
μP: 神经网络超参数调优的革命性突破
在深度学习领域,随着模型规模的不断扩大,如何高效地调优超参数一直是一个巨大的挑战。微软研究院近期提出的 μP (Maximal Update Parametrization) 技术,为这一难题带来了革命性的解决方案。本文将深入介绍 μP 的核心原理、主要优势以及实际应用方法。
μP 的核心思想
μP 的核心思想是通过特殊的参数化方式,使得神经网络的最优超参数在不同的网络规模下保持稳定。这意味着我们可以在小规模网络上找到的最优超参数,直接应用到大规模网络中,而无需重新调优。这种"零样本超参数迁移"的能力,极大地降低了大型神经网络的调优成本。
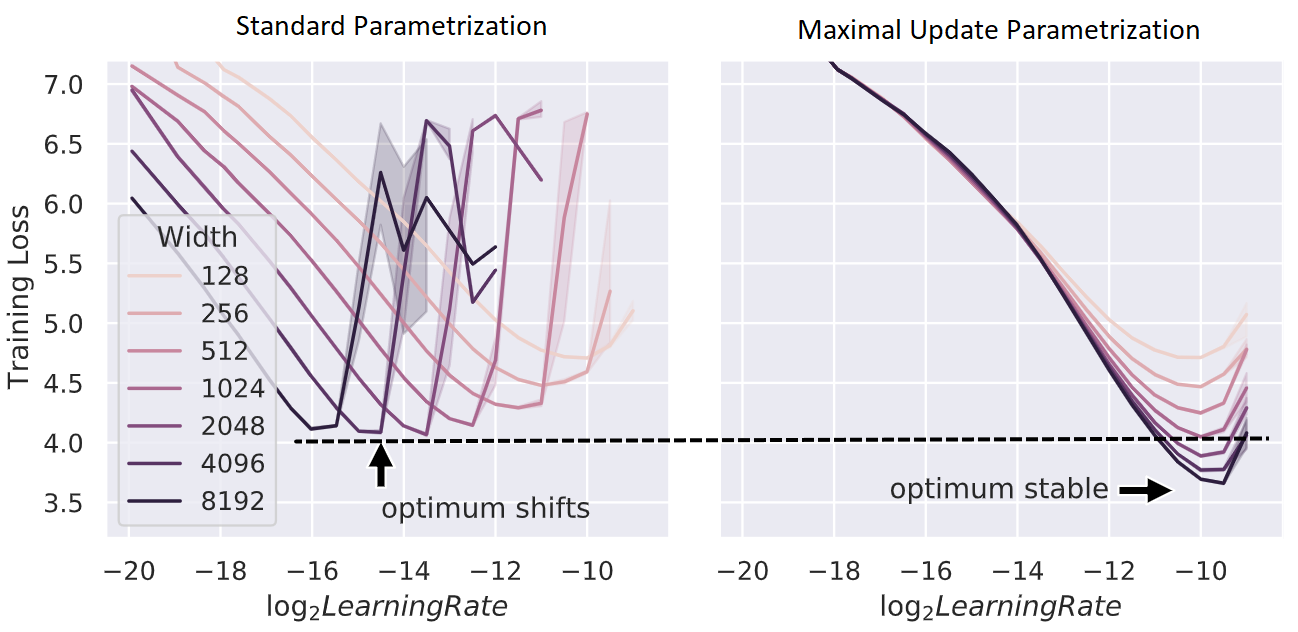
上图展示了 μP 与标准参数化 (SP) 在不同模型大小下的训练损失曲线。可以看到,使用 μP 后,最优学习率在不同模型大小下保持稳定,而 SP 则需要随模型增大而调整学习率。
μP 的主要优势
-
超参数稳定性: μP 使得最优超参数在不同网络规模下保持稳定,实现了真正的"零样本超参数迁移"。
-
降低调优成本: 通过在小规模模型上调优超参数,然后直接应用到大规模模型,极大地降低了计算资源消耗。
-
提高可扩展性: μP 减少了从探索阶段到规模化阶段的不确定性,使得深度学习模型的开发更加可靠和可预测。
-
广泛适用性: μP 可以应用于各种类型的神经网络,包括 MLP、CNN、Transformer 等。
μP 的实现原理
μP 的实现基于以下几个关键设计:
-
特殊的参数初始化: μP 使用经过缩放的初始化方法,确保不同规模网络的激活值保持在合适的范围内。
-
学习率自适应: μP 优化器会根据网络规模自动调整每个参数的学习率。
-
注意力机制的修改: 在 Transformer 模型中,μP 将注意力计分的缩放因子从 1/sqrt(d) 改为 1/d。
-
输出层的特殊处理: μP 使用
MuReadout层替代标准的线性输出层,以确保输出稳定性。
如何使用 μP
使用 μP 主要涉及以下几个步骤:
- 安装 mup 包:
pip install -e .
- 在模型定义中使用 μP 组件:
from mup import MuReadout, set_base_shapes
class MyModel(nn.Module):
def __init__(self, width):
super().__init__()
...
self.readout = MuReadout(width, d_out)
def forward(self, x):
...
# 使用 8/d 而不是 1/sqrt(d) 作为注意力缩放因子
attention_scores = query @ key.T * 8 / d
...
# 设置基础形状
base_model = MyModel(width=1)
delta_model = MyModel(width=2)
model = MyModel(width=100)
set_base_shapes(model, base_model, delta=delta_model)
- 使用 μP 优化器:
from mup import MuSGD, MuAdam
optimizer = MuAdam(model.parameters(), lr=0.001)
μP 的实际效果
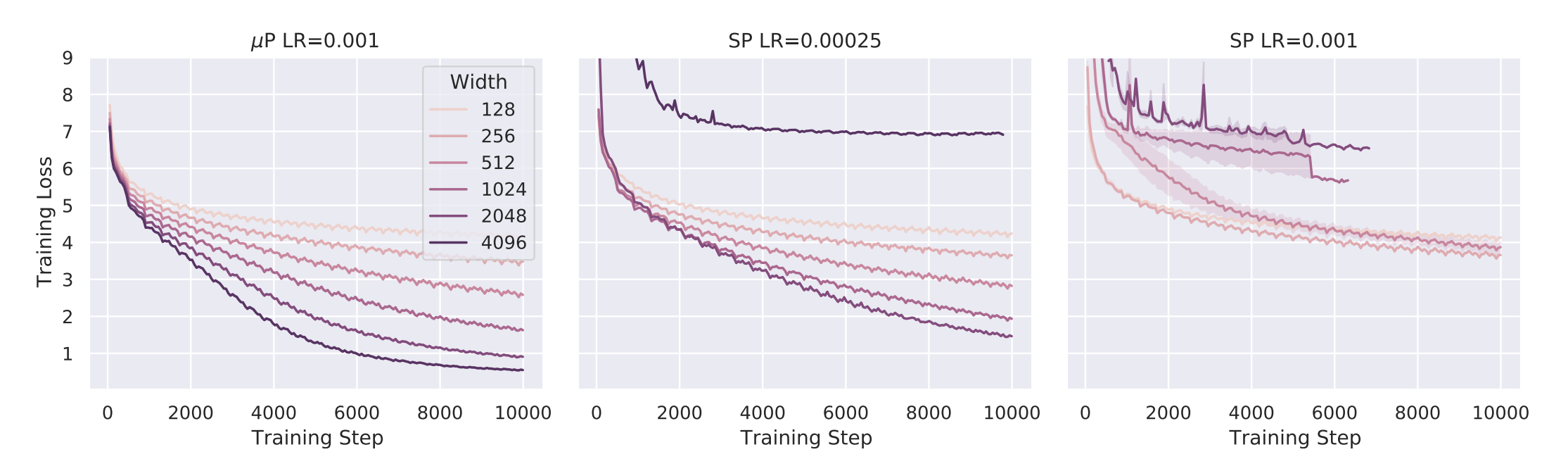
上图展示了 μP 在不同网络宽度下的训练曲线。可以看到,使用 μP 后,网络性能随宽度增加而稳定提升,而标准参数化 (SP) 则可能在某个宽度后性能反而下降。
验证 μP 实现的正确性
为了确保 μP 被正确实现,可以使用"坐标检查"(Coord Check)方法:
from mup.coord_check import get_coord_data, plot_coord_data
def lazy_model(width):
return lambda: set_base_shapes(MyMuModel(width), 'base_shape.bsh')
models = {64: lazy_model(64), 128: lazy_model(128), 256: lazy_model(256)}
dataloader = ... # 准备一个小批量数据加载器用于测试
df = get_coord_data(models, dataloader)
plot_coord_data(df, save_to='coord_check.png')
如果实现正确,坐标检查图中的曲线应该在不同宽度下保持水平。
μP 的未来发展
目前,μP 已经在多个领域展现出了巨大潜力,特别是在大规模预训练模型的调优中。未来,我们可能会看到:
- 与主流深度学习框架的更深入集成
- 在更多类型的神经网络架构中的应用
- 结合其他先进技术,进一步提升大模型训练效率
结语
μP 技术为深度学习中的超参数调优带来了革命性的突破。通过实现真正的"零样本超参数迁移",μP 大大降低了大型神经网络的开发和训练成本。随着这项技术的不断发展和应用,我们有理由期待它将在未来的AI研究和应用中发挥越来越重要的作用。
如果您对 μP 技术感兴趣,可以访问 GitHub 项目页面 了解更多详情,并尝试将其应用到您自己的深度学习项目中。让我们一起探索 μP 带来的无限可能!









