KoBigBird:开启韩语长文本处理新纪元
在自然语言处理(NLP)领域,处理长文本一直是一个具有挑战性的任务。传统的Transformer模型如BERT虽然在许多NLP任务上表现出色,但其512个token的长度限制严重制约了其在长文本处理中的应用。为了突破这一瓶颈,研究人员开发了BigBird模型,通过稀疏注意力机制实现了对长序列的高效处理。而今,一个专门为韩语设计的BigBird预训练模型——KoBigBird应运而生,为韩语NLP带来了新的可能。
KoBigBird:长文本处理的新选择
KoBigBird是由Jangwon Park和Donggyu Kim开发的预训练BigBird模型,专门针对韩语进行了优化。它继承了BigBird模型的核心优势,能够处理长达4096个token的序列,是传统BERT模型处理能力的8倍。这一突破性进展使得KoBigBird在处理长文档、长对话等场景时具有明显优势。

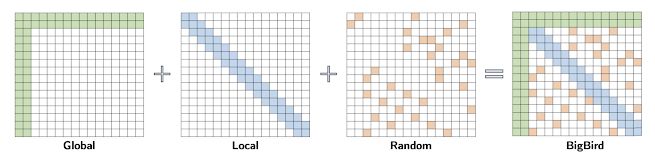
KoBigBird的核心优势在于其采用的稀疏注意力机制。与传统Transformer模型的全注意力机制不同,KoBigBird使用块稀疏注意力(block sparse attention),将原本O(n^2)的计算复杂度降低到了O(n),大大提高了计算效率。这意味着,在处理相同长度的文本时,KoBigBird能够以更低的计算成本实现更高的性能。
KoBigBird的技术细节
KoBigBird采用了内部Transformer结构(ITC, Internal Transformer Construction)进行训练。相比于外部Transformer结构(ETC),ITC在保持模型性能的同时,进一步优化了计算效率。在预训练阶段,研究团队使用了多样化的韩语语料,包括:
- 모두의 말뭉치(Everyone's Corpus)
- 韩语维基百科
- Common Crawl
- 新闻数据
这些多元化的语料确保了KoBigBird能够学习到丰富的语言知识和文本表示。
预训练的具体参数如下:
| 参数 | 值 |
|---|---|
| 硬件 | TPU v3-8 |
| 最大序列长度 | 4096 |
| 学习率 | 1e-4 |
| 批次大小 | 32 |
| 训练步数 | 2M |
| 预热步数 | 20k |
这些精心调优的参数为KoBigBird的出色性能奠定了基础。
KoBigBird的使用方法
得益于Hugging Face团队的支持,KoBigBird可以通过Transformers库轻松使用。以下是一个简单的示例代码:
from transformers import AutoModel, AutoTokenizer
# 加载模型
model = AutoModel.from_pretrained("monologg/kobigbird-bert-base")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("monologg/kobigbird-bert-base")
# 准备输入文本
text = "한국어 BigBird 모델을 공개합니다!"
# 编码输入
encoded_input = tokenizer(text, return_tensors='pt')
# 获取输出
output = model(**encoded_input)
需要注意的是,虽然模型名为BigBird,但在使用时应该使用BertTokenizer而非BigBirdTokenizer。这是因为KoBigBird在tokenizer层面与BERT保持了兼容性,以便更好地利用现有的韩语NLP生态系统。
KoBigBird的性能评估
为了全面评估KoBigBird的性能,研究团队在多个韩语NLP任务上进行了测试,包括短序列任务和长序列任务。
短序列任务(<=512 tokens)
在短序列任务中,KoBigBird与其他主流韩语预训练模型进行了对比:
| 模型 | NSMC (acc) | KLUE-NLI (acc) | KLUE-STS (pearsonr) | Korquad 1.0 (em/f1) | KLUE MRC (em/rouge-w) |
|---|---|---|---|---|---|
| KoELECTRA-Base-v3 | 91.13 | 86.87 | 93.14 | 85.66 / 93.94 | 59.54 / 65.64 |
| KLUE-RoBERTa-Base | 91.16 | 86.30 | 92.91 | 85.35 / 94.53 | 69.56 / 74.64 |
| KoBigBird-BERT-Base | 91.18 | 87.17 | 92.61 | 87.08 / 94.71 | 70.33 / 75.34 |
从结果可以看出,即使在短序列任务中,KoBigBird也能够与专门针对短文本优化的模型相媲美,甚至在某些任务上表现更优。
长序列任务(>=1024 tokens)
在长序列任务中,KoBigBird的优势更加明显:
| 模型 | TyDi QA (em/f1) | Korquad 2.1 (em/f1) | Fake News (f1) | Modu Sentiment (f1-macro) |
|---|---|---|---|---|
| KLUE-RoBERTa-Base | 76.80 / 78.58 | 55.44 / 73.02 | 95.20 | 42.61 |
| KoBigBird-BERT-Base | 79.13 / 81.30 | 67.77 / 82.03 | 98.85 | 45.42 |
在所有长序列任务中,KoBigBird都显著优于KLUE-RoBERTa-Base模型。特别是在Korquad 2.1任务中,KoBigBird的性能提升尤为显著,这充分证明了其在处理长文本时的独特优势。
KoBigBird的应用前景
KoBigBird的出现为韩语NLP领域带来了新的可能性。以下是几个潜在的应用场景:
-
长文档摘要: 利用KoBigBird处理长文本的能力,可以开发更精准的自动摘要系统,为新闻、学术论文等长文本生成高质量摘要。
-
长对话理解: 在客户服务、医疗咨询等需要理解长对话上下文的场景中,KoBigBird可以提供更准确的语义理解和意图识别。
-
长文本分类: 对于法律文书、医疗记录等长文本的分类任务,KoBigBird可以捕捉到更多的上下文信息,提高分类准确率。
-
问答系统优化: KoBigBird在问答任务上的出色表现,为构建能够理解和回答复杂长问题的系统提供了可能。
-
情感分析升级: 对于长评论、长篇文章的情感分析,KoBigBird能够更全面地理解文本情感,提供更准确的情感判断。
结语
KoBigBird的出现无疑是韩语NLP领域的一个重要里程碑。它不仅在技术上实现了突破,还为解决实际应用中的长文本处理问题提供了有力工具。随着KoBigBird的进一步发展和应用,我们有理由期待韩语NLP技术将迎来新的飞跃,为更多创新应用铺平道路。
作为开源项目,KoBigBird的发展离不开社区的支持。研究者们欢迎更多的开发者和研究人员参与到KoBigBird的优化和应用中来,共同推动韩语NLP技术的进步。让我们一起期待KoBigBird在未来带来更多惊喜!