
LAVIS简介
LAVIS是由Salesforce开发的一个用于语言-视觉智能研究和应用的Python深度学习库。它的目标是为工程师和研究人员提供一站式解决方案,以快速开发针对特定多模态场景的模型,并在标准和定制数据集上对其进行基准测试。
LAVIS具有以下主要特点:
-
统一模块化接口: 便于利用和重新利用现有模块(数据集、模型、预处理器),也便于添加新模块。
-
简单的开箱即用推理和特征提取: 现成的预训练模型让您可以在自己的数据上利用最先进的多模态理解和生成能力。
-
可复现的模型库和训练方案: 可以轻松复制和扩展现有任务和新任务上的最先进模型。
-
数据集库和自动下载工具: 准备众多语言-视觉数据集可能很麻烦。LAVIS提供自动下载脚本,帮助准备各种数据集及其注释。
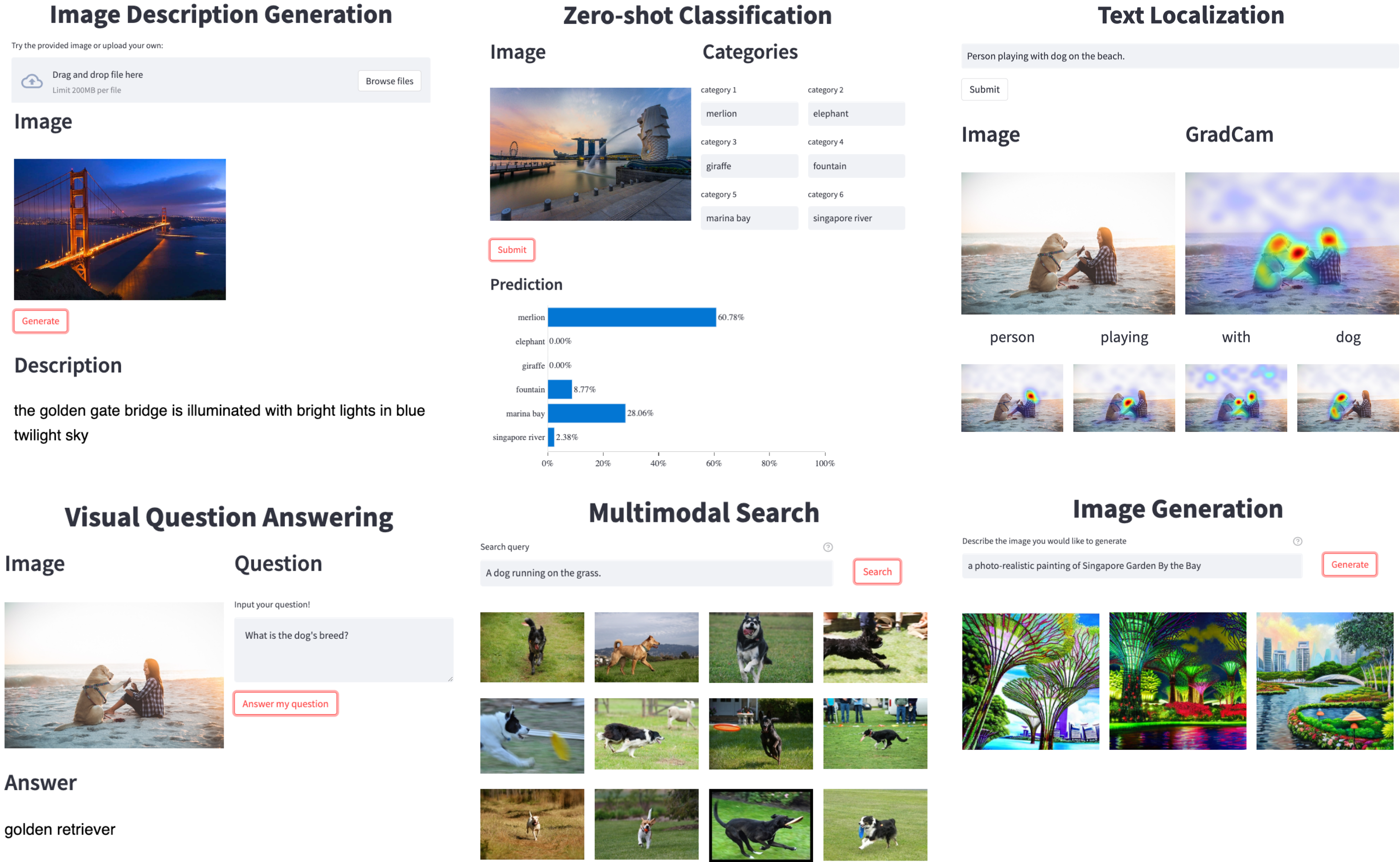
LAVIS支持:
- 10+任务(检索、字幕生成、视觉问答、多模态分类等)
- 20+数据集(COCO、Flickr、Nocaps、Conceptual Commons、SBU等)
- 30+最先进基础语言-视觉模型及其特定任务适配的预训练权重,包括ALBEF、BLIP、ALPRO、CLIP等
主要功能
模型库
LAVIS提供了丰富的预训练模型库,涵盖了多种语言-视觉任务:
from lavis.models import model_zoo
print(model_zoo)
输出显示了支持的模型架构和类型,如ALBEF、BLIP、CLIP等用于不同任务的变体。
图像字幕生成
使用BLIP模型为图像生成描述:
from lavis.models import load_model_and_preprocess
model, vis_processors, _ = load_model_and_preprocess(
name="blip_caption", model_type="base_coco", is_eval=True, device=device
)
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
caption = model.generate({"image": image})
print(caption) # ['a large fountain spewing water into the air']
视觉问答(VQA)
BLIP模型能够用自然语言回答关于图像的开放式问题:
model, vis_processors, txt_processors = load_model_and_preprocess(
name="blip_vqa", model_type="vqav2", is_eval=True, device=device
)
question = "Which city is this photo taken?"
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
question = txt_processors["eval"](question)
answer = model.predict_answers(
samples={"image": image, "text_input": question},
inference_method="generate"
)
print(answer) # ['singapore']
统一特征提取接口
LAVIS为每种架构提供了统一的特征提取接口:
model, vis_processors, txt_processors = load_model_and_preprocess(
name="blip_feature_extractor", model_type="base", is_eval=True, device=device
)
caption = "a large fountain spewing water into the air"
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
text_input = txt_processors["eval"](caption)
sample = {"image": image, "text_input": [text_input]}
features_multimodal = model.extract_features(sample)
features_image = model.extract_features(sample, mode="image")
features_text = model.extract_features(sample, mode="text")
这些特征可用于多模态分类或计算跨模态相似度。
加载数据集
LAVIS内置支持多种常见的语言-视觉数据集,并提供自动下载工具:
from lavis.datasets.builders import dataset_zoo, load_dataset
dataset_names = dataset_zoo.get_names()
print(dataset_names)
coco_dataset = load_dataset("coco_caption")
print(coco_dataset.keys())
print(len(coco_dataset["train"]))
print(coco_dataset["train"][0])
安装和使用
- 创建conda环境(可选):
conda create -n lavis python=3.8
conda activate lavis
- 从PyPI安装:
pip install salesforce-lavis
- 或从源代码构建:
git clone https://github.com/salesforce/LAVIS.git
cd LAVIS
pip install -e .
更多使用示例和高级用法,请参阅官方文档。
伦理和负责任使用
LAVIS中的模型在多模态能力方面不提供任何保证;可能会观察到不正确或有偏见的预测。特别是,LAVIS中使用的数据集和预训练模型可能包含社会经济偏见,这可能导致错误分类和其他不良行为,如冒犯性或不适当的言论。我们强烈建议用户在实际采用之前审查LAVIS中的预训练模型和整体系统。我们计划通过调查和缓解这些潜在的偏见和不当行为来改进该库。
总结
LAVIS为语言-视觉智能研究和应用提供了一个强大而灵活的工具包。通过其统一的接口、丰富的模型库和数据集支持,它极大地简化了多模态AI系统的开发过程。无论是进行学术研究还是构建实际应用,LAVIS都是一个值得考虑的优秀选择。










