
引言
在人工智能领域,多媒体生成技术一直是研究的热点。近年来,文本到图像的模型取得了显著进展,但视频合成方法的发展则相对缓慢。本文将介绍一个突破性的文本到视频生成模型 - Kandinsky Video 1.1,它在视频质量、文本对齐度和动态效果等方面均达到了业界领先水平。
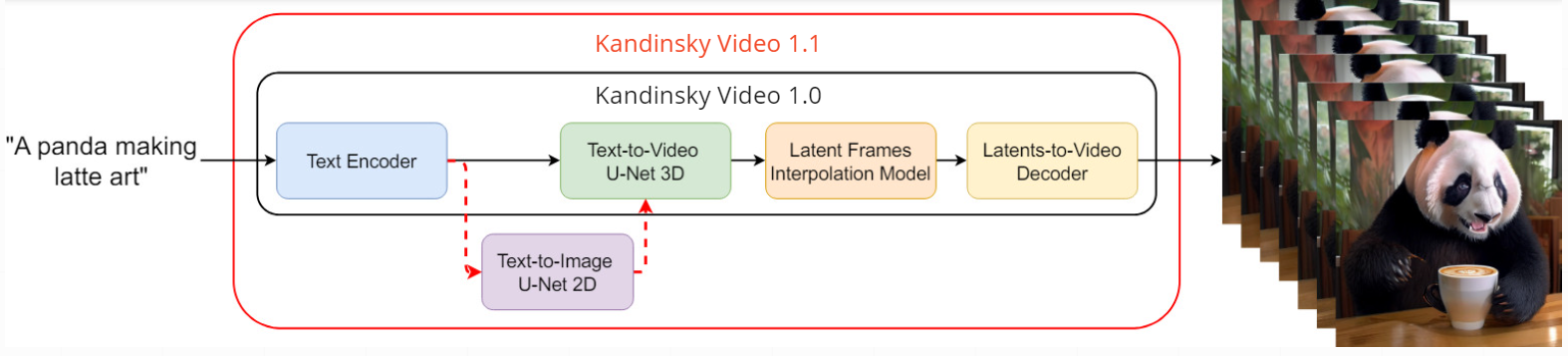
Kandinsky Video 1.1的核心架构
Kandinsky Video 1.1是基于FusionFrames架构和Kandinsky 3.0文本到图像模型开发的。它采用了一种创新的两阶段潜在扩散文本到视频生成架构,具体包括以下几个关键组件:
- 文本编码器(Flan-UL2): 8.6B参数
- 潜在扩散U-Net3D: 4.15B参数
- 插值模型(潜在扩散U-Net3D): 4.0B参数
- 图像MoVQ编码器/解码器: 256M参数
- 视频(时序)MoVQ解码器: 556M参数
与Kandinsky Video 1.0相比,1.1版本在关键帧生成阶段引入了重要创新。它首先使用Kandinsky 3.0文本到图像模型生成视频的初始帧,然后基于文本提示和先前生成的第一帧来生成后续关键帧。这种方法确保了帧间内容的一致性,显著提升了整体视频质量。
工作流程
Kandinsky Video 1.1的工作流程可以分为以下几个步骤:
-
文本编码: 使用Flan-UL2模型对输入的文本提示进行编码。
-
初始帧生成: 利用Kandinsky 3.0文本到图像模型,基于文本提示生成视频的第一帧。
-
关键帧生成: 使用潜在扩散U-Net3D模型,结合文本提示和初始帧,生成后续的关键帧。
-
帧插值: 采用插值模型(另一个潜在扩散U-Net3D)在关键帧之间生成过渡帧,以提高视频的帧率和流畅度。
-
视频解码: 最后,通过时序MoVQ-GAN解码器将生成的帧序列转换为最终的视频输出。
这种创新的pipeline不仅提高了视频内容的一致性,还显著增强了整体视频质量。此外,它还支持将任何输入图像制作成动画,为创作者提供了更多可能性。
运动分数和噪声增强调节
Kandinsky Video 1.1引入了两个重要的调节参数:运动分数(Motion Score)和噪声增强(Noise Augmentation)。这两个参数允许用户精细控制生成视频的动态效果和细节程度。

- 运动分数: 控制视频中的动态程度,从"低"到"高"可以生成不同程度的运动效果。
- 噪声增强: 影响视频的细节丰富度和纹理复杂性。
通过调整这两个参数,用户可以根据需求生成从静态场景到高度动态的视频内容,极大地提高了模型的灵活性和适用性。
性能评估
Kandinsky Video 1.1在EvalCrafter文本到视频基准测试中表现出色,总体排名第二,在开源模型中排名第一。评估指标包括:
- 视觉质量(VQ)
- 文本-视频对齐度(TVA)
- 动作质量(MQ)
- 时间一致性(TC)
- 最终平均分数(FAS)
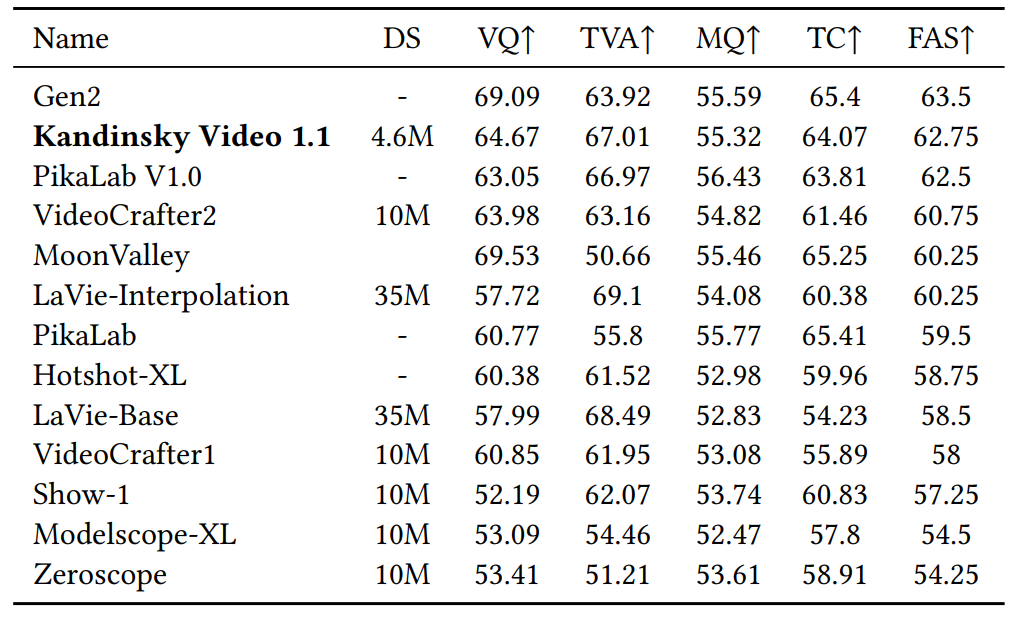
在人工评估中,Kandinsky Video 1.1也显示出优于Video LDM等竞争模型的性能。这些结果充分证明了该模型在视频生成质量和文本对齐方面的卓越表现。
实际应用
Kandinsky Video 1.1提供了两种主要的使用方式:
- 文本到视频生成: 用户可以输入文本描述,模型将生成相应的视频内容。
from kandinsky_video import get_T2V_pipeline
device_map = 'cuda:0'
t2v_pipe = get_T2V_pipeline(device_map)
prompt = "A cat wearing sunglasses and working as a lifeguard at a pool."
fps = 'medium' # ['low', 'medium', 'high']
motion = 'high' # ['low', 'medium', 'high']
video = t2v_pipe(
prompt,
width=512, height=512,
fps=fps,
motion=motion,
key_frame_guidance_scale=5.0,
guidance_weight_prompt=5.0,
guidance_weight_image=3.0,
)
- 图像到视频生成: 用户可以提供一张初始图像和文本描述,模型将基于此生成动画视频。
from PIL import Image
import requests
from io import BytesIO
url = 'https://media.cnn.com/api/v1/images/stellar/prod/gettyimages-1961294831.jpg'
response = requests.get(url)
img = Image.open(BytesIO(response.content))
prompt = "A panda climbs up a tree."
video = t2v_pipe(
prompt,
image=img,
width=640, height=384,
fps=fps,
motion=motion,
key_frame_guidance_scale=5.0,
guidance_weight_prompt=5.0,
guidance_weight_image=3.0,
)
这些功能为创意工作者、内容制作者和研究人员提供了强大的工具,可以快速生成高质量的视频内容或将静态图像转换为动画。
结论与展望
Kandinsky Video 1.1代表了文本到视频生成技术的重要进步。它不仅在视频质量和文本对齐方面取得了显著成果,还提供了灵活的参数调节,使用户能够精确控制生成内容的特性。这个模型为创意产业、教育、娱乐等多个领域带来了新的可能性。
随着技术的不断发展,我们可以期待看到更多在视频长度、分辨率和复杂场景处理方面的改进。未来,这类模型可能会进一步整合3D理解和物理模拟,以生成更加逼真和连贯的视频内容。
Kandinsky Video 1.1的开源性质也为研究社区提供了宝贵的资源,促进了该领域的进一步创新和发展。随着更多研究者和开发者的参与,我们有理由相信,人工智能驱动的视频生成技术将继续突破边界,为世界带来更多惊喜和价值。
参考资料
如果您在研究中使用了Kandinsky Video 1.1,请引用以下论文:
@article{arkhipkin2023fusionframes,
title = {FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline},
author = {Arkhipkin, Vladimir and Shaheen, Zein and Vasilev, Viacheslav and Dakhova, Elizaveta and Kuznetsov, Andrey and Dimitrov, Denis},
journal = {arXiv preprint arXiv:2311.13073},
year = {2023},
}
通过不断的创新和改进,Kandinsky Video 1.1为人工智能驱动的视频生成开辟了新的可能性。无论是在研究领域还是实际应用中,它都展现出了巨大的潜力,我们期待看到它在未来带来更多令人兴奋的发展。









