
LLM Comparator简介
在人工智能和自然语言处理领域,大语言模型(Large Language Models, LLMs)的发展日新月异。随着不同LLMs的不断涌现,如何有效地评估和比较不同模型的性能成为了一个关键问题。为了解决这一挑战,Google的PAIR(People + AI Research)团队开发了一款名为LLM Comparator的创新工具。
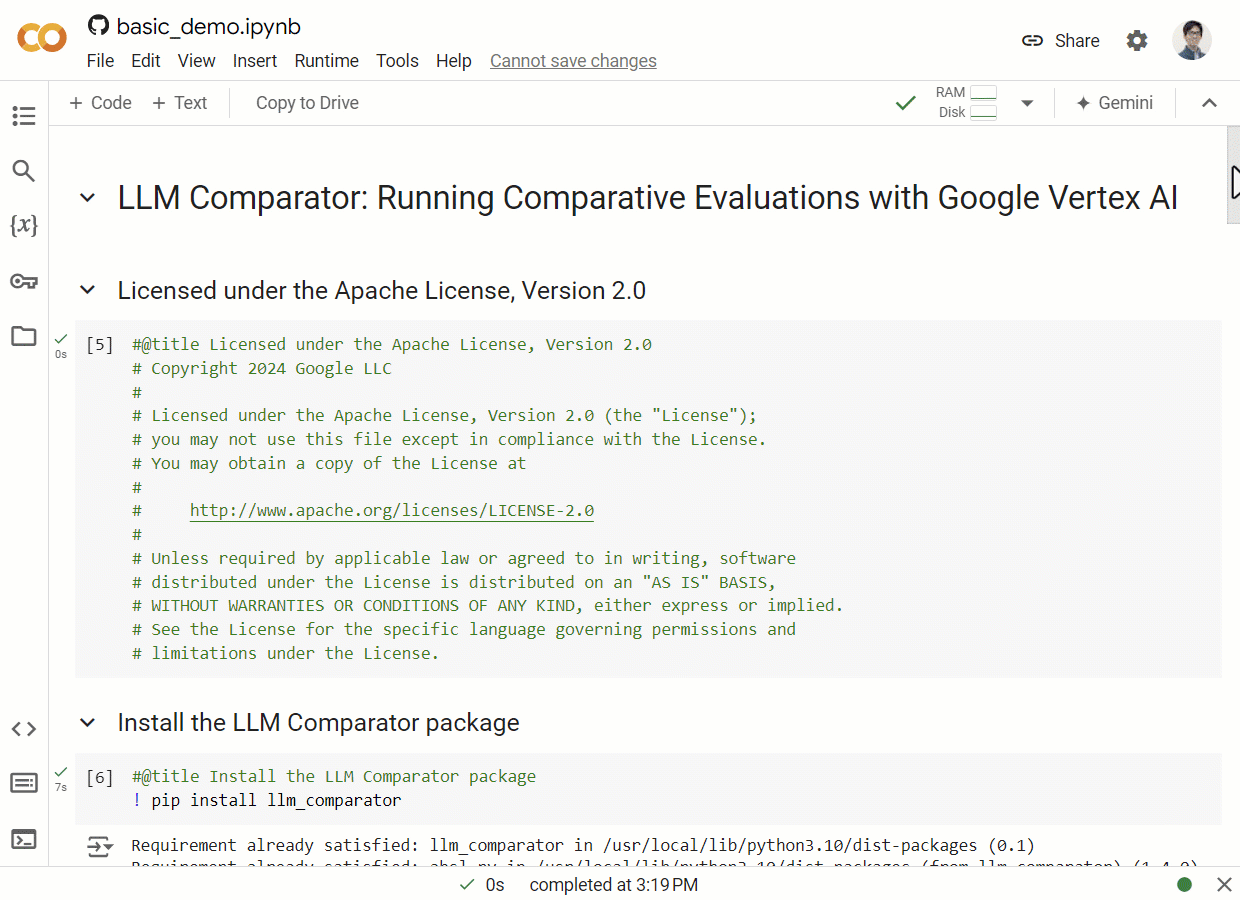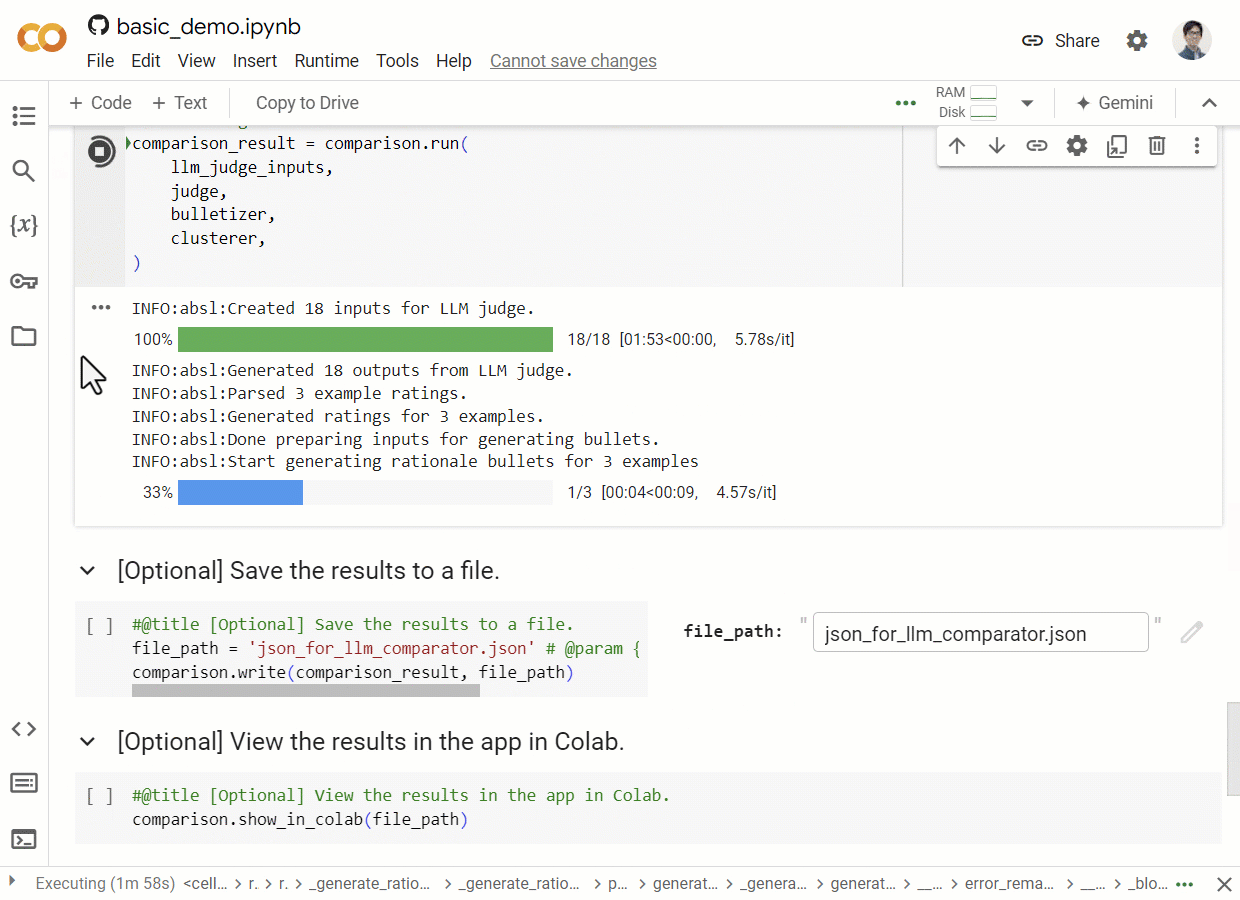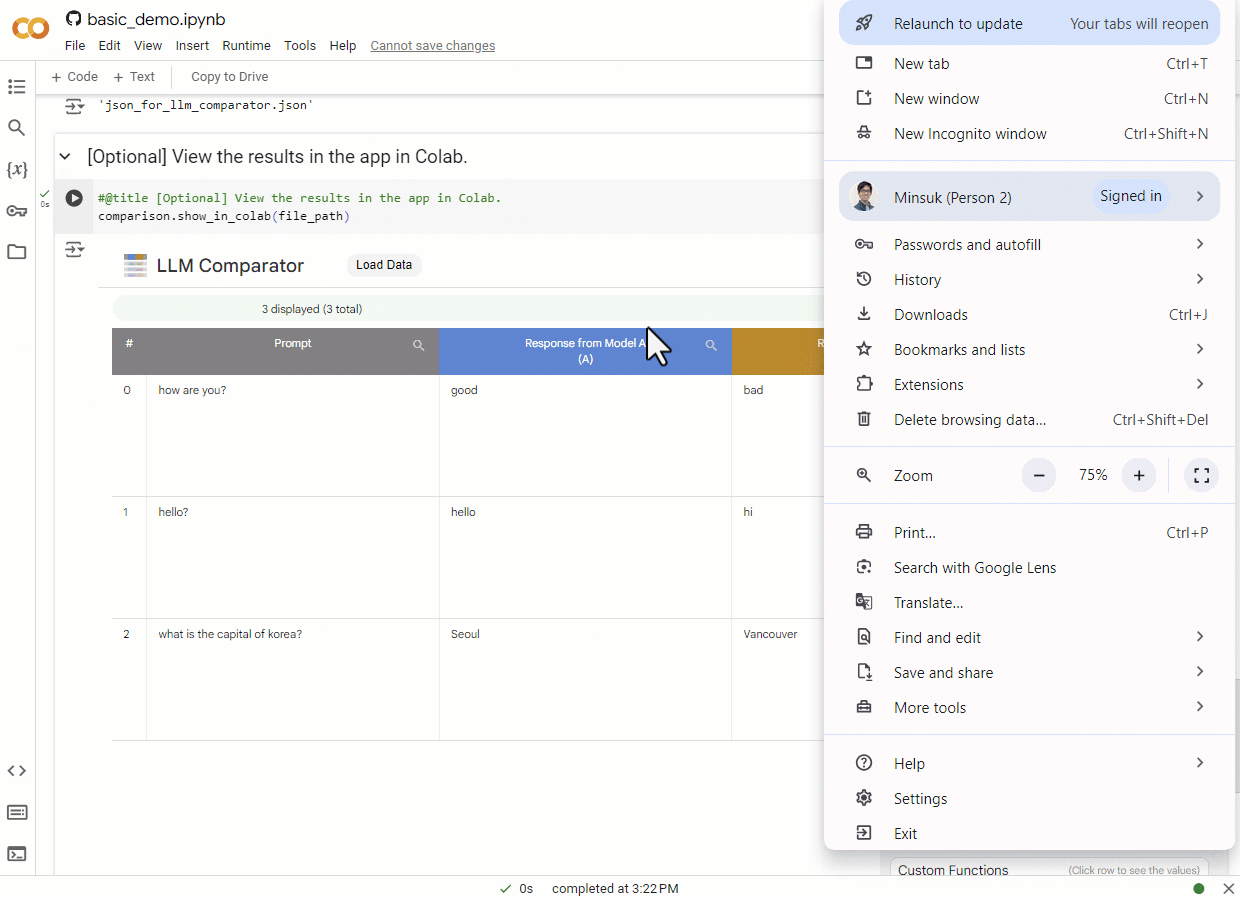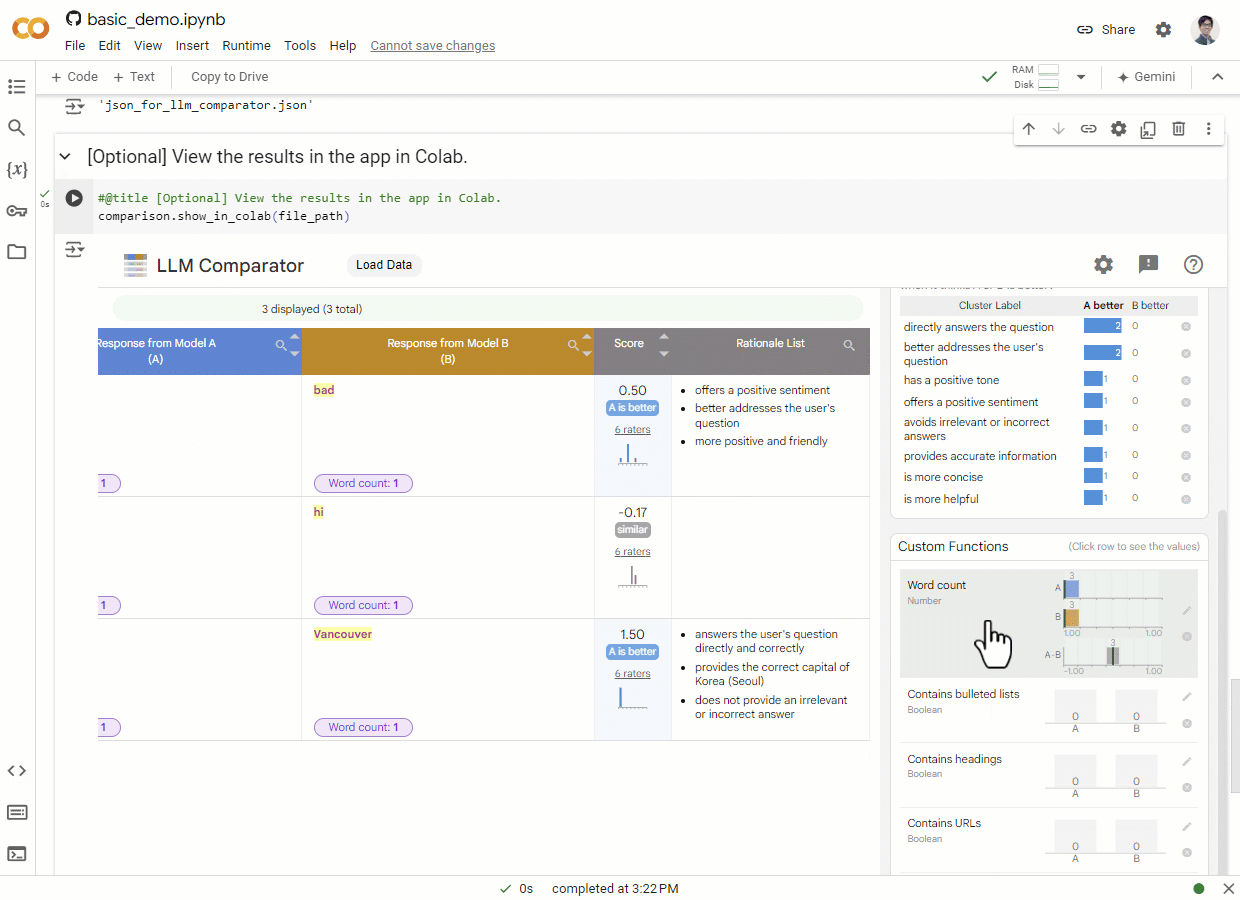
LLM Comparator是一个交互式的数据可视化工具,专门用于分析LLM并排评估的结果。它的设计初衷是帮助用户以定性的方式分析两个模型的响应在示例级别和切片级别上的差异。通过使用这个工具,用户可以交互式地发现诸如"模型A在电子邮件重写任务上表现比模型B更好,因为模型A更倾向于生成项目符号列表"这样的洞察。
LLM Comparator的核心功能
1. 可视化分析
LLM Comparator提供了丰富的可视化界面,包括评分分布图、按提示类别的指标图表、理由摘要面板等。这些可视化元素使用户能够直观地了解两个模型在各个方面的表现差异。
2. 交互式探索
用户可以通过交互式界面深入探索数据,例如筛选特定类别的提示、查看个别示例的详细信息、自定义分析函数等。这种交互性使得分析过程更加灵活和深入。
3. 定制化分析
LLM Comparator支持用户添加自定义字段和分析函数,以满足特定的评估需求。这种灵活性使得工具可以适应各种不同的评估场景。
4. 并排评估结果呈现
工具可以清晰地展示两个模型对同一提示的响应,以及相应的评分和理由。这种并排的呈现方式有助于用户直观地比较模型输出的质量。
使用LLM Comparator
使用LLM Comparator非常简单。用户可以通过访问https://pair-code.github.io/llm-comparator/来使用在线版本的工具。该工具提供了一些示例文件供用户体验,同时也支持用户上传自己的JSON格式数据文件进行分析。
数据格式要求
为了使用LLM Comparator,用户需要准备符合特定格式的JSON数据文件。这个文件应该包含以下关键信息:
- 输入提示
- 两个模型(模型A和模型B)对每个提示的响应
- 基于并排评估得到的数值评分
- 提示的标签或类别信息
- (可选)自定义字段,如词数、安全评分等
示例:比较Gemma 1.1和1.0
LLM Comparator的官方示例展示了如何比较Gemma 1.1和1.0两个版本的模型响应。这个示例使用了来自Chatbot Arena Conversations数据集的提示。用户可以通过以下链接直接体验这个示例:
通过这个示例,用户可以探索:
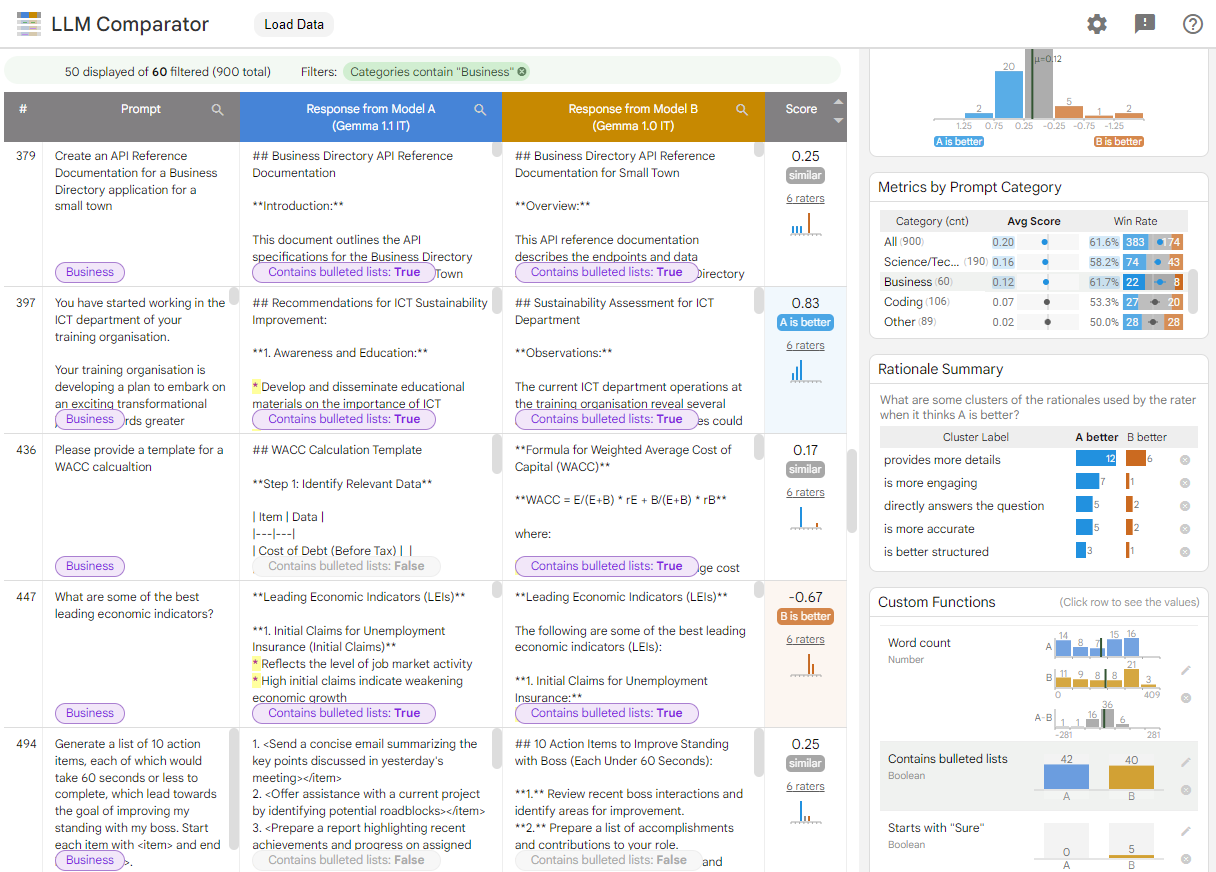
- 何时:分数分布和按提示类别的指标面板显示,模型A(Gemma 1.1)的响应质量被认为优于模型B(Gemma 1.0)。
- 为什么:理由摘要面板深入分析了这些分数差异背后的原因,如详细程度、简洁性、结构等因素。
- 如何:自定义函数面板帮助发现具体差异,例如Gemma 1.1更倾向于使用项目符号列表,而Gemma 1.0则更多以"Sure"开头回答。
Python库:创建JSON文件
为了方便用户准备数据,LLM Comparator项目还提供了一个Python库。这个库可以帮助用户创建符合要求的JSON文件,包括执行并排LLM评估和理由聚类等步骤。用户可以通过运行basic_demo.ipynbnotebook来快速创建JSON文件并查看结果。
高级功能
1. 自定义字段
LLM Comparator支持用户添加各种类型的自定义字段,如数字、类别、文本、图片等。这些自定义字段可以在表格中显示,并在界面右侧以图表形式呈现聚合信息。
2. 个别评分
考虑到LLM评估中的位置偏差和非确定性采样,LLM Comparator允许用户提供多次评估的详细信息。这使得用户可以分析评分分布和LLM评判使用的理由。
本地开发
对于想要在本地环境中开发或定制LLM Comparator的用户,项目提供了详细的设置说明:
git clone https://github.com/PAIR-code/llm-comparator.git
cd llm-comparator
npm install
npm run build
npm run serve
LLM Comparator的重要性
LLM Comparator在LLM评估和分析领域具有重要意义:
- 提高评估效率: 通过可视化和交互式界面,大大提高了LLM评估的效率。
- 深入洞察: 帮助研究人员和工程师更好地理解不同模型的优缺点。
- 促进模型改进: 通过详细的分析,为模型的改进提供了明确的方向。
- 标准化评估流程: 为LLM的评估提供了一个标准化的工具和流程。
- 跨模型比较: 便于不同模型之间的直接比较,促进了LLM领域的良性竞争和发展。
结语
LLM Comparator作为一个强大的可视化分析工具,为大语言模型的评估和比较提供了新的可能性。它不仅提高了评估的效率和深度,还为研究人员和工程师提供了宝贵的洞察。随着LLM技术的不断发展,像LLM Comparator这样的工具将在推动技术进步和提高模型质量方面发挥越来越重要的作用。
值得注意的是,LLM Comparator仍是一个处于积极开发阶段的研究项目。尽管可能存在一些bug,但其开发团队认为它已经相当有用,因此选择在早期阶段发布。我们期待看到这个工具在未来的发展和完善,以及它在LLM评估领域带来的更多创新。
如果您在研究或工作中使用了LLM Comparator,请引用其研究论文:https://arxiv.org/abs/2402.10524。这不仅是对开发团队工作的认可,也有助于推动LLM评估技术的进一步发展。
最后,让我们共同期待LLM Comparator在未来为人工智能和自然语言处理领域带来更多突破性的贡献! 🚀🔍💡









