
ImageBind:融合多模态数据的统一嵌入空间
在人工智能和计算机视觉领域,研究人员一直在探索如何更好地处理和理解不同类型的数据。近日,Meta AI研究团队推出了一种突破性的模型——ImageBind,它能够将多种不同模态的数据统一到一个嵌入空间中,为多模态人工智能的发展开辟了新的方向。
ImageBind的核心理念
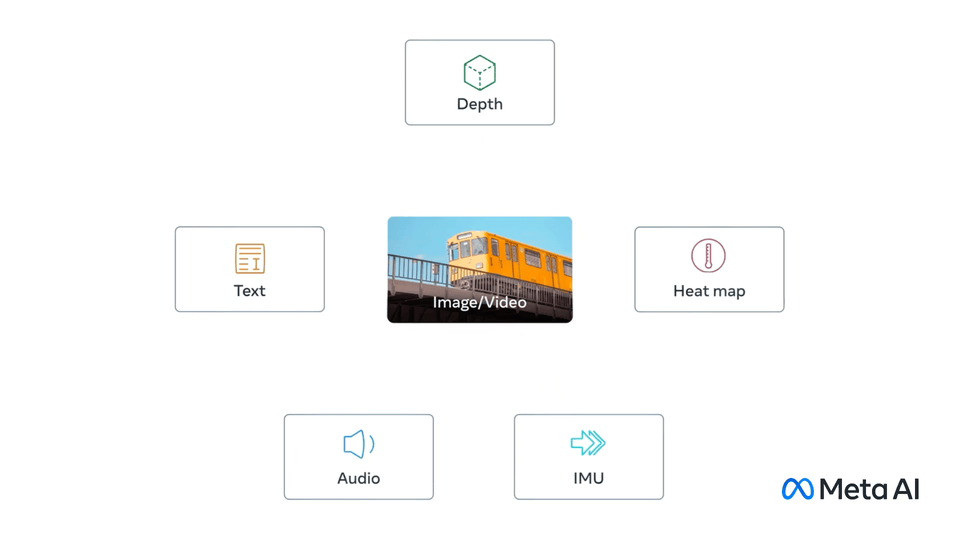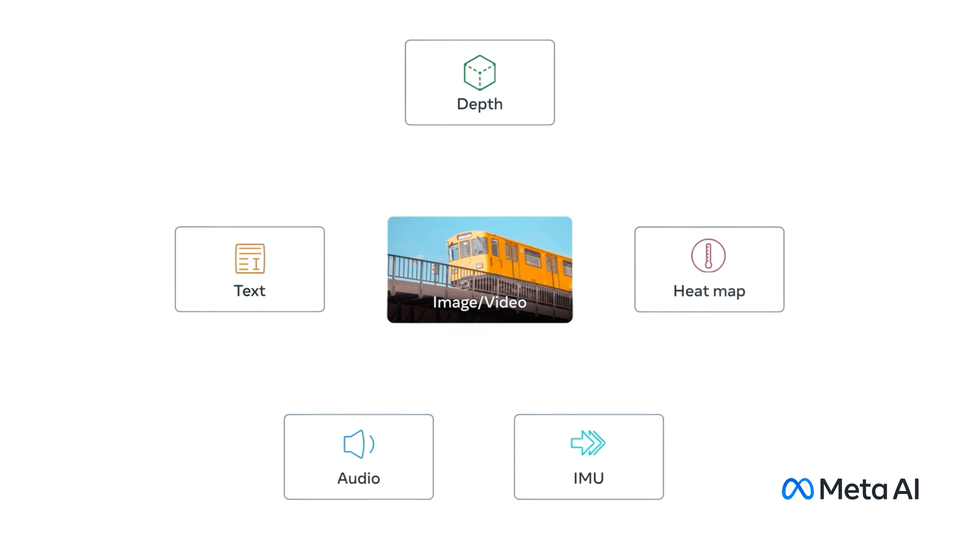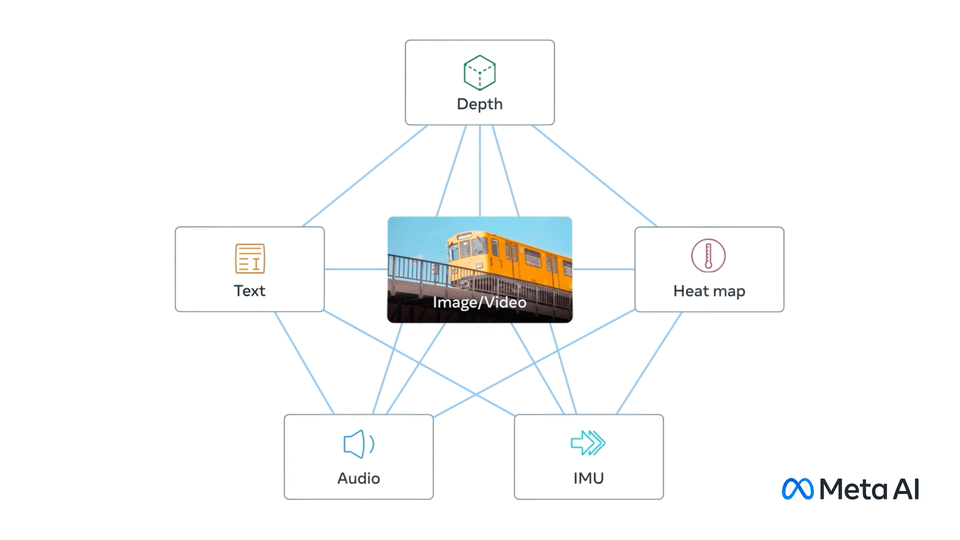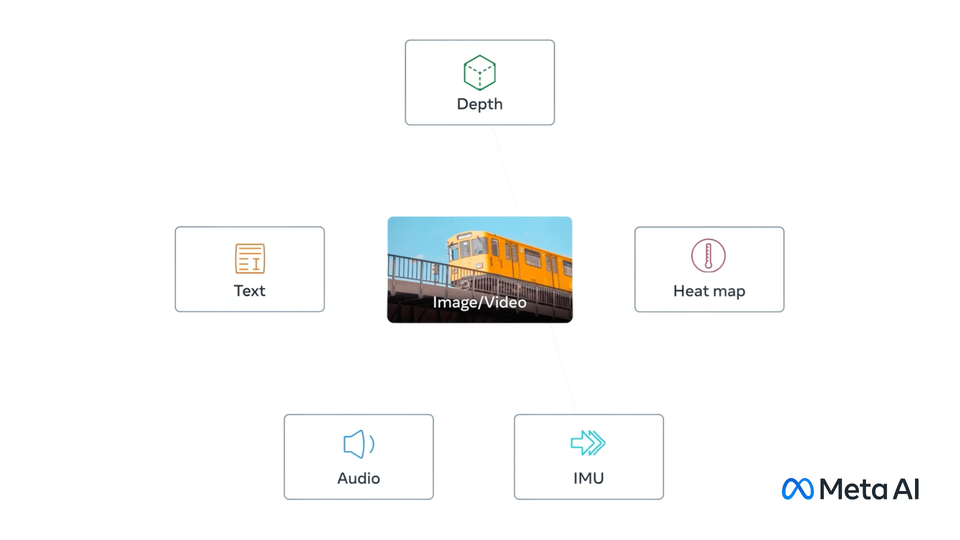
ImageBind的核心理念是创建一个统一的嵌入空间,将图像、文本、音频、深度、热成像和IMU(惯性测量单元)数据等六种不同模态的信息融合在一起。这种方法的独特之处在于,它只需要图像配对数据就可以将所有模态绑定在一起,无需显式地训练所有模态组合。
这种创新性的设计使得ImageBind能够利用现有的大规模视觉-语言模型,并将其零样本能力扩展到新的模态。简单来说,ImageBind通过图像作为"桥梁",让不同类型的数据能够在同一个空间中进行比较和交互。
ImageBind的技术实现
从技术实现的角度来看,ImageBind采用了基于Transformer架构的模态编码器。具体来说:
- 图像和视频使用Vision Transformer (ViT)进行编码
- 音频通过将2秒音频样本转换为频谱图,然后使用ViT进行处理
- 热成像和深度图像被视为单通道图像,同样使用ViT编码
- IMU信号首先通过1D卷积进行投影,然后由Transformer编码
- 文本编码沿用了CLIP模型的设计
每种模态都有自己专门的编码器,并添加了一个特定于模态的线性投影头,以获得固定大小的嵌入。这种设计不仅简化了学习过程,还允许使用预训练模型(如CLIP或OpenCLIP)来初始化部分编码器。
ImageBind的应用场景
ImageBind的出现为多模态AI带来了许多新颖而强大的应用场景:
-
跨模态检索: 用户可以使用一种模态的数据(如音频)来检索另一种模态的相关文档(如视频)。例如,自然爱好者可以通过上传鸟叫声音频来检索相关的鸟类图像。
-
模态算术: ImageBind允许将不同模态的嵌入进行算术运算。例如,将水果图像的嵌入与鸟叫声音频的嵌入相加,可能会检索到一张有鸟和果树的图像。
-
跨模态检测: 通过替换现有视觉模型中的文本嵌入为ImageBind的音频嵌入,可以实现基于音频提示的物体检测和分割。
-
跨模态生成: 同样的原理也可以应用于生成模型,例如使用音频嵌入来驱动图像生成模型,直接从声音生成相应的图像。
ImageBind的性能表现
在零样本分类任务中,ImageBind展现出了卓越的性能:
| 模型 | IN1k | K400 | NYU-D | ESC | LLVIP | Ego4D |
|---|---|---|---|---|---|---|
| imagebind_huge | 77.7 | 50.0 | 54.0 | 66.9 | 63.4 | 25.0 |
这些结果表明,ImageBind在各种数据集上都取得了显著的进展,甚至超越了一些专门为特定模态训练的监督模型。
如何使用ImageBind
对于想要尝试ImageBind的研究人员和开发者,Meta AI团队已经开源了相关代码和预训练模型。以下是使用ImageBind的基本步骤:
- 首先,安装PyTorch 1.13+和其他依赖项:
conda create --name imagebind python=3.10 -y
conda activate imagebind
pip install .
- 然后,可以使用以下示例代码来提取和比较不同模态的特征:
from imagebind import data
import torch
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
# 准备输入数据
text_list = ["A dog.", "A car", "A bird"]
image_paths = [".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths = [".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 实例化模型
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# 加载数据
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
# 获取嵌入
with torch.no_grad():
embeddings = model(inputs)
# 计算相似度
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
ImageBind的未来展望
ImageBind的出现无疑为多模态AI的发展开辟了新的道路。未来,我们可以期待:
-
更广泛的模态支持: 随着研究的深入,ImageBind可能会扩展到支持更多类型的数据模态。
-
性能的进一步提升: 通过改进模型架构和训练方法,ImageBind的性能有望得到进一步提升。
-
更多创新应用: ImageBind为跨模态交互提供了新的可能性,未来可能会涌现出更多创新的应用场景。
-
与其他AI技术的结合: ImageBind可能会与其他先进的AI技术(如大型语言模型)结合,创造出更强大的多模态AI系统。
总的来说,ImageBind代表了多模态AI研究的一个重要里程碑。它不仅展示了将不同类型的数据统一到一个嵌入空间的可能性,还为未来的AI系统如何更全面地理解和处理多模态信息提供了新的思路。随着这项技术的不断发展和完善,我们有理由期待它将在计算机视觉、自然语言处理、音频分析等多个领域带来革命性的变革。













