
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文WizardLM:赋能大型预训练语言模型以执行复杂指令
🏠 主页
🤗 HF 仓库 • 🐦 Twitter • 📃 [WizardLM] @ICLR2024 • 📃 [WizardCoder] @ICLR2024 • 📃 [WizardMath]
👋 加入我们的 Discord




非官方视频介绍
感谢热心朋友们,他们的视频介绍更加生动有趣。
- 全新 WizardLM 70b 🔥 巨型模型...惊人表现
- 立即获取 WizardLM!7B LLM 之王可击败 ChatGPT!我印象深刻!
- WizardLM:增强大型语言模型以执行复杂指令
- WizardCoder AI 是 ChatGPT 编程的新孪生兄弟!
新闻
-
🔥🔥🔥[2024/01/04] 我们发布了基于 deepseek-coder-33b-base 训练的 WizardCoder-33B-V1.1,这是 EvalPlus 排行榜 上的最先进的开源代码 LLM,在 HumanEval 上达到 79.9 pass@1,在 HumanEval-Plus 上达到 73.2 pass@1,在 MBPP 上达到 78.9 pass@1,在 MBPP-Plus 上达到 66.9 pass@1。WizardCoder-33B-V1.1 在 HumanEval 和 HumanEval-Plus pass@1 上优于 ChatGPT 3.5、Gemini Pro 和 DeepSeek-Coder-33B-instruct。WizardCoder-33B-V1.1 在 MBPP 和 MBPP-Plus pass@1 上与 ChatGPT 3.5 相当,并超越了 Gemini Pro。
-
[2023/08/26] 我们发布了 WizardCoder-Python-34B-V1.0,它在 HumanEval 基准测试 上达到了 73.2 pass@1,超越了 GPT4 (2023/03/15)、ChatGPT-3.5 和 Claude2。更多详情请参考 WizardCoder。
-
[2023/06/16] 我们发布了 WizardCoder-15B-V1.0,它在 HumanEval 基准测试 上超越了 Claude-Plus (+6.8)、Bard (+15.3) 和 InstructCodeT5+ (+22.3)。更多详情请参考 WizardCoder。 | 模型 | 检查点 | 论文 | HumanEval | HumanEval+ | MBPP | MBPP+ | | ----- |------| ---- |------|-------| ----- | ----- | | GPT-4-Turbo (2023年11月) | - | - | 85.4 | 81.7 | 83.0 | 70.7 | | GPT-4 (2023年5月) | - | - | 88.4 | 76.8 | - | - | | GPT-3.5-Turbo (2023年11月) | - | - | 72.6 | 65.9 | 81.7 | 69.4 | | Gemini Pro | - | - | 63.4 | 55.5 | 72.9 | 57.9 | | DeepSeek-Coder-33B-instruct | - | - | 78.7 | 72.6 | 78.7 | 66.7 | | WizardCoder-33B-V1.1 | 🤗 HF链接 | 📃 [WizardCoder] | 79.9 | 73.2 | 78.9 | 66.9 | | WizardCoder-Python-34B-V1.0 | 🤗 HF链接 | 📃 [WizardCoder] | 73.2 | 64.6 | 73.2 | 59.9 | | WizardCoder-15B-V1.0 | 🤗 HF链接 | 📃 [WizardCoder] | 59.8 | 52.4 | -- | -- | | WizardCoder-Python-13B-V1.0 | 🤗 HF链接 | 📃 [WizardCoder] | 64.0 | -- | -- | -- | | WizardCoder-Python-7B-V1.0 | 🤗 HF链接 | 📃 [WizardCoder] | 55.5 | -- | -- | -- | | WizardCoder-3B-V1.0 | 🤗 HF链接 | 📃 [WizardCoder] | 34.8 | -- | -- | -- | | WizardCoder-1B-V1.0 | 🤗 HF链接 | 📃 [WizardCoder] | 23.8 | -- | -- | -- |
-
[2023年12月19日] 🔥 我们发布了基于Mistral-7B训练的WizardMath-7B-V1.1,这是最先进的7B数学大语言模型,在GSM8k上达到83.2 pass@1,在MATH上达到33.0 pass@1。
-
[2023年12月19日] 🔥 WizardMath-7B-V1.1在GSM8K pass@1上的表现超过了ChatGPT 3.5、Gemini Pro、Mixtral MOE和Claude Instant。
-
[2023年12月19日] 🔥 WizardMath-7B-V1.1在MATH pass@1上的表现与ChatGPT 3.5、Gemini Pro相当,并超过了Mixtral MOE。
-
🔥 我们的WizardMath-70B-V1.0模型在GSM8K上的表现略微超过了一些闭源大语言模型,包括ChatGPT 3.5、Claude Instant 1和PaLM 2 540B。
-
🔥 我们的WizardMath-70B-V1.0模型在GSM8k基准测试上达到了81.6 pass@1,比最先进的开源大语言模型高出24.8个百分点。
-
🔥 我们的WizardMath-70B-V1.0模型在MATH基准测试上达到了22.7 pass@1,比最先进的开源大语言模型高出9.2个百分点。 | 模型 | 检查点 | 论文 | GSM8k | MATH | | ----- |------| ---- |------|-------| | WizardMath-7B-V1.1 | 🤗 HF链接 | 📃 [WizardMath] | 83.2 | 33.0 | | WizardMath-70B-V1.0 | 🤗 HF链接 | 📃 [WizardMath] | 81.6 | 22.7 | | WizardMath-13B-V1.0 | 🤗 HF链接 | 📃 [WizardMath] | 63.9 | 14.0 | | WizardMath-7B-V1.0 | 🤗 HF链接 | 📃 [WizardMath] | 54.9 | 10.7 |
-
[2023年8月9日] 我们发布了 WizardLM-70B-V1.0 模型。这里是完整模型权重。
| 模型 | 检查点 | 论文 | MT-Bench | AlpacaEval | GSM8k | HumanEval | 演示 | 许可证 |
|---|---|---|---|---|---|---|---|---|
| WizardLM-70B-V1.0 | 🤗 HF链接 | 📃即将推出 | 7.78 | 92.91% | 77.6% | 50.6 | Llama 2 许可证 | |
| WizardLM-13B-V1.2 | 🤗 HF链接 | 7.06 | 89.17% | 55.3% | 36.6 | 演示 | Llama 2 许可证 | |
| WizardLM-13B-V1.1 | 🤗 HF链接 | 6.76 | 86.32% | 25.0 | 非商业用途 | |||
| WizardLM-30B-V1.0 | 🤗 HF链接 | 7.01 | 37.8 | 非商业用途 | ||||
| WizardLM-13B-V1.0 | 🤗 HF链接 | 6.35 | 75.31% | 24.0 | 非商业用途 | |||
| WizardLM-7B-V1.0 | 🤗 HF链接 | 📃 [WizardLM] | 19.1 | 非商业用途 |
引用
如果您使用了WizardLM的数据或代码,请引用以下论文。
@inproceedings{
xu2024wizardlm,
title={WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions},
author={Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Qingwei Lin and Daxin Jiang},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=CfXh93NDgH}
}
如果您使用了WizardCoder的数据或代码,请引用以下论文。
@inproceedings{
luo2024wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Ziyang Luo and Can Xu and Pu Zhao and Qingfeng Sun and Xiubo Geng and Wenxiang Hu and Chongyang Tao and Jing Ma and Qingwei Lin and Daxin Jiang},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=UnUwSIgK5W}
}
如果您参考了WizardMath的模型、代码、数据或论文,请引用该论文。
@article{luo2023wizardmath,
title={WizardMath: 通过强化进化指令增强大型语言模型的数学推理能力},
author={Luo, Haipeng and Sun, Qingfeng and Xu, Can and Zhao, Pu and Lou, Jianguang and Tao, Chongyang and Geng, Xiubo and Lin, Qingwei and Chen, Shifeng and Zhang, Dongmei},
journal={arXiv预印本 arXiv:2308.09583},
year={2023}
}
❗关于数据集的常见关注点:
最近,我们整个组织在代码、数据和模型的开源政策和规定方面发生了明显变化。 尽管如此,我们仍然努力争取首先开放模型权重,但数据涉及更严格的审核,目前正由我们的法律团队审核中。 我们的研究人员无权未经授权公开发布这些数据。 感谢您的理解。
招聘
- 📣 我们正在寻找高度积极的学生加入我们,成为实习生,一起创造更智能的人工智能。请联系caxu@microsoft.com
模型系统提示使用说明:
为获得与我们演示完全相同的结果,请严格按照"src/infer_wizardlm13b.py"中提供的提示和调用方法使用我们的模型进行推理。我们的模型采用Vicuna的提示格式,支持多轮对话。
对于WizardLM,提示应如下所示:
一个好奇的用户和一个人工智能助手之间的对话。助手对用户的问题给出有帮助、详细和礼貌的回答。用户:你好 助手:你好。</s>用户:你是谁? 助手:我是WizardLM。</s>......
对于WizardCoder,提示应如下所示:
"以下是描述一个任务的指令。写一个恰当完成该请求的回应。\n\n### 指令:\n{instruction}\n\n### 回应:"
对于WizardMath,提示应如下所示:
默认版本:
"以下是描述一个任务的指令。写一个恰当完成该请求的回应。\n\n### 指令:\n{instruction}\n\n### 回应:"
CoT版本:(❗对于简单的数学问题,我们不建议使用CoT提示。)
"以下是描述一个任务的指令。写一个恰当完成该请求的回应。\n\n### 指令:\n{instruction}\n\n### 回应:让我们一步步思考。"
GPT-4自动评估
我们采用FastChat提出的基于GPT-4的自动评估框架来评估聊天机器人模型的性能。如下图所示,WizardLM-30B取得了比Guanaco-65B更好的结果。
WizardLM-30B在不同技能上的表现
下图比较了WizardLM-30B和ChatGPT在Evol-Instruct测试集上的技能。结果表明,WizardLM-30B平均达到了ChatGPT性能的97.8%,在18项技能上几乎达到(或超过)100%的能力,在24项技能上超过90%的能力。
WizardLM在NLP基础任务上的表现
下表提供了WizardLM与其他LLM在NLP基础任务上的比较。结果表明,WizardLM在相同规模上持续展现出优于LLaMa模型的性能。此外,我们的WizardLM-30B模型在MMLU和HellaSwag基准测试上表现出与OpenAI的Text-davinci-003相当的性能。
WizardLM在代码生成上的表现
下表提供了WizardLM与其他几个LLM在代码生成任务(即HumanEval)上的全面比较。评估指标是pass@1。结果表明,WizardLM在相同规模上持续展现出优于LLaMa模型的性能。此外,我们的WizardLM-30B模型超越了StarCoder和OpenAI的code-cushman-001。而且,我们的代码LLM——WizardCoder表现卓越,达到了57.3的pass@1分数,超过开源SOTA约20分。
| 模型 | HumanEval Pass@1 |
|---|---|
| LLaMA-7B | 10.5 |
| LLaMA-13B | 15.8 |
| CodeGen-16B-Multi | 18.3 |
| CodeGeeX | 22.9 |
| LLaMA-33B | 21.7 |
| LLaMA-65B | 23.7 |
| PaLM-540B | 26.2 |
| CodeGen-16B-Mono | 29.3 |
| code-cushman-001 | 33.5 |
| StarCoder | 33.6 |
| WizardLM-7B 1.0 | 19.1 |
| WizardLM-13B 1.0 | 24.0 |
| WizardLM-30B 1.0 | 37.8 |
| WizardCoder-15B 1.0 | 57.3 |
征集反馈意见
我们欢迎大家使用专业和困难的指令来评估WizardLM,并在问题讨论区域向我们展示表现不佳的例子以及您的建议。我们目前正专注于改进Evol-Instruct,希望在下一版本的WizardLM中缓解现有的弱点和问题。之后,我们将开放最新Evol-Instruct算法的代码和流程,与您一起努力改进它。
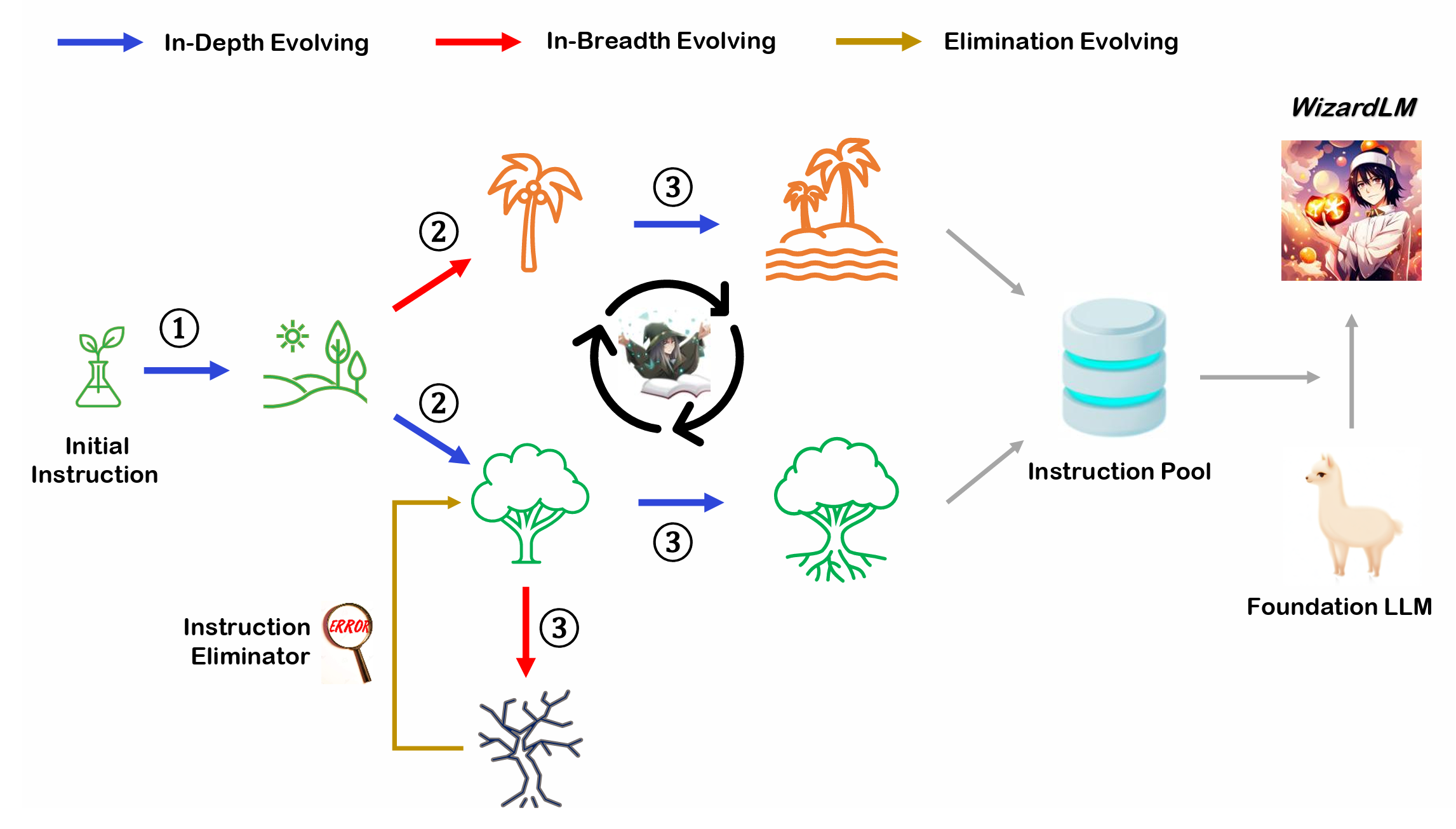
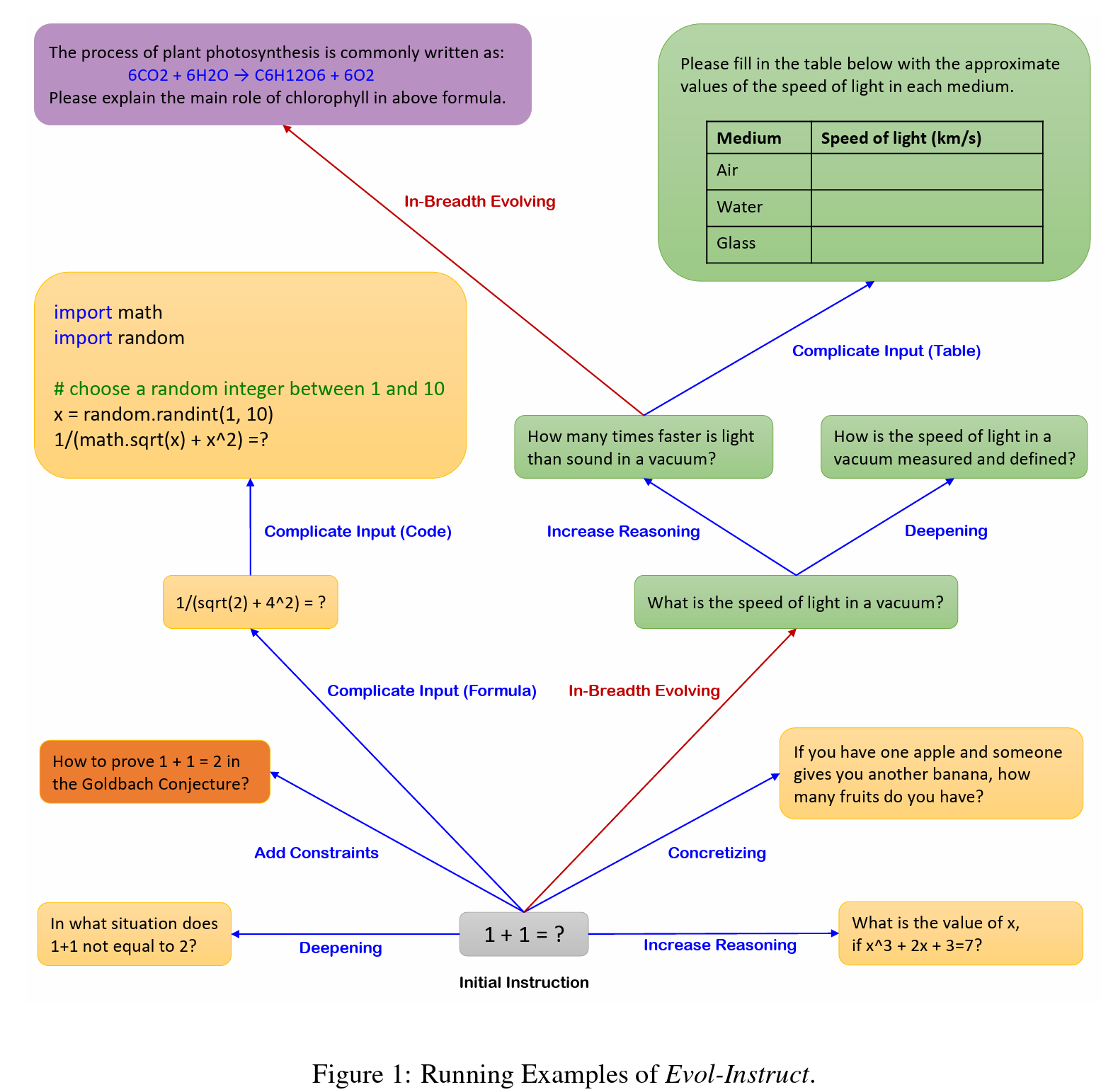
Evol-Instruct概述
Evol-Instruct是一种新颖的方法,使用大型语言模型(LLMs)而不是人类来自动大规模生产各种难度级别和技能范围的开放域指令,以提高LLMs的性能。您可以使用我们提供的Evol Script轻松开始您自己的进化之旅。
免责声明
与本项目相关的资源,包括代码、数据和模型权重,仅限于学术研究目的,不得用于商业用途。WizardLM的任何版本产生的内容受不可控变量(如随机性)的影响,因此本项目不能保证输出的准确性。本项目不承担模型输出内容的任何法律责任,也不对使用相关资源和输出结果造成的任何损失承担责任。











