
Linformer简介
Linformer是由Facebook AI Research团队在2020年提出的一种新型Transformer变体模型。它的主要创新点在于将传统Transformer中O(n^2)复杂度的自注意力机制改进为O(n)的线性复杂度,从而大大提高了模型的计算效率,使其能够处理更长的序列。
Linformer的核心思想是通过低秩矩阵分解来近似自注意力矩阵,将原本n×n的注意力矩阵压缩为n×k的形式,其中k远小于n。这种方法不仅降低了计算复杂度,还显著减少了内存占用,同时在多项NLP任务上保持了与标准Transformer相当的性能。
Linformer的核心原理
自注意力机制的线性化
标准Transformer中的自注意力机制计算如下:
Attention(Q, K, V) = softmax(QK^T / √d)V
其中Q、K、V分别是查询、键和值矩阵,维度均为n×d。这个计算过程的时间和空间复杂度都是O(n^2)。
Linformer通过引入两个投影矩阵E和F (维度均为k×n),将K和V投影到一个较低的维度k:
K' = EK, V' = FV
然后用K'和V'替代原始的K和V进行注意力计算:
Attention(Q, K', V') = softmax(QK'^T / √d)V'
这样,注意力矩阵的维度就从n×n变为了n×k,复杂度降为O(nk)。当k固定时,复杂度就变成了O(n)。
参数共享机制
为了进一步减少参数量,Linformer还引入了多种参数共享策略:
- 头间共享(headwise): 同一层的不同注意力头共享相同的E和F矩阵。
- 键值共享(kv): 使用同一个投影矩阵P来生成K'和V',即E=F=P。
- 层间共享(layerwise): 所有层和所有头共用同一组E和F矩阵。
这些共享策略可以大幅减少模型参数,同时实验表明对性能影响不大。
Linformer的优势
- 线性复杂度: 时间和空间复杂度都从O(n^2)降低到O(n),可以处理更长的序列。
- 内存效率高: 由于注意力矩阵被压缩,大大减少了内存占用。
- 可扩展性强: 适用于各种Transformer架构,如编码器、解码器等。
- 性能保持: 在多项NLP任务上,Linformer的性能与标准Transformer相当。
Linformer的应用
Linformer已经在多个自然语言处理任务中展现出了优秀的性能:
- 语言建模: 在WikiText-103数据集上,Linformer达到了与标准Transformer相当的困惑度,同时训练速度更快。
- 机器翻译: 在WMT'14 英德翻译任务中,Linformer的BLEU分数与标准Transformer相近。
- 文本分类: 在GLUE基准测试中,Linformer在多个子任务上的表现与BERT相当。
- 长文本处理: 由于其线性复杂度,Linformer特别适合处理长序列任务,如长文档摘要、长对话系统等。
Linformer的实现
以下是使用PyTorch实现Linformer的简单示例:
import torch
from linformer import LinformerLM
model = LinformerLM(
num_tokens = 20000,
dim = 512,
seq_len = 4096,
depth = 12,
heads = 8,
k = 256,
one_kv_head = True,
share_kv = False
)
x = torch.randint(0, 20000, (1, 4096))
output = model(x) # (1, 4096, 20000)
这个例子展示了如何创建一个Linformer语言模型,并对一个长度为4096的输入序列进行处理。
Linformer的局限性
尽管Linformer在效率方面有显著优势,但它也存在一些局限性:
- 固定序列长度: Linformer假设输入序列长度是固定的,这在某些动态长度的应用场景中可能不太灵活。
- 自回归能力受限: 由于其线性注意力机制,Linformer在自回归任务(如语言生成)中的表现可能不如标准Transformer。
- 近似带来的精度损失: 虽然在大多数任务中影响不大,但低秩近似inevitably会带来一定的精度损失。
结论
Linformer作为一种高效的Transformer变体,通过巧妙的低秩近似和参数共享策略,成功将自注意力机制的复杂度从二次降低到线性,为处理长序列NLP任务提供了新的可能性。虽然它也有一些局限性,但其在效率和性能之间取得的平衡使其成为一个非常有前景的模型,特别是在需要处理大规模数据和长序列的场景中。
随着深度学习模型规模的不断增大,像Linformer这样能够提高计算效率的创新将变得越来越重要。我们可以期待在Linformer的基础上,未来会出现更多改进的高效Transformer变体,进一步推动自然语言处理技术的发展。
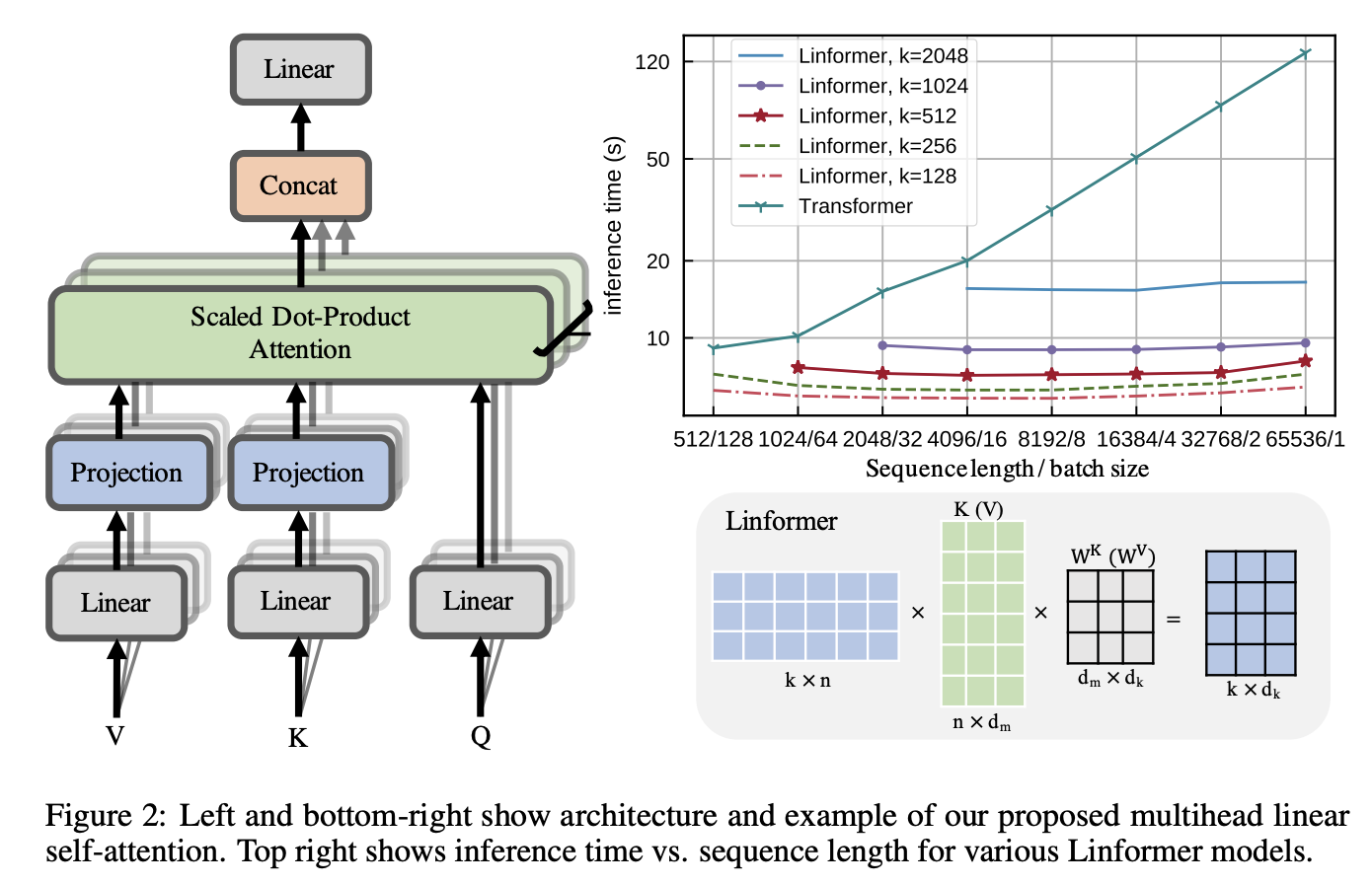
图1: Linformer的整体架构
参考文献
-
Wang, S., Li, B. Z., Khabsa, M., Fang, H., & Ma, H. (2020). Linformer: Self-Attention with Linear Complexity. arXiv preprint arXiv:2006.04768.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
Linformer为我们展示了如何通过巧妙的数学技巧来优化深度学习模型的效率。它不仅是一个具体的模型实现,更代表了一种思路——在保持模型表达能力的同时,如何突破计算瓶颈,使模型能够应对更大规模的数据和更复杂的任务。这种思路无疑将继续推动人工智能领域的创新和发展。









