
 访问官网
访问官网 Github
Github Huggingface
HuggingfaceKandinsky视频1.1 — 一种新的文本到视频生成模型
在EvalCrafter基准测试中,开源解决方案中的最佳质量
本仓库是Kandinsky视频1.1模型的官方实现。
 | Telegram机器人 | Habr文章 | 我们的文本到图像模型 | 项目页面
| Telegram机器人 | Habr文章 | 我们的文本到图像模型 | 项目页面
我们之前的模型Kandinsky视频1.0将视频生成过程分为两个阶段:首先以低帧率生成关键帧,然后在这些关键帧之间创建插值帧以提高帧率。在Kandinsky视频1.1中,我们进一步将关键帧生成分为两个额外步骤:首先使用文本到图像Kandinsky 3.0从文本提示生成视频的初始帧,然后基于文本提示和先前生成的第一帧生成后续关键帧。这种方法确保了帧之间内容的一致性,并显著提高了整体视频质量。此外,该方法还允许作为附加功能对任何输入图像进行动画处理。
流程
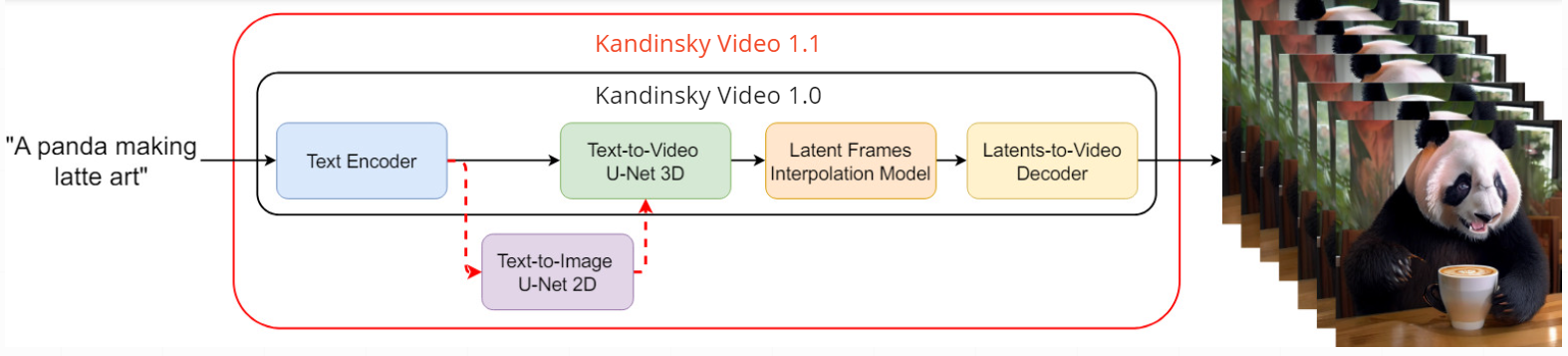
在Kandinsky视频1.0中,编码的文本提示进入带有时间层或块的文本到视频U-Net3D关键帧生成模型,然后采样的潜在关键帧被发送到潜在插值模型以预测两个关键帧之间的三个插值帧。使用图像MoVQ-GAN解码器获得最终视频结果。在Kandinsky视频1.1中,文本到视频U-Net3D还受文本到图像U-Net2D的条件约束,这有助于提高内容质量。使用时间MoVQ-GAN解码器解码最终视频。
架构细节
- 文本编码器(Flan-UL2) - 8.6B
- 潜在扩散U-Net3D - 4.15B
- 插值模型(潜在扩散U-Net3D) - 4.0B
- 图像MoVQ编码器/解码器 - 256M
- 视频(时间)MoVQ解码器 - 556M
使用方法
1. 文本到视频
from kandinsky_video import get_T2V_pipeline
device_map = 'cuda:0'
t2v_pipe = get_T2V_pipeline(device_map)
prompt = "一只戴着太阳镜在泳池当救生员的猫。"
fps = 'medium' # ['low', 'medium', 'high']
motion = 'high' # ['low', 'medium', 'high']
video = t2v_pipe(
prompt,
width=512, height=512,
fps=fps,
motion=motion,
key_frame_guidance_scale=5.0,
guidance_weight_prompt=5.0,
guidance_weight_image=3.0,
)
path_to_save = f'./__assets__/video.gif'
video[0].save(
path_to_save,
save_all=True, append_images=video[1:], duration=int(5500/len(video)), loop=0
)

生成的视频
2. 图像到视频
from kandinsky_video import get_T2V_pipeline
device_map = 'cuda:0'
t2v_pipe = get_T2V_pipeline(device_map)
from PIL import Image
import requests
from io import BytesIO
url = 'https://yellow-cdn.veclightyear.com/0a4dffa0/9d9d2083-7713-4e99-beff-f03f4af82915.jpg'
response = requests.get(url)
img = Image.open(BytesIO(response.content))
img.show()
prompt = "一只熊猫爬上树。"
fps = 'medium' # ['low', 'medium', 'high']
motion = 'medium' # ['low', 'medium', 'high']
video = t2v_pipe(
prompt,
image=img,
width=640, height=384,
fps=fps,
motion=motion,
key_frame_guidance_scale=5.0,
guidance_weight_prompt=5.0,
guidance_weight_image=3.0,
)
path_to_save = f'./__assets__/video2.gif'
video[0].save(
path_to_save,
save_all=True, append_images=video[1:], duration=int(5500/len(video)), loop=0
)

输入图像。

生成的视频。
运动分数和噪声增强条件

基于不同运动分数和噪声增强水平的生成变化。横轴显示噪声增强水平(NA),纵轴显示运动分数(MS)。
结果
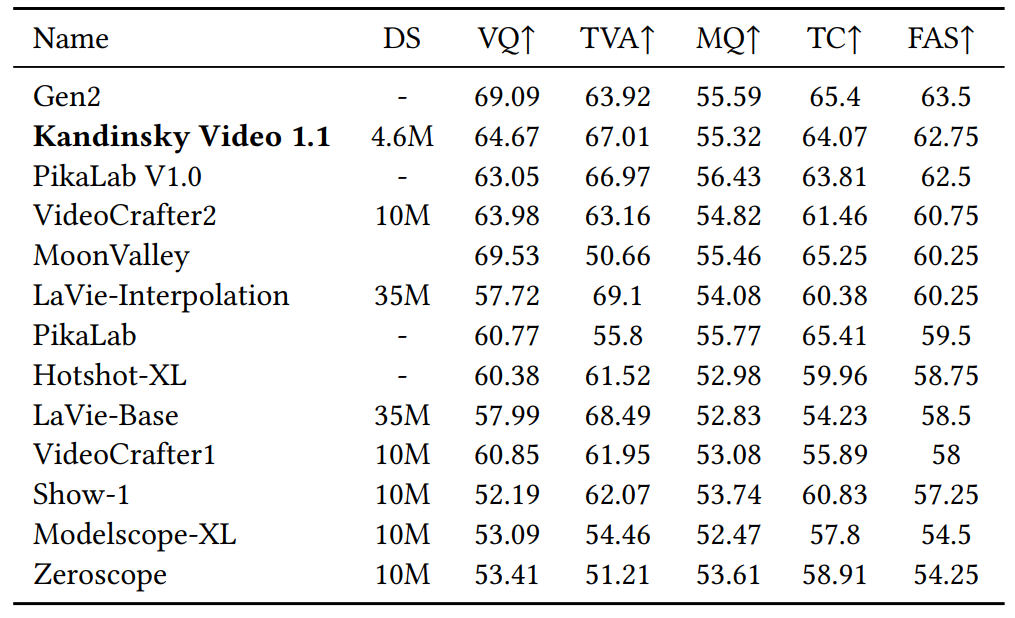
Kandinsky Video 1.1在EvalCrafter文本到视频基准测试中总体排名第二,是最佳开源模型。VQ:视觉质量,TVA:文本-视频对齐度,MQ:运动质量,TC:时间一致性,FAS:最终平均分。
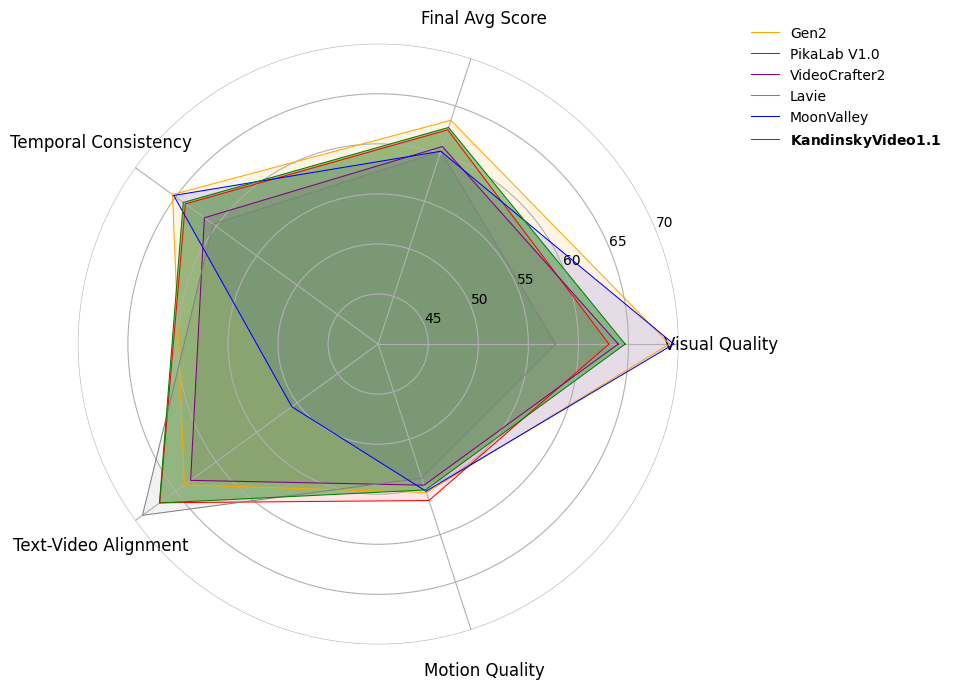
多边形雷达图展示Kandinsky Video 1.1在EvalCrafter基准测试中的表现。
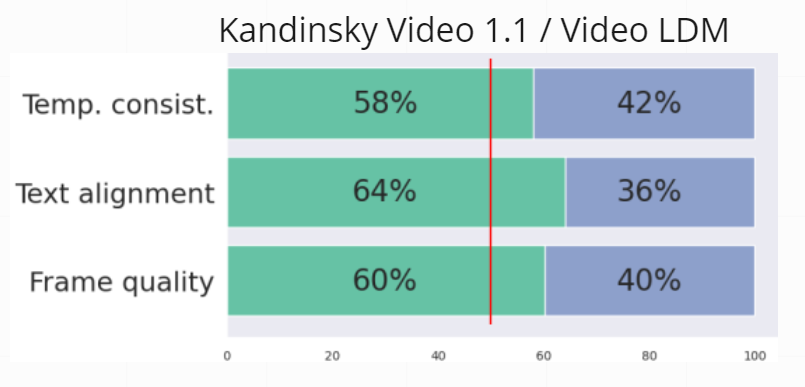
人工评估研究结果。图中的条形对应于模型生成的并排比较中"获胜"的百分比。我们将我们的模型与Video LDM进行了比较。
作者
- Zein Shaheen:Github,Google Scholar
- Vladimir Arkhipkin:Github,Google Scholar
- Viacheslav Vasilev:Github,Google Scholar
- Igor Pavlov:Github
- Elizaveta Dakhova:Github
- Anastasia Lysenko:Github
- Sergey Markov
- Denis Dimitrov:Github,Google Scholar
- Andrey Kuznetsov:Github,Google Scholar
BibTeX
如果您在研究中使用我们的工作,请引用我们的出版物:
@article{arkhipkin2023fusionframes,
title = {FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline},
author = {Arkhipkin, Vladimir and Shaheen, Zein and Vasilev, Viacheslav and Dakhova, Elizaveta and Kuznetsov, Andrey and Dimitrov, Denis},
journal = {arXiv preprint arXiv:2311.13073},
year = {2023},
}











