
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文Tune-A-Video
这个仓库是 Tune-A-Video 的官方实现。
Tune-A-Video:图像扩散模型的一次性微调用于文本到视频生成
Jay Zhangjie Wu,
Yixiao Ge,
Xintao Wang,
Stan Weixian Lei,
Yuchao Gu,
Yufei Shi,
Wynne Hsu,
Ying Shan,
Xiaohu Qie,
Mike Zheng Shou



给定一个视频-文本对作为输入,我们的方法 Tune-A-Video 微调预训练的文本到图像扩散模型用于文本到视频生成。
新闻
🚨 宣布 LOVEU-TGVE:一个基于 AI 的视频编辑 CVPR 比赛!提交截止日期为 6 月 5 日。不要错过!🤩
- [2023/02/22] 使用 DDIM 反演改进一致性。
- [2023/02/08] Colab 演示 发布!
- [2023/02/03] 预训练的 Tune-A-Video 模型可在 Hugging Face 库 上获取!
- [2023/01/28] 新功能:在个性化 DreamBooth 模型上微调视频。
- [2023/01/28] 代码发布!
设置
要求
pip install -r requirements.txt
强烈建议安装 xformers 以提高 GPU 上的效率和速度。
要启用 xformers,请设置 enable_xformers_memory_efficient_attention=True(默认)。
权重
[Stable Diffusion] Stable Diffusion 是一个潜在的文本到图像扩散模型,能够根据任何文本输入生成逼真的图像。预训练的 Stable Diffusion 模型可以从 Hugging Face 下载(例如,Stable Diffusion v1-4,v2-1)。您还可以使用在不同风格上训练的微调 Stable Diffusion 模型(例如,Modern Disney,Anything V4.0,Redshift 等)。
[DreamBooth] DreamBooth 是一种方法,可以通过仅几张图像(3~5 张)个性化 Stable Diffusion 等文本到图像模型。在 DreamBooth 模型上微调视频允许对特定主题进行个性化的文本到视频生成。Hugging Face 上有一些公开的 DreamBooth 模型(例如,mr-potato-head)。您也可以按照这个训练示例训练自己的 DreamBooth 模型。
使用方法
训练
要微调文本到图像扩散模型用于文本到视频生成,请运行此命令:
accelerate launch train_tuneavideo.py --config="configs/man-skiing.yaml"
注意:微调一个 24 帧的视频通常需要 300~500 步,使用一个 A100 GPU 大约需要 10~15 分钟。
如果您的 GPU 内存有限,请减少 n_sample_frames。
推理
训练完成后,运行推理:
from tuneavideo.pipelines.pipeline_tuneavideo import TuneAVideoPipeline
from tuneavideo.models.unet import UNet3DConditionModel
from tuneavideo.util import save_videos_grid
import torch
pretrained_model_path = "./checkpoints/stable-diffusion-v1-4"
my_model_path = "./outputs/man-skiing"
unet = UNet3DConditionModel.from_pretrained(my_model_path, subfolder='unet', torch_dtype=torch.float16).to('cuda')
pipe = TuneAVideoPipeline.from_pretrained(pretrained_model_path, unet=unet, torch_dtype=torch.float16).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_vae_slicing()
prompt = "spider man is skiing"
ddim_inv_latent = torch.load(f"{my_model_path}/inv_latents/ddim_latent-500.pt").to(torch.float16)
video = pipe(prompt, latents=ddim_inv_latent, video_length=24, height=512, width=512, num_inference_steps=50, guidance_scale=12.5).videos
save_videos_grid(video, f"./{prompt}.gif")
结果
预训练 T2I(Stable Diffusion)
| 输入视频 | 输出视频 | ||
 |  |  |  |
| "一个男人在滑雪" | "蜘蛛侠在海滩上滑雪,卡通风格" | "神奇女侠戴着牛仔帽在滑雪" | "一个男人穿着粉色衣服在日落时分滑雪" |
 |  |  |  |
| "一只兔子在桌子上吃西瓜" | "一只兔子 | "一只戴着太阳镜的猫在海滩上吃西瓜" | "一只小狗在桌子上吃芝士汉堡,漫画风格" |
 |  |  |  |
| "一辆吉普车在路上行驶" | "一辆保时捷在海滩上行驶" | "一辆汽车在路上行驶,卡通风格" | "一辆汽车在雪地上行驶" |
 |  | 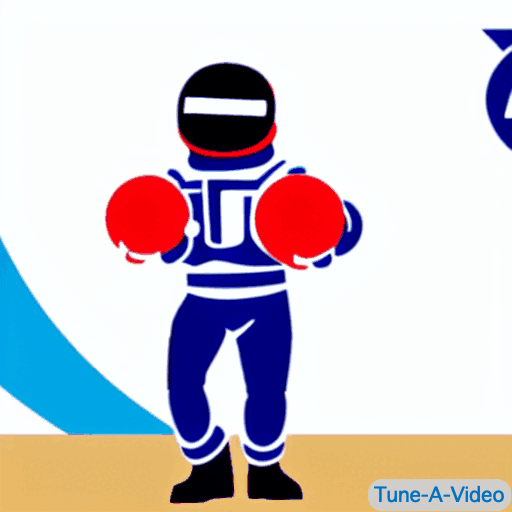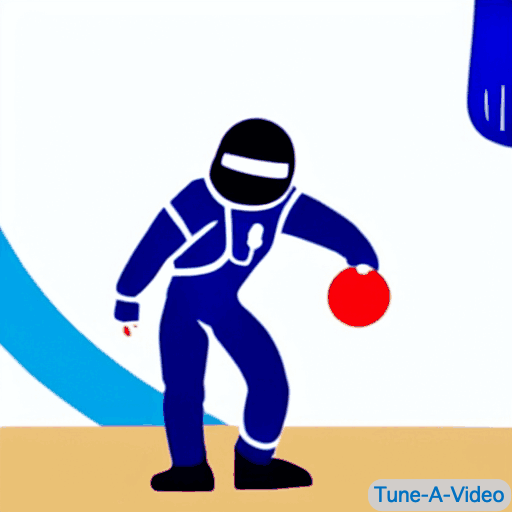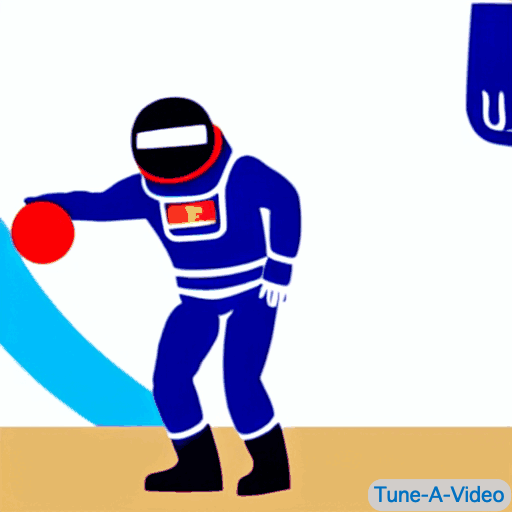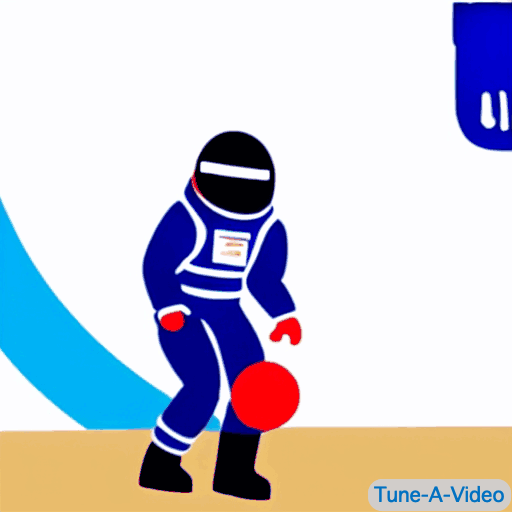 |  |
| "一个男人在运球" | "詹姆斯·邦德在海滩上运球" | "一位宇航员以卡通风格运球" | "一个穿黑西装的乐高人在运球" |
预训练的文本到图像模型(个性化DreamBooth)

| 输入视频 | 输出视频 | ||
 |  |  |  |
| "一只熊在弹吉他" | "一个女孩在弹吉他,白发,中等长度的头发,猫耳朵,闭着眼睛,可爱,围巾,夹克,户外,街道" | "一个男孩在弹吉他,美少年,休闲装,室内,坐着,咖啡店,背景虚化" | "一个女孩在弹吉他,红发,长发,美丽的眼睛,看着观众,可爱,连衣裙,海滩,大海" |

| 输入视频 | 输出视频 | ||
|  |  |  |
| "一只熊在弹吉他" | "一只兔子在弹吉他,现代迪士尼风格" | "一位英俊的王子在弹吉他,现代迪士尼风格" | "一位戴着墨镜的魔法公主在舞台上弹吉他,现代迪士尼风格" |

| 输入视频 | 输出视频 | ||
|  |  |  |
| "一只熊在弹吉他" | "乐高制作的薯头先生在雪地上弹吉他" | "戴着墨镜的薯头先生在海滩上弹吉他" | "薯头先生在梵高风格的星空下弹吉他" |
引用
如果您使用了我们的工作,请引用我们的论文。
@inproceedings{wu2023tune,
title={Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation},
author={Wu, Jay Zhangjie and Ge, Yixiao and Wang, Xintao and Lei, Stan Weixian and Gu, Yuchao and Shi, Yufei and Hsu, Wynne and Shan, Ying and Qie, Xiaohu and Shou, Mike Zheng},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={7623--7633},
year={2023}
}











