
 访问官网
访问官网 Github
Github 文档
文档 论文
论文 Hamilton — 便携式且富有表现力的
Hamilton — 便携式且富有表现力的
数据转换有向无环图(DAG)






Hamilton是一个轻量级Python库,用于创建数据转换的有向无环图(DAG)。你的DAG是可移植的;它可以在任何运行Python的地方运行,无论是脚本、笔记本、Airflow管道还是FastAPI服务器等。你的DAG是富有表现力的;Hamilton具有广泛的功能来定义和修改DAG的执行(例如,数据验证、实验跟踪、远程执行)。
要创建DAG,只需编写常规的Python函数,并通过参数指定它们的依赖关系。如下所示,这将产生可读性强且随时可视化的代码。Hamilton会加载该定义并自动为你构建DAG!
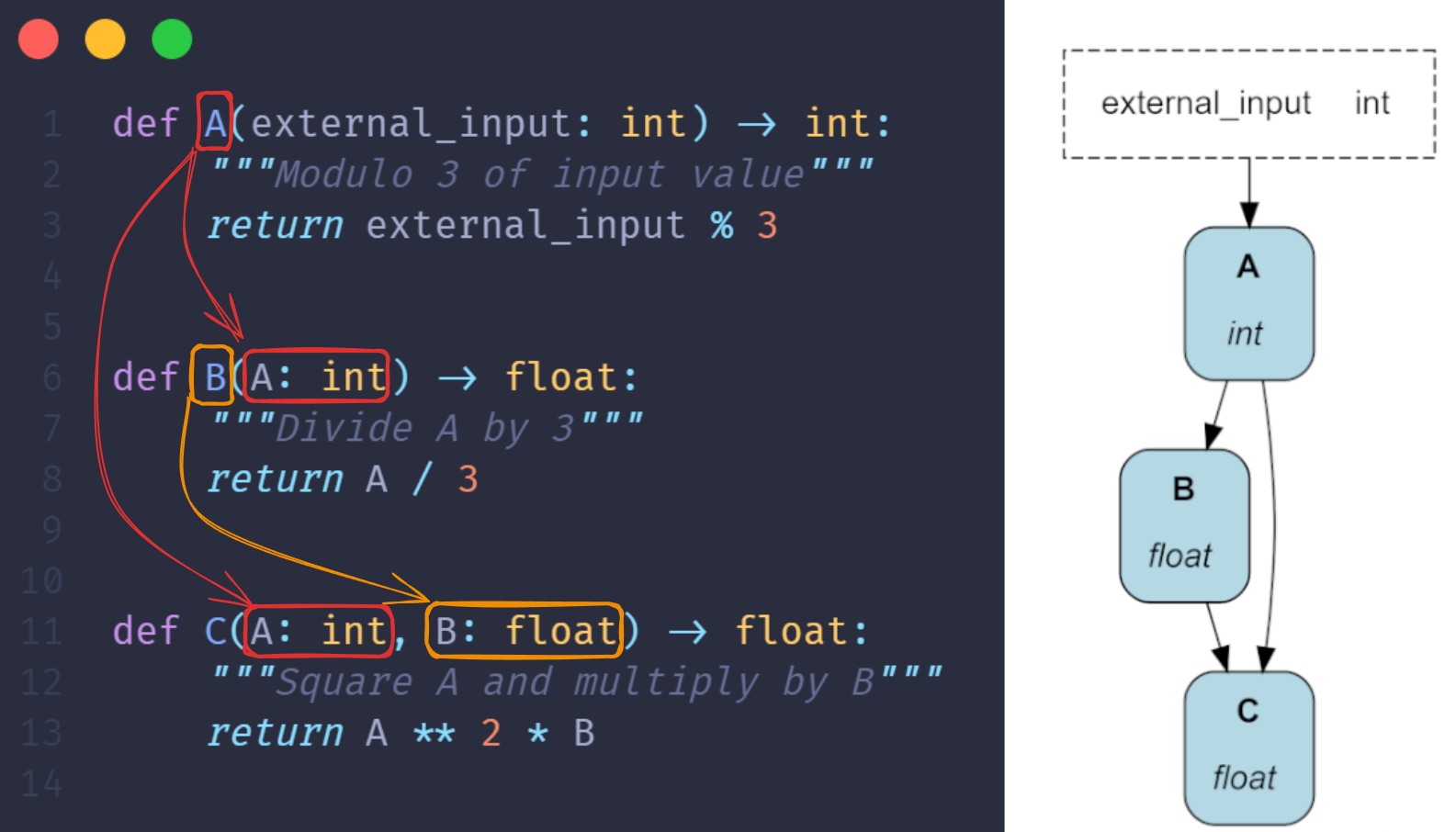
B()和C()通过它们的参数引用函数A
Hamilton为任何处理数据的Python应用程序带来模块化和结构化:ETL管道、ML工作流、LLM应用、RAG系统、BI仪表板,而Hamilton UI允许你自动可视化、编目和监控执行。
Hamilton非常适合DAG,但如果你需要循环或条件逻辑来创建LLM代理或模拟,请查看我们的姐妹库 Burr 🤖 。
安装
Hamilton支持Python 3.8+。我们包含了可选的visualization依赖项以显示Hamilton DAG。对于可视化,需要在系统上单独安装Graphviz。
pip install "sf-hamilton[visualization]"
要使用Hamilton UI,请安装ui和sdk依赖项。
pip install "sf-hamilton[ui,sdk]"
要在浏览器中试用Hamilton,请访问 www.tryhamilton.dev
为什么使用Hamilton?
数据团队编写代码以提供业务价值,但很少有团队有资源来标准化实践并提供质量保证。从概念验证到生产以及跨职能协作(例如,数据科学、工程、运维)对于大小团队来说仍然具有挑战性。Hamilton旨在帮助项目的整个生命周期:
-
关注点分离。Hamilton将DAG的"定义"和"执行"分开,让数据科学家专注于解决问题,工程师管理生产管道。
-
有效协作。Hamilton UI提供了一个共享接口,供团队在整个开发周期中检查结果和调试故障。
-
从开发到生产的低摩擦。使用
@config.when()在执行环境之间修改DAG,而不是容易出错的if/else功能标志。笔记本扩展避免了将代码从笔记本迁移到Python模块的痛苦。 -
可移植的转换。你的DAG独立于基础设施或编排,这意味着你可以在本地开发和调试,并在不同环境中重用代码(本地、Airflow、FastAPI等)。
-
可维护的DAG定义。Hamilton通过一行代码自动构建DAG,无论它有10个还是1000个节点。它还可以将多个Python模块组装成一个管道,鼓励模块化。
-
富有表现力的DAG。函数修饰符是一个独特的功能,可以保持代码DRY并减少维护大型DAG的复杂性。其他框架不可避免地会导致代码冗余或函数臃肿。
-
内置编码风格。Hamilton DAG使用Python函数定义,鼓励模块化、易读、自文档化和可单元测试的代码。
-
数据和模式验证。使用
@check_output装饰函数以验证输出属性,并引发警告或异常。添加SchemaValidator()适配器以自动检查类似数据框的对象(pandas、polars、Ibis等),以跟踪和验证它们的模式。 -
为插件而生。Hamilton 的设计可以与所有工具完美配合,并提供了合适的抽象来创建与您的技术栈的自定义集成。我们活跃的社区将帮助您构建所需的一切!
Hamilton 用户界面
您可以在 Hamilton 用户界面 中跟踪 Hamilton DAG 的执行情况。它会自动填充包含血缘关系/追踪的数据目录,并提供执行可观察性以检查结果和调试错误。您可以将其作为本地服务器运行,或作为使用 Docker 的自托管应用程序运行。
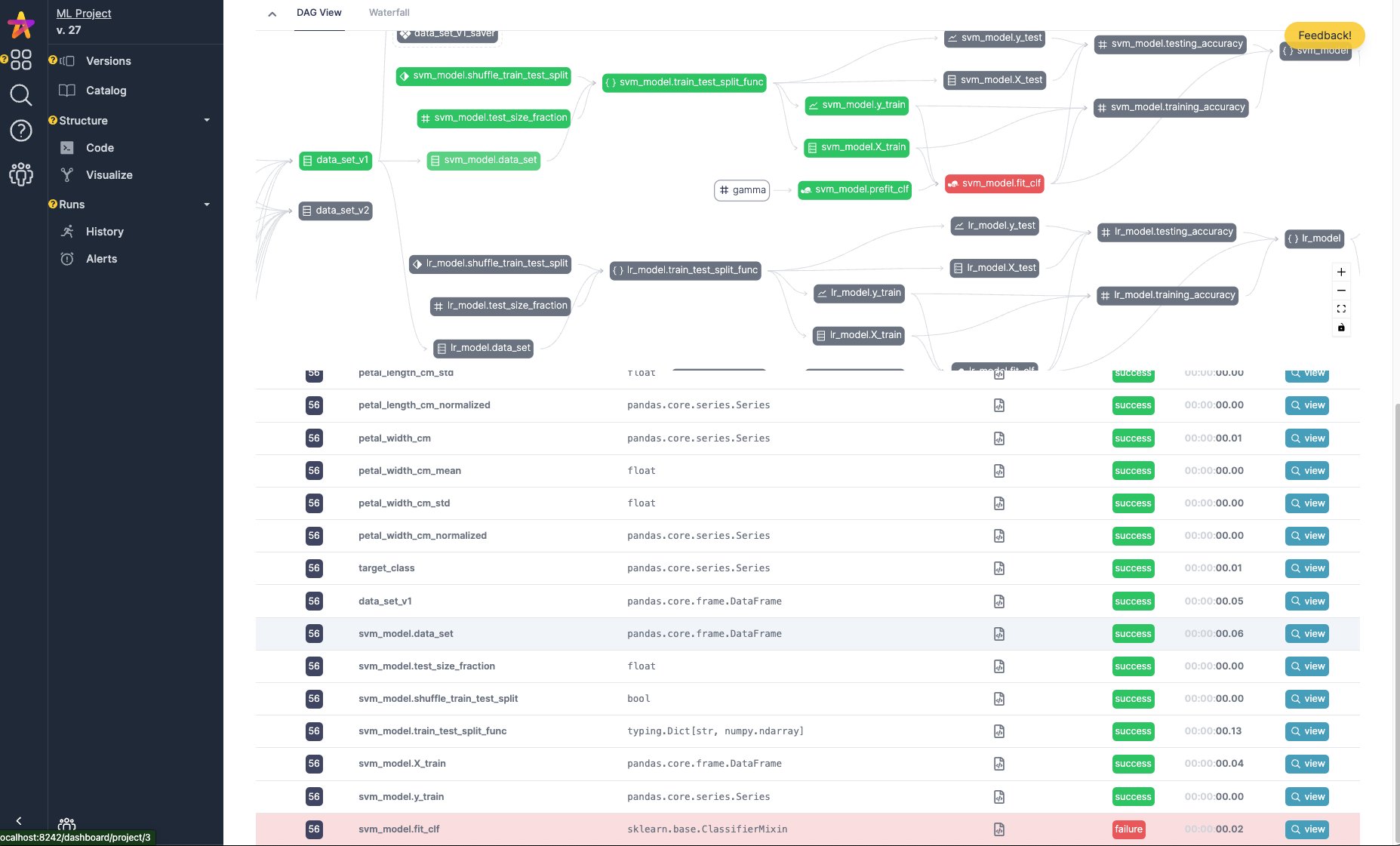
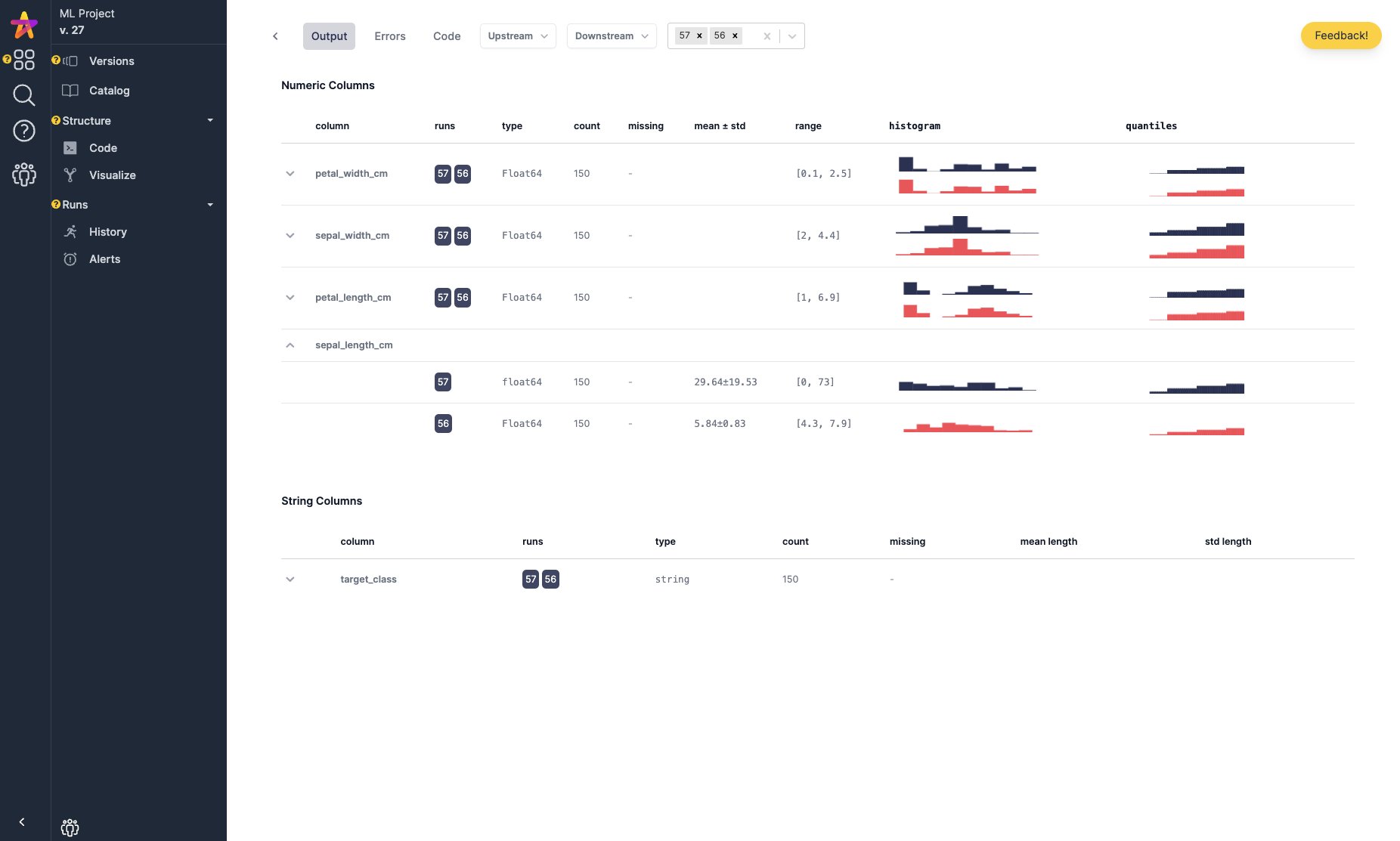
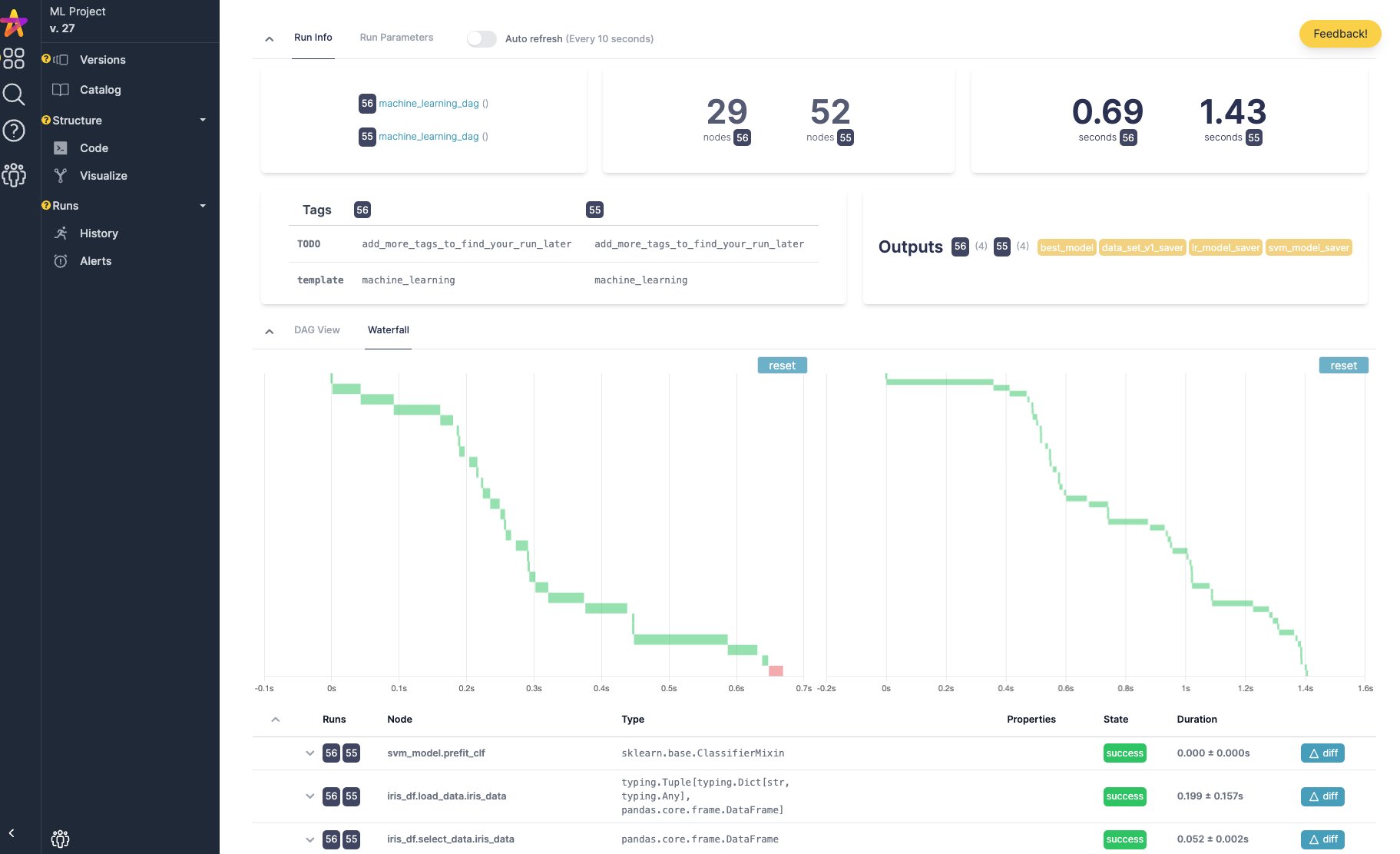
DAG 目录、自动数据集分析和执行跟踪
开始使用 Hamilton 用户界面
-
要使用 Hamilton 用户界面,请安装依赖项(参见"安装"部分)并使用以下命令启动服务器:
hamilton ui -
首次连接时,创建一个"用户名"和一个新项目("project_id"应为"1")。
-
通过创建一个包含您的"用户名"和"project_id"的"HamiltonTracker"对象并将其添加到您的"Builder"中来跟踪您的 Hamilton DAG。现在,您的 DAG 将出现在用户界面的目录中,所有执行都将被跟踪!
from hamilton import driver from hamilton_sdk.adapters import HamiltonTracker import my_dag # 使用您的"用户名"和"project_id" tracker = HamiltonTracker( username="my_username", project_id=1, dag_name="hello_world", ) # 将跟踪器添加到"Builder"中,这将把 DAG 添加到目录中 dr = ( driver.Builder() .with_modules(my_dag) .with_adapters(tracker) # 在这里添加您的跟踪器 .build() ) # 执行"Driver"将跟踪结果 dr.execute(["C"])
文档和学习资源
-
📚 查看官方文档了解 Hamilton 的核心概念。
-
👨🏫 参考 GitHub 上的示例了解特定功能或与其他框架的集成。
-
📰 DAGWorks 博客包括如何构建数据平台的指南和叙述性教程。
-
📺 在 DAGWorks YouTube 频道上查找视频教程。
-
📣 通过 Hamilton Slack 社区寻求帮助和故障排除。
Hamilton 与 X 的比较
Hamilton 不是一个编排工具(您可能不需要一个),也不是一个特征存储(但您可以用它来构建一个!)。它的目的是帮助您构建和管理数据转换。如果您了解 dbt,Hamilton 对 Python 的作用就像 dbt 对 SQL 的作用一样。
另一种理解方式是考虑数据栈的不同层。Hamilton 位于资产层。它帮助您组织数据转换代码(表达层),管理变更,以及验证和测试数据。
| 层 | 目的 | 示例工具 |
|---|---|---|
| 编排 | 资产创建的操作系统 | Airflow, Metaflow, Prefect, Dagster |
| 资产 | 将表达式组织成有意义的单元 (如数据集、ML 模型、表格) | Hamilton, dbt, dlt, SQLMesh, Burr |
| 表达 | 编写数据转换的语言 | pandas, SQL, polars, Ibis, LangChain |
| 执行 | 执行数据转换 | Spark, Snowflake, DuckDB, RAPIDS |
| 数据 | 数据的物理表示,输入和输出 | S3, Postgres, 文件系统, Snowflake |
有关更多信息,请参阅我们的为什么使用 Hamilton?页面和框架代码比较。
📑 许可证
Hamilton 在 BSD 3-Clause Clear 许可下发布。详情请参阅 LICENSE。
🌎 社区
👨💻 贡献
我们非常支持新贡献者的改变,无论大小!在打开拉取请求之前,请务必通过创建问题或在现有问题上发表评论来讨论潜在的更改。好的首次贡献包括创建示例或与您喜欢的 Python 库的集成! 要贡献代码,请查看我们的贡献指南、开发者设置指南和行为准则。
😎 使用者
Hamilton最初由Stitch Fix开发,后来原始创建者成立了DAGWorks Inc!该库经过实战检验,自2019年以来一直支持生产用例。
阅读更多关于起源故事。
- Stitch Fix — 时间序列预测
- 英国政府数字服务 — 国家反馈管道(处理和分析)
- IBM — 内部搜索和机器学习管道
- Opendoor — 管理PySpark管道
- Lexis Nexis — 特征处理和血缘关系
- Adobe — 提示工程研究
- WrenAI — 异步文本到SQL工作流
- 英国自行车协会 — 遥测分析
- 橡树岭国家实验室和太平洋西北国家实验室 — Naturf项目
- 橡树岭国家实验室
- 美联储
- Joby Aviation — 飞行数据处理
- Two
- Transfix — 在线特征化和预测
- Railofy — 编排pandas代码
- Habitat Energy — 时间序列特征工程
- KI-Insurance — 特征工程
- Ascena Retail — 特征工程
- NaroHQ
- EquipmentShare
- Everstream.ai
- Flectere
- F33.ai
🤝 代码贡献者
🙌 特别鸣谢 & 🦟 Bug猎人
感谢我们出色的社区及其对Hamilton库的积极参与。
Nils Olsson, Michał Siedlaczek, Alaa Abedrabbo, Shreya Datar, Baldo Faieta, Anwar Brini, Gourav Kumar, Amos Aikman, Ankush Kundaliya, David Weselowski, Peter Robinson, Seth Stokes, Louis Maddox, Stephen Bias, Anup Joseph, Jan Hurst, Flavia Santos, Nicolas Huray, Manabu Niseki, Kyle Pounder, Alex Bustos, Andy Day, Alexander Cai, Nils Müller-Wendt, Paul Larsen, Kemal Eren, Jernej Frank, Noah Ridge
🎓 引用
我们感谢通过引用以下内容之一来引用Hamilton:
@inproceedings{DBLP:conf/vldb/KrawczykI22,
title = {Hamilton: a modular open source declarative paradigm for high level
modeling of dataflows},
author = {Stefan Krawczyk and Elijah ben Izzy},
editor = {Satyanarayana R. Valluri and Mohamed Za{\"{\i}}t},
booktitle = {1st International Workshop on Composable Data Management Systems,
CDMS@VLDB 2022, Sydney, Australia, September 9, 2022},
year = {2022},
url = {https://cdmsworkshop.github.io/2022/Proceedings/ShortPapers/Paper6\_StefanKrawczyk.pdf},
timestamp = {Wed, 19 Oct 2022 16:20:48 +0200},
biburl = {https://dblp.org/rec/conf/vldb/KrawczykI22.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@inproceedings{CEURWS:conf/vldb/KrawczykIQ22,
title = {Hamilton: enabling software engineering best practices for data transformations via generalized dataflow graphs},
author = {Stefan Krawczyk and Elijah ben Izzy and Danielle Quinn},
editor = {Cinzia Cappiello and Sandra Geisler and Maria-Esther Vidal},
booktitle = {1st International Workshop on Data Ecosystems co-located with 48th International Conference on Very Large Databases (VLDB 2022)},
pages = {41--50},
url = {https://ceur-ws.org/Vol-3306/paper5.pdf},
year = {2022}
}











