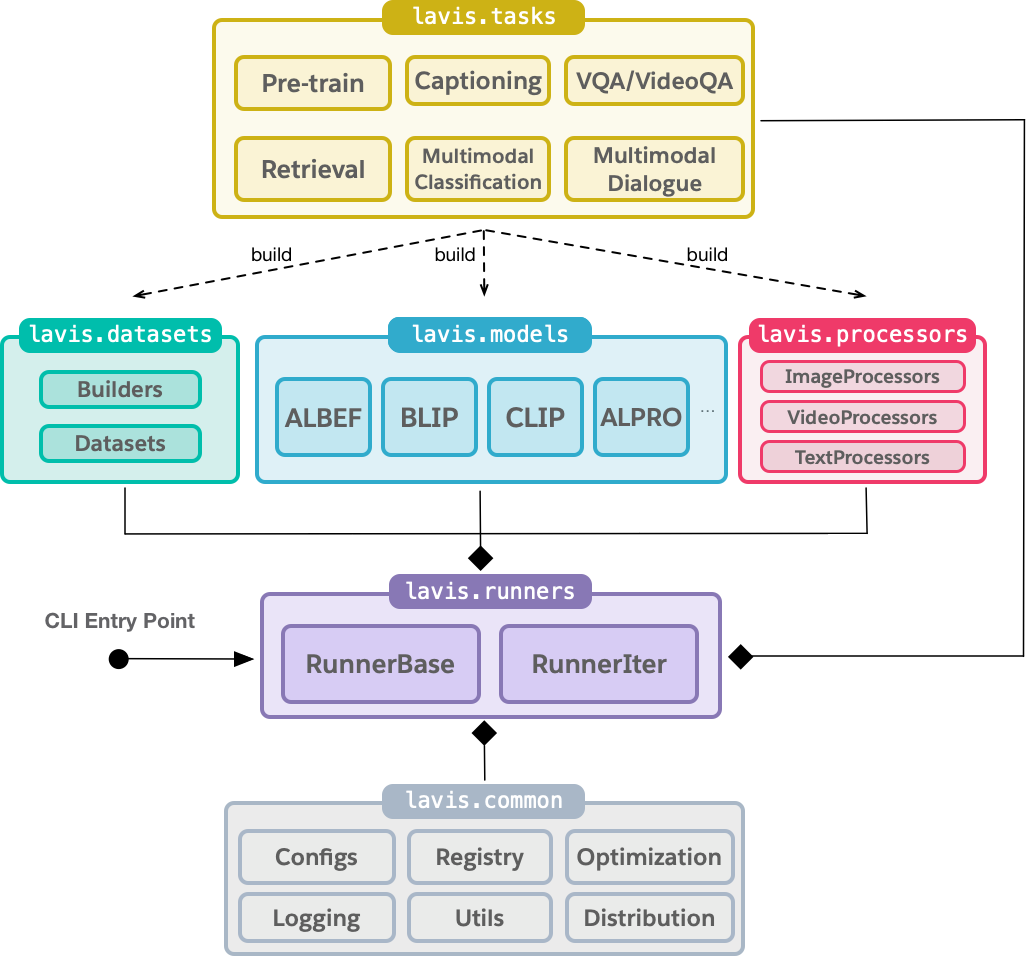
LAVIS简介
LAVIS(LAnguage-VISion)是Salesforce开源的一个用于语言-视觉智能研究和应用的Python深度学习库。它提供了一个统一的接口来访问多种最先进的语言-视觉基础模型(如ALBEF、BLIP、ALPRO、CLIP等),以及常见任务(如检索、图像描述、视觉问答等)和数据集(如COCO、Flickr、Nocaps等)。
LAVIS的主要特点包括:
- 模块化和可扩展的库设计
- 现成的预训练模型推理和特征提取
- 可复现的模型库和训练方案
- 数据集库和自动下载工具
快速入门
- 安装LAVIS:
pip install salesforce-lavis
- 加载预训练模型:
from lavis.models import load_model_and_preprocess
model, vis_processors, txt_processors = load_model_and_preprocess("blip_caption", "base_coco", device="cuda")
- 使用模型进行推理:
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
caption = model.generate({"image": image})
print(caption)
学习资源
-
LAVIS官方文档 - 详细介绍了LAVIS的架构、API和使用方法。
-
LAVIS GitHub仓库 - 包含源代码、示例和最新更新。
-
Jupyter Notebook示例 - 提供了多个任务的代码示例,如图像描述、特征提取、视觉问答等。
-
LAVIS技术报告 - 深入介绍LAVIS的设计原理和技术细节。
-
Benchmark - 提供了评估和训练支持模型的说明。
-
数据集下载指南 - 介绍如何下载和准备常用的语言-视觉数据集。
主要功能
LAVIS支持多种语言-视觉任务,包括:
- 图像-文本检索
- 视觉问答(VQA)
- 图像描述
- 视频-文本检索
- 视频问答
- 多模态特征提取
- 等等
同时支持多个顶级模型,如BLIP、ALBEF、CLIP等。
总结
LAVIS为语言-视觉AI研究和应用提供了一个强大而灵活的工具库。通过本文介绍的学习资源,读者可以快速上手LAVIS,开始探索多模态AI的无限可能。无论是研究人员还是工程师,都能从LAVIS中受益,加速语言-视觉智能技术的开发和应用。