
引言
大型语言模型(LLM)已成为自然语言处理领域的重要突破。作为最新一代的LLM之一,Llama 3展现出了惊人的性能。但是,这些复杂的模型内部到底是如何工作的呢?本文将带领读者从零开始实现Llama 3,深入剖析模型的每个组成部分,揭示其内部运作机制。
模型概览
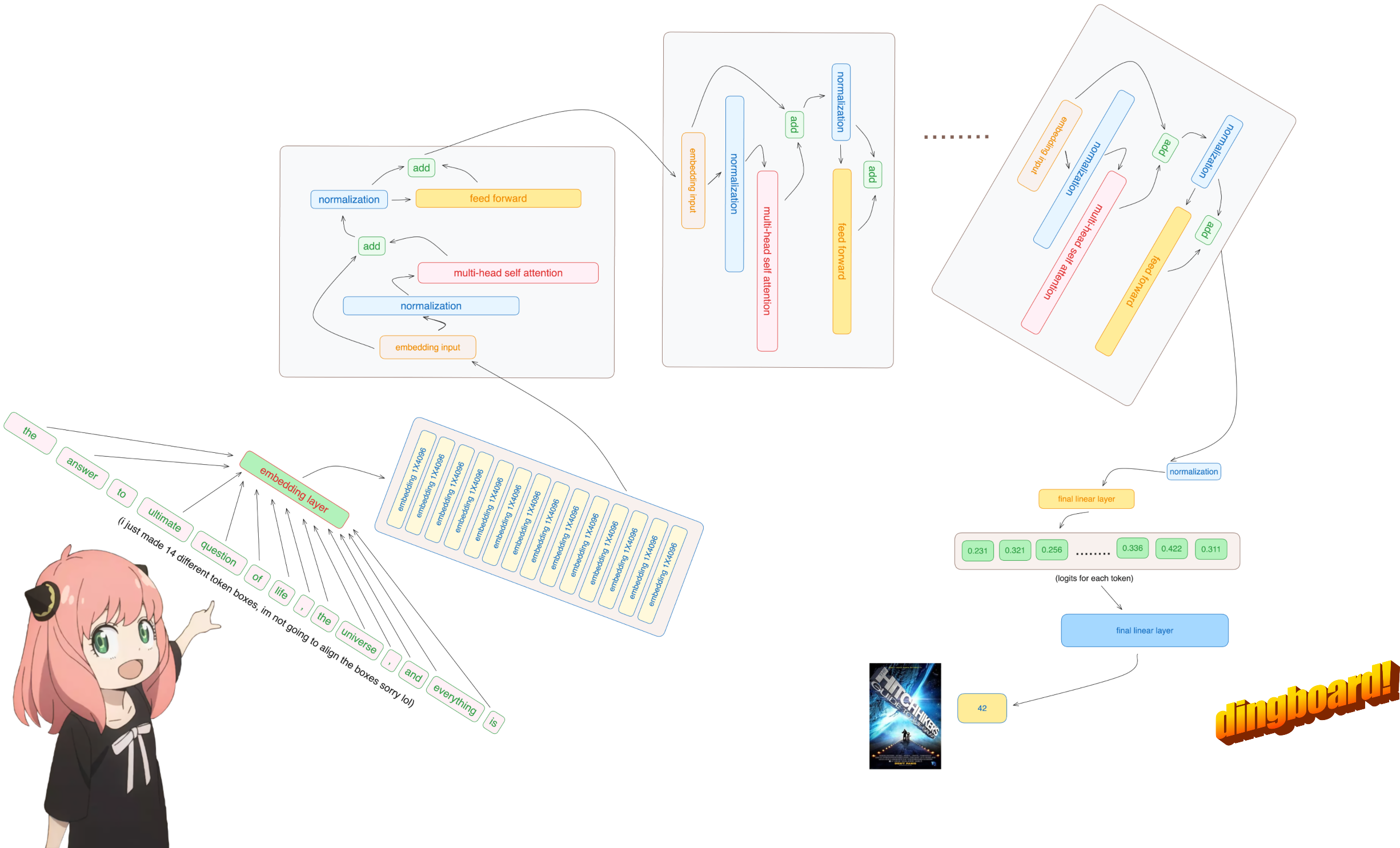
Llama 3是一个基于Transformer架构的大型语言模型。它主要由以下几个部分组成:
- 分词器
- 嵌入层
- 多层Transformer块
- 多头注意力机制
- 前馈神经网络
- 输出层
让我们逐步深入每个组件,看看它们是如何协同工作的。
分词器
分词是处理自然语言的第一步。Llama 3使用BPE(Byte Pair Encoding)分词算法。虽然我们不会从头实现分词器,但了解其原理很有必要。
BPE算法通过迭代合并最频繁出现的字符对来学习子词。这种方法可以有效平衡词汇表大小和未知词的处理。
在本实现中,我们使用tiktoken库来加载和使用Llama 3的分词器:
import tiktoken
from tiktoken.load import load_tiktoken_bpe
tokenizer_path = "Meta-Llama-3-8B/tokenizer.model"
mergeable_ranks = load_tiktoken_bpe(tokenizer_path)
tokenizer = tiktoken.Encoding(
name=Path(tokenizer_path).name,
pat_str=r"...",
mergeable_ranks=mergeable_ranks,
special_tokens={...}
)
使用这个分词器,我们可以将输入文本转换为token ID序列:
prompt = "the answer to the ultimate question of life, the universe, and everything is "
tokens = [128000] + tokenizer.encode(prompt)
嵌入层
分词后的输入需要转换为连续的向量表示,这就是嵌入层的作用。Llama 3使用学习得到的嵌入矩阵来完成这一步:
embedding_layer = torch.nn.Embedding(vocab_size, dim)
embedding_layer.weight.data.copy_(model["tok_embeddings.weight"])
token_embeddings = embedding_layer(tokens).to(torch.bfloat16)
这里,vocab_size是词汇表大小,dim是嵌入维度。嵌入后,每个token都变成了一个dim维的向量。
Transformer块
Transformer块是Llama 3的核心部分,包含多头注意力机制和前馈神经网络。让我们详细看看它们是如何实现的。
多头注意力机制
多头注意力是Transformer的关键创新,允许模型同时关注输入的不同部分。它包括以下步骤:
- 线性变换生成查询(Q)、键(K)和值(V)
- 计算注意力分数
- softmax归一化
- 加权聚合值向量
以下是第一个注意力头的实现:
# 查询变换
q_layer0 = model["layers.0.attention.wq.weight"]
q_layer0 = q_layer0.view(n_heads, head_dim, dim)
q_layer0_head0 = q_layer0[0]
q_per_token = torch.matmul(token_embeddings, q_layer0_head0.T)
# 键变换
k_layer0 = model["layers.0.attention.wk.weight"]
k_layer0 = k_layer0.view(n_kv_heads, k_layer0.shape[0] // n_kv_heads, dim)
k_layer0_head0 = k_layer0[0]
k_per_token = torch.matmul(token_embeddings, k_layer0_head0.T)
# 值变换
v_layer0 = model["layers.0.attention.wv.weight"]
v_layer0 = v_layer0.view(n_kv_heads, v_layer0.shape[0] // n_kv_heads, dim)
v_layer0_head0 = v_layer0[0]
v_per_token = torch.matmul(token_embeddings, v_layer0_head0.T)
# 计算注意力分数
qk_per_token = torch.matmul(q_per_token, k_per_token.T)/(head_dim)**0.5
# 掩码和softmax
mask = torch.triu(torch.full((len(tokens), len(tokens)), float("-inf")), diagonal=1)
qk_per_token_masked = qk_per_token + mask
qk_per_token_softmax = torch.nn.functional.softmax(qk_per_token_masked, dim=1)
# 加权聚合
qkv_attention = torch.matmul(qk_per_token_softmax, v_per_token)
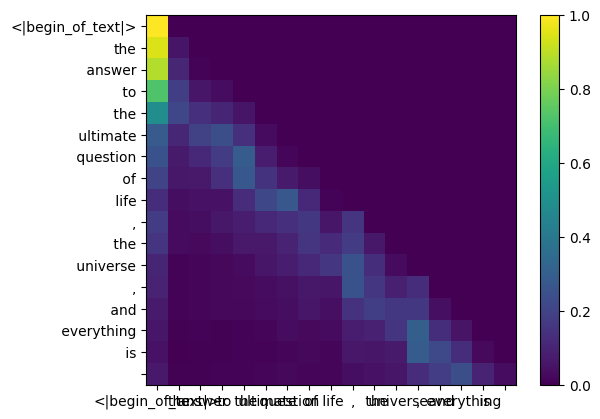
值得注意的是,Llama 3使用旋转位置编码(RoPE)来加入位置信息:
freqs = 1.0 / (rope_theta ** (torch.arange(64)/64))
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token)
q_rotated = q_per_token * freqs_cis
k_rotated = k_per_token * freqs_cis
前馈神经网络
在注意力层之后,每个Transformer块还包含一个前馈神经网络:
def feed_forward(x):
x = torch.matmul(x, model["layers.0.feed_forward.w1.weight"].T)
x = torch.nn.functional.silu(x)
x = torch.matmul(x, model["layers.0.feed_forward.w2.weight"].T)
return x
ff_output = feed_forward(qkv_attention)
输出层
最后,模型使用一个线性层将最终的隐藏状态映射到词汇表大小的logits:
output_layer = torch.nn.Linear(dim, vocab_size)
output_layer.weight = model["output.weight"]
logits = output_layer(ff_output)
生成过程
有了完整的前向传播,我们就可以进行文本生成了。基本步骤如下:
- 对输入提示进行编码
- 重复以下步骤直到生成足够的token:
- 运行模型前向传播
- 从输出logits中采样下一个token
- 将新token添加到输入序列
def generate(prompt, max_new_tokens):
tokens = tokenizer.encode(prompt)
for _ in range(max_new_tokens):
logits = model_forward(tokens)
next_token = sample_token(logits[-1])
tokens.append(next_token)
if next_token == tokenizer.eos_token_id:
break
return tokenizer.decode(tokens)
结论
通过从零实现Llama 3,我们深入了解了大型语言模型的内部工作原理。从分词、嵌入到多头注意力和前馈网络,每个组件都扮演着重要角色。这种理解不仅有助于更好地使用和调优模型,还为进一步创新奠定了基础。
尽管完整实现一个大型语言模型是一项复杂的任务,但掌握其核心概念和原理将大大提高我们在NLP领域的能力。随着技术的不断发展,我们期待看到更多令人兴奋的突破。
进一步探索
如果你对Llama 3感兴趣并想深入研究,这里有一些建议:
- 尝试实现完整的模型,包括多层Transformer块。
- 探索不同的采样策略,如Top-k采样、核采样等。
- 研究模型压缩技术,如知识蒸馏、量化等。
- 尝试在特定任务上微调模型。
记住,理解和实现这样的模型是一个循序渐进的过程。保持好奇心和耐心,你会发现NLP的魅力所在。
参考资源
通过本文的学习,相信你已经对Llama 3的内部工作原理有了深入的理解。继续探索,勇于尝试,你将在NLP的道路上越走越远!


















