
llama2.c的简明教程:从零开始理解大语言模型推理
大语言模型(LLM)已经成为人工智能领域的热门话题,但对于很多人来说,其内部工作原理仍然是一个黑盒。本文将通过解析llama2.c这个简化的LLM推理实现,带领读者一步步揭开大语言模型的神秘面纱。
为什么要学习llama2.c?
llama2.c是由著名AI研究者Andrej Karpathy开发的一个极简的LLM推理实现。它仅用700行C代码就实现了Llama 2模型的完整推理过程,是学习大语言模型原理的绝佳材料。相比庞大复杂的生产级实现,llama2.c去除了所有不必要的细节,让我们可以专注于LLM的核心原理。
Transformer模型结构概览
在深入代码之前,我们先快速回顾一下Transformer模型的基本结构:
- 嵌入层:将输入token转换为向量表示
- Transformer层(重复多次):
- 多头自注意力机制
- 前馈神经网络
- 分类层:预测下一个token的概率分布
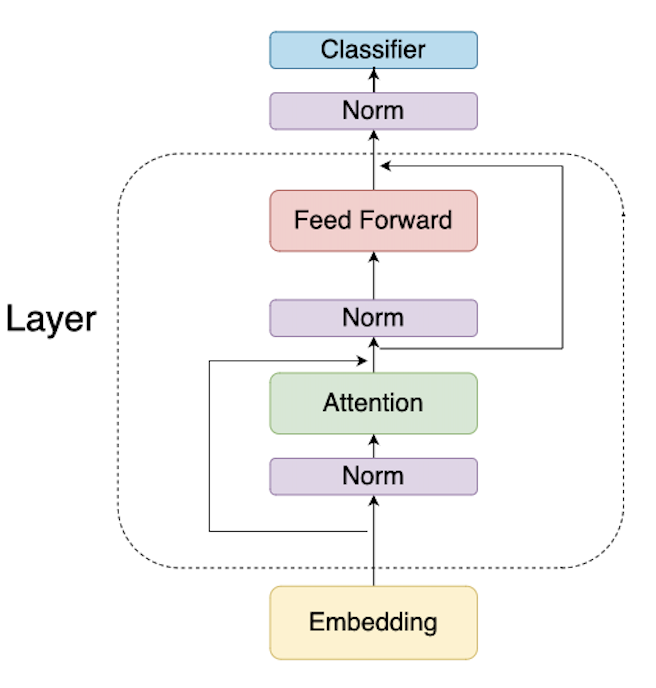
llama2.c的代码结构也与此对应,主要包含三个部分:结构体定义、主循环逻辑和前向传播函数。接下来我们将逐一剖析这些关键部分。
核心数据结构
llama2.c定义了三个重要的结构体:
- Config:存储模型配置,如层数、维度等
- TransformerWeights:存储模型权重
- RunState:存储推理过程中的中间状态
这些结构体的定义非常直观,与Transformer的组成一一对应。例如:
typedef struct {
int dim; // transformer维度
int hidden_dim; // 前馈网络隐藏层维度
int n_layers; // 层数
int n_heads; // 注意力头数
int n_kv_heads; // Key/Value头数
int vocab_size; // 词表大小
int seq_len; // 最大序列长度
} Config;
主循环逻辑
llama2.c的main函数实现了整个推理过程的主循环:
- 初始化:加载模型配置和权重
- 对输入prompt进行编码
- 循环生成:
- 调用transformer函数进行前向传播
- 根据输出logits采样下一个token
- 将新token加入序列,继续下一轮生成
这个过程直观地展示了LLM是如何一步步生成文本的。
前向传播详解
transformer函数实现了模型的核心前向传播逻辑,包括:
- 词嵌入查找
- 位置编码(RoPE)
- 自注意力计算
- 前馈网络
- 残差连接和层归一化
让我们重点看看自注意力机制的实现:
// 计算注意力分数
for (int t = 0; t <= pos; t++) {
float* k = s->key_cache + loff + t * dim + h * head_size;
float score = 0.0f;
for (int i = 0; i < head_size; i++) {
score += q[i] * k[i];
}
score /= sqrtf(head_size);
att[t] = score;
}
// Softmax并加权求和
softmax(att, pos + 1);
for (int t = 0; t <= pos; t++) {
float* v = s->value_cache + loff + t * dim + h * head_size;
float a = att[t];
for (int i = 0; i < head_size; i++) {
xb[i] += a * v[i];
}
}
这段代码清晰地展示了自注意力的计算过程:query与所有key做点积,归一化后得到注意力权重,最后对value进行加权求和。

采样与生成
生成过程中的一个关键步骤是根据模型输出的logits采样下一个token。llama2.c实现了两种采样方式:
- 贪婪搜索:始终选择概率最高的token
- 温度采样:根据温度参数调节分布,增加随机性
if (temperature == 0.0f) {
// 贪婪搜索
next = argmax(state.logits, config.vocab_size);
} else {
// 温度采样
for (int q=0; q<config.vocab_size; q++) {
state.logits[q] /= temperature;
}
softmax(state.logits, config.vocab_size);
next = sample(state.logits, config.vocab_size);
}
这种灵活的采样策略让模型可以在确定性和创造性之间取得平衡。
结语
通过解析llama2.c,我们深入了解了大语言模型推理的全过程。从数据结构的设计到核心算法的实现,llama2.c为我们揭示了LLM的内部工作原理。这种知识不仅有助于我们更好地理解和使用现有的LLM,还为进一步改进和创新奠定了基础。
大语言模型技术正在飞速发展,但其核心原理依然基于我们在本文中讨论的这些基本概念。通过学习llama2.c,我们获得了理解更复杂LLM实现的钥匙。希望这篇教程能激发你进一步探索AI领域的兴趣!

最后,用这只可爱的小猫咪结束我们的教程。就像这只好奇的小猫一样,保持对新知识的好奇和探索精神,你一定会在AI的广阔天地中有更多精彩发现!









