将DAG的'定义'和'执行'分开,使数据科学家和工程师能各司其职。
-
协作效率: 通过Hamilton UI,团队成员可以共享接口,更好地协作和调试。
-
从开发到生产的平滑过渡: 使用
@config.when()修饰器可以轻松管理不同环境间的DAG变化。 -
可移植性: Hamilton定义的DAG独立于底层基础设施,可在不同环境间轻松迁移。
-
代码质量提升: Hamilton鼓励模块化、可测试的代码风格,有助于提高整体代码质量。
社区支持和发展
Hamilton拥有活跃的开源社区,得到了众多知名企业的支持和使用,如Stitch Fix、IBM、Adobe等。这种广泛的采用不仅验证了Hamilton的价值,也为其持续发展提供了动力。
社区贡献者通过GitHub不断完善Hamilton的功能,解决问题,并提供新的集成方案。Hamilton团队也通过Slack社区、博客和YouTube频道等多种渠道与用户保持密切互动。
结语
Hamilton作为一个创新的数据流处理框架,正在改变数据科学家和工程师构建和管理复杂数据流程的方式。通过其简洁而强大的设计理念,Hamilton不仅提高了开发效率,还大大增强了数据流程的可维护性和可扩展性。
随着数据处理需求的不断增长和复杂化,Hamilton这样的工具将在未来的数据生态系统中扮演越来越重要的角色。无论是初创公司还是大型企业,都可以从Hamilton带来的效率提升和创新中受益。
对于那些希望优化数据处理流程,提高团队协作效率,或者simply寻求更好的数据工程实践的组织来说,Hamilton无疑是一个值得深入探索的强大工具。
通过采用Hamilton,您将踏上一段令人兴奋的数据处理之旅,发现更高效、更可靠的数据转换方法。让我们共同期待Hamilton在数据科学和工程领域带来的更多创新和突破。









