
Mistral-7B模型简介
Mistral-7B是一个开源的大型语言模型,由Mistral AI公司开发。作为一个规模相对较小但性能出色的模型,Mistral-7B在自然语言处理领域引起了广泛关注。该模型在参数量和性能之间取得了很好的平衡,为开发者和研究人员提供了一个强大而灵活的工具。
Mistral-7B的主要特点包括:
- 7B参数规模,相比GPT-3等超大模型更易部署和使用
- 采用先进的Transformer架构,性能优异
- 开源许可,允许商业使用和修改
- 支持多语言处理能力
- 在各种NLP任务上表现出色
正是由于Mistral-7B的这些优势,使得它成为了微调和定制化的理想选择。通过微调,我们可以让Mistral-7B更好地适应特定领域或任务,发挥出更强大的能力。
微调的意义与挑战
微调(Fine-tuning)是一种迁移学习技术,它允许我们在预训练模型的基础上,使用特定领域的数据进行进一步训练,从而使模型更好地适应特定任务或领域。对Mistral-7B进行微调有以下几个重要意义:
- 提高模型在特定领域的性能
- 使模型学习特定的语言风格或知识
- 减少模型的幻觉(hallucination)现象
- 优化模型对特定任务的处理能力
然而,微调Mistral-7B也面临着一些挑战:
- 计算资源需求高
- 需要高质量的训练数据
- 容易出现过拟合问题
- 参数调优复杂
为了克服这些挑战,研究人员和开发者们提出了多种优化方法,其中最受欢迎的是LoRA(Low-Rank Adaptation)技术。
LoRA技术简介
LoRA是一种高效的参数高效微调方法,它通过引入低秩矩阵来减少需要更新的参数数量,从而大大降低了计算资源的需求。使用LoRA进行Mistral-7B的微调有以下优势:
- 显著减少显存占用,使得在消费级GPU上也能进行微调
- 加快训练速度,节省时间和成本
- 降低过拟合风险
- 保持模型的泛化能力
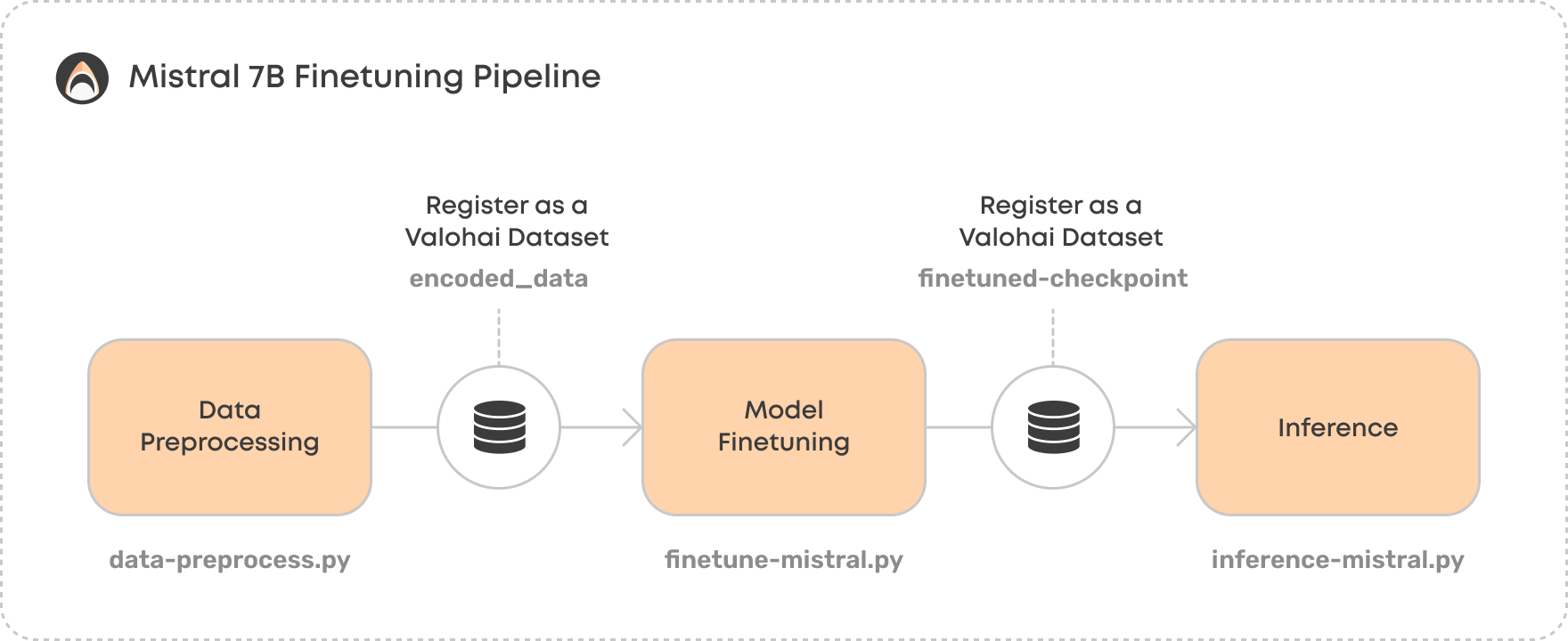
Mistral-7B微调实践
接下来,我们将介绍如何使用LoRA技术对Mistral-7B进行微调。整个过程可以分为以下几个步骤:
1. 数据准备
数据质量对微调效果至关重要。我们需要准备符合特定任务或领域的高质量数据集。以下是一些数据准备的建议:
- 确保数据的多样性和代表性
- 清洗和预处理数据,去除噪声
- 根据任务类型设计合适的数据格式
- 考虑数据增强技术,扩大数据集规模
2. 环境配置
为了顺利进行微调,我们需要配置适当的软硬件环境:
- 硬件: 推荐使用NVIDIA GPU,至少16GB显存
- 软件: Python 3.7+, PyTorch 1.8+, Transformers库等
- 依赖安装:
pip install transformers torch accelerate bitsandbytes
3. 模型加载与配置
使用Hugging Face的Transformers库加载Mistral-7B模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
4. LoRA配置
配置LoRA参数:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
5. 训练过程
使用Hugging Face的Trainer API进行训练:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=1000,
save_total_limit=2,
learning_rate=2e-5,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
trainer.train()
6. 评估与优化
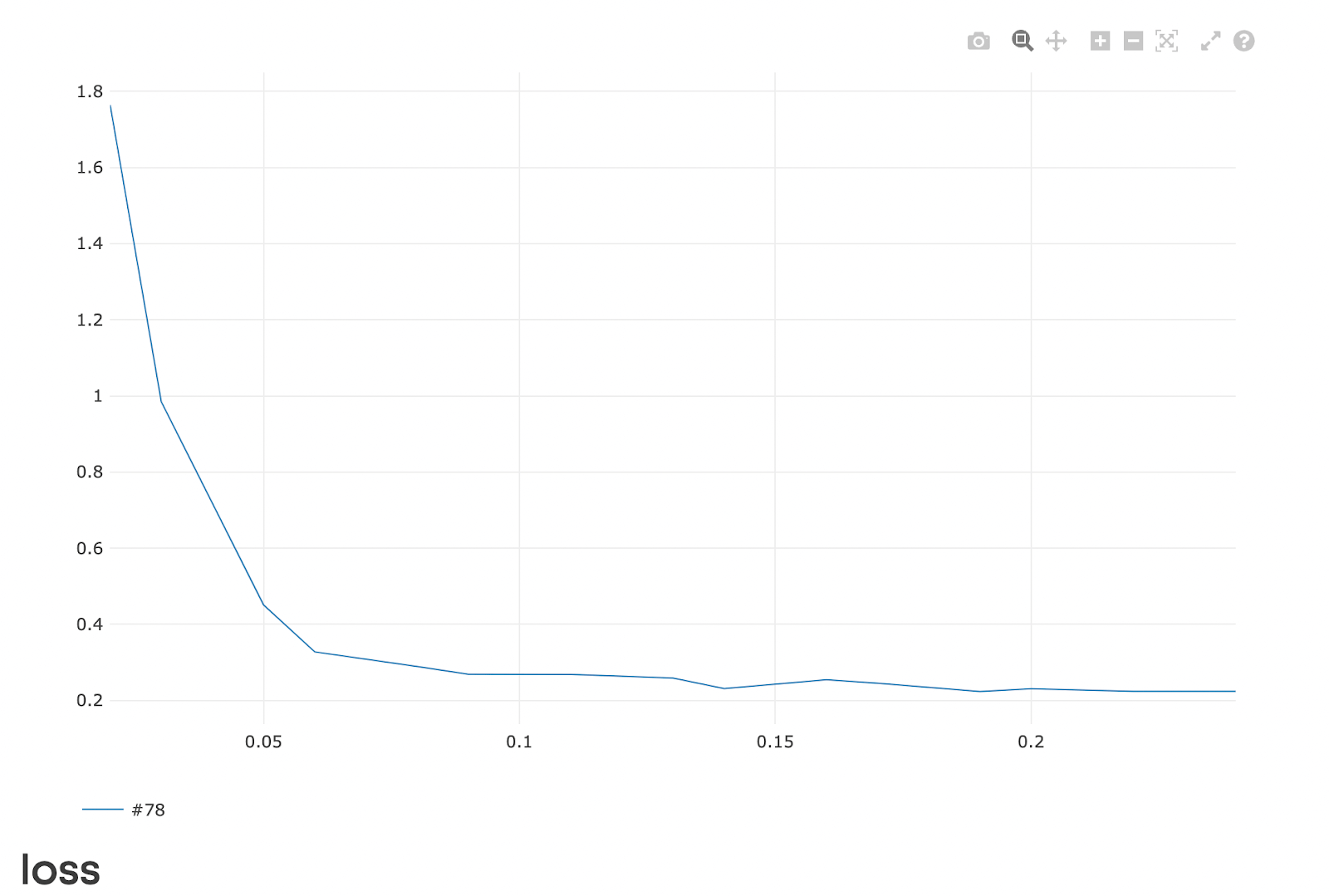
在微调过程中和完成后,我们需要对模型进行评估,并根据结果进行进一步优化:
- 使用验证集评估模型性能
- 分析损失曲线,检测过拟合现象
- 尝试调整学习率、batch size等超参数
- 考虑使用学习率调度器等高级技巧
实际应用案例
为了更好地理解Mistral-7B微调的实际效果,让我们来看一个具体的应用案例。假设我们要将Mistral-7B微调成一个专门用于回答医疗健康问题的助手。
- 数据准备:收集大量医疗健康相关的问答对。
- 微调过程:使用LoRA技术对Mistral-7B进行微调,重点关注医疗术语和专业知识的理解。
- 评估:使用专业的医疗问题测试集进行评估,确保模型能够准确回答各种健康咨询。
微调前后的对比:
问题: 高血压患者应该注意什么?
微调前回答: 高血压患者应该注意控制饮食,减少盐分摄入,保持运动,定期检查血压等。
微调后回答: 作为高血压患者,您需要注意以下几点:
1. 控制钠盐摄入:每日摄入量不超过6克
2. 保持健康饮食:增加蔬菜水果摄入,减少饱和脂肪
3. 规律运动:每周至少150分钟中等强度有氧运动
4. 戒烟限酒:尽量戒烟,男性饮酒不超过25g/天,女性不超过15g/天
5. 减轻体重:将BMI控制在18.5-23.9之间
6. 遵医嘱服药:按时按量服用降压药物
7. 定期监测:每周至少测量2-3次血压
8. 管理压力:学习放松技巧,保持良好心态
9. 控制其他危险因素:如糖尿病、高脂血症等
10. 定期体检:每年至少进行一次全面体检
请记住,这些建议仅供参考,具体方案还需遵医嘱。如有任何不适,请及时就医。
可以看到,微调后的模型在回答医疗问题时,不仅内容更加专业和全面,而且提供了更具体的建议和数据。这种定制化的模型可以在医疗咨询、健康教育等领域发挥重要作用。
未来展望
随着大型语言模型技术的不断发展,Mistral-7B的微调技术也在不断进步。我们可以期待以下几个方面的发展:
- 更高效的微调算法,进一步降低计算资源需求
- 多模态微调技术,结合图像、音频等数据
- 持续学习能力,允许模型在使用过程中不断优化
- 更好的可解释性,理解模型微调后的行为变化
结语
Mistral-7B的微调为我们提供了一种强大的工具,使我们能够将这个优秀的开源语言模型定制化,以满足各种特定需求。通过本文的介绍,我们深入了解了Mistral-7B微调的原理、方法和实践经验。希望这些内容能够帮助读者更好地利用Mistral-7B,开发出更多创新的AI应用。
记住,微调是一个需要不断实践和优化的过程。随着您积累更多经验,您将能够更好地驾驭这项技术,充分发挥Mistral-7B的潜力。让我们一起探索大语言模型的无限可能!





















