
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文LLM 比较器
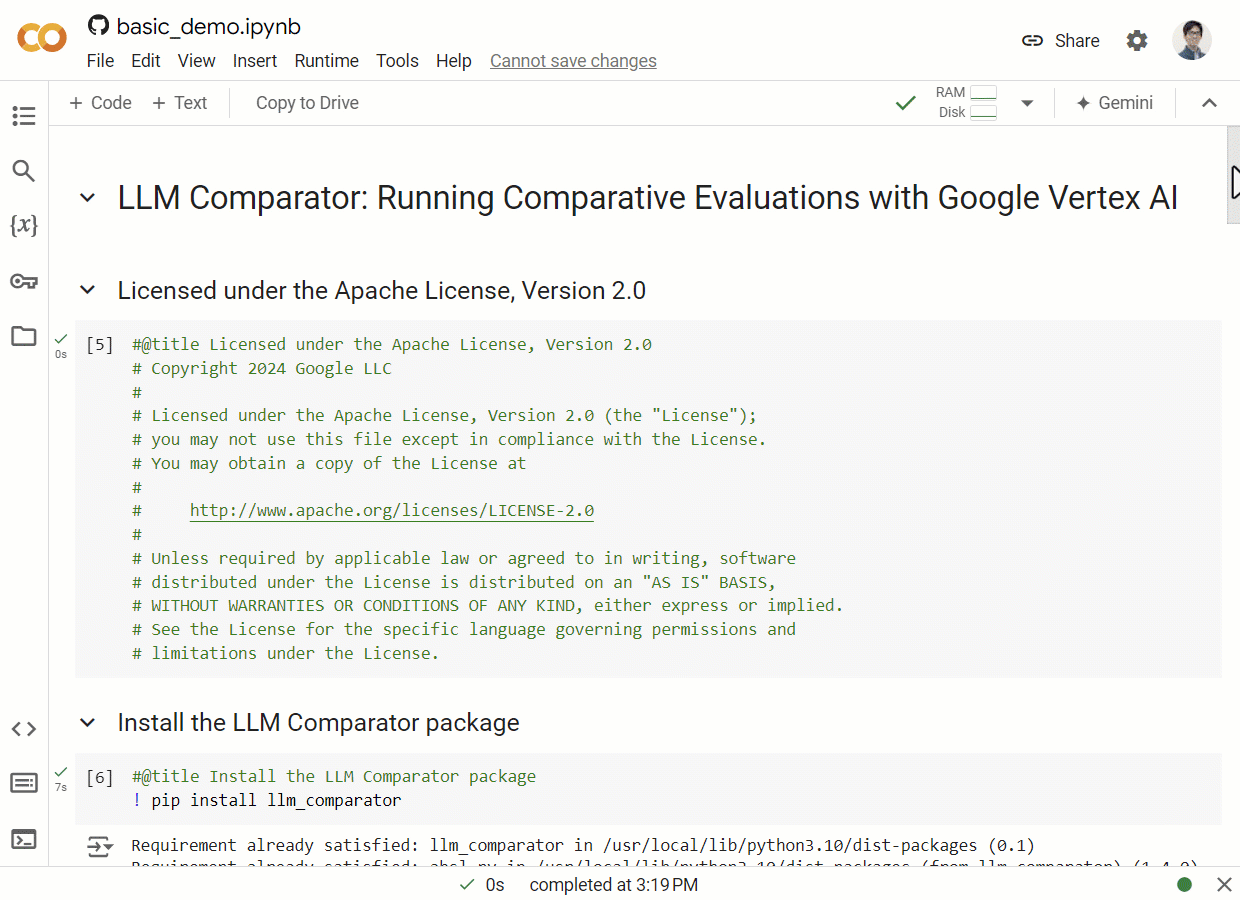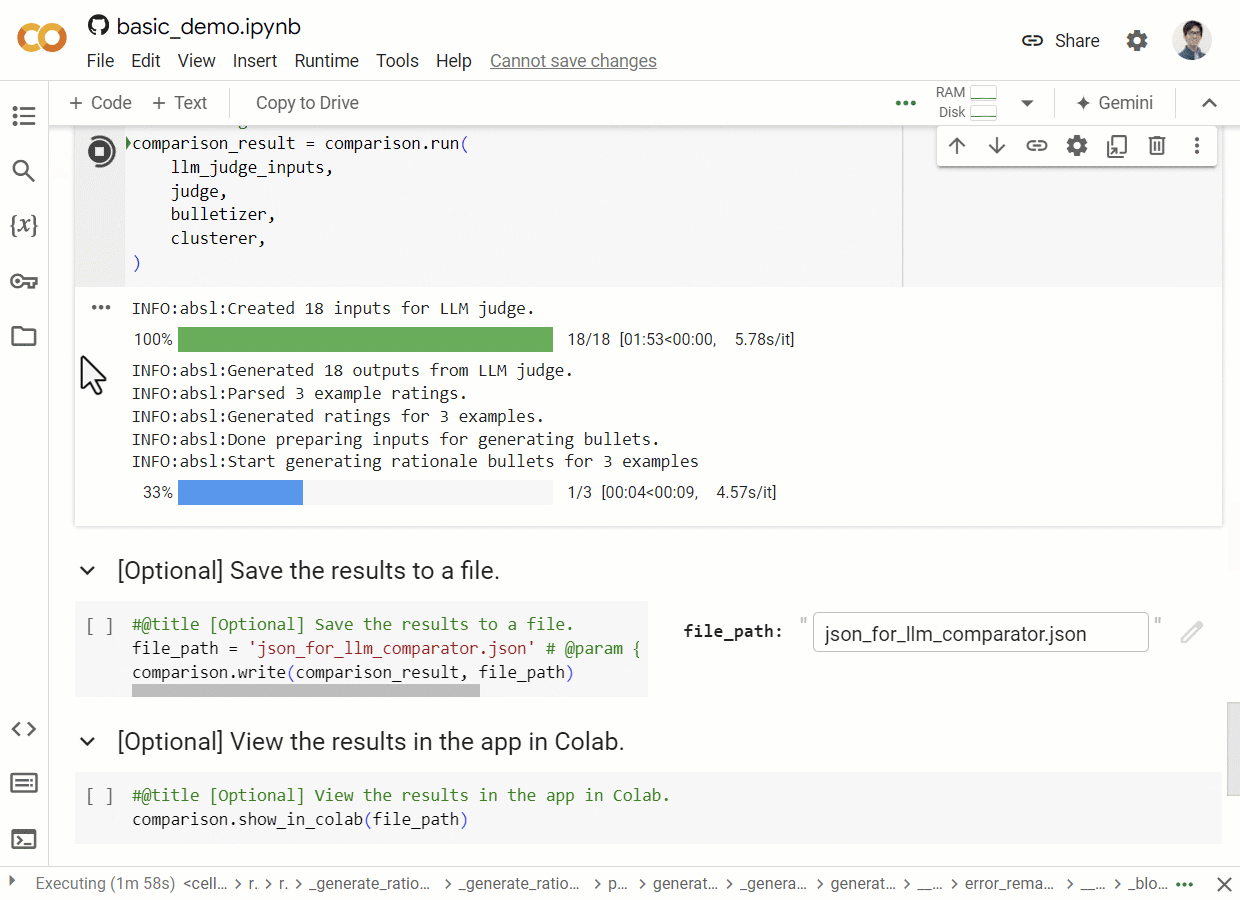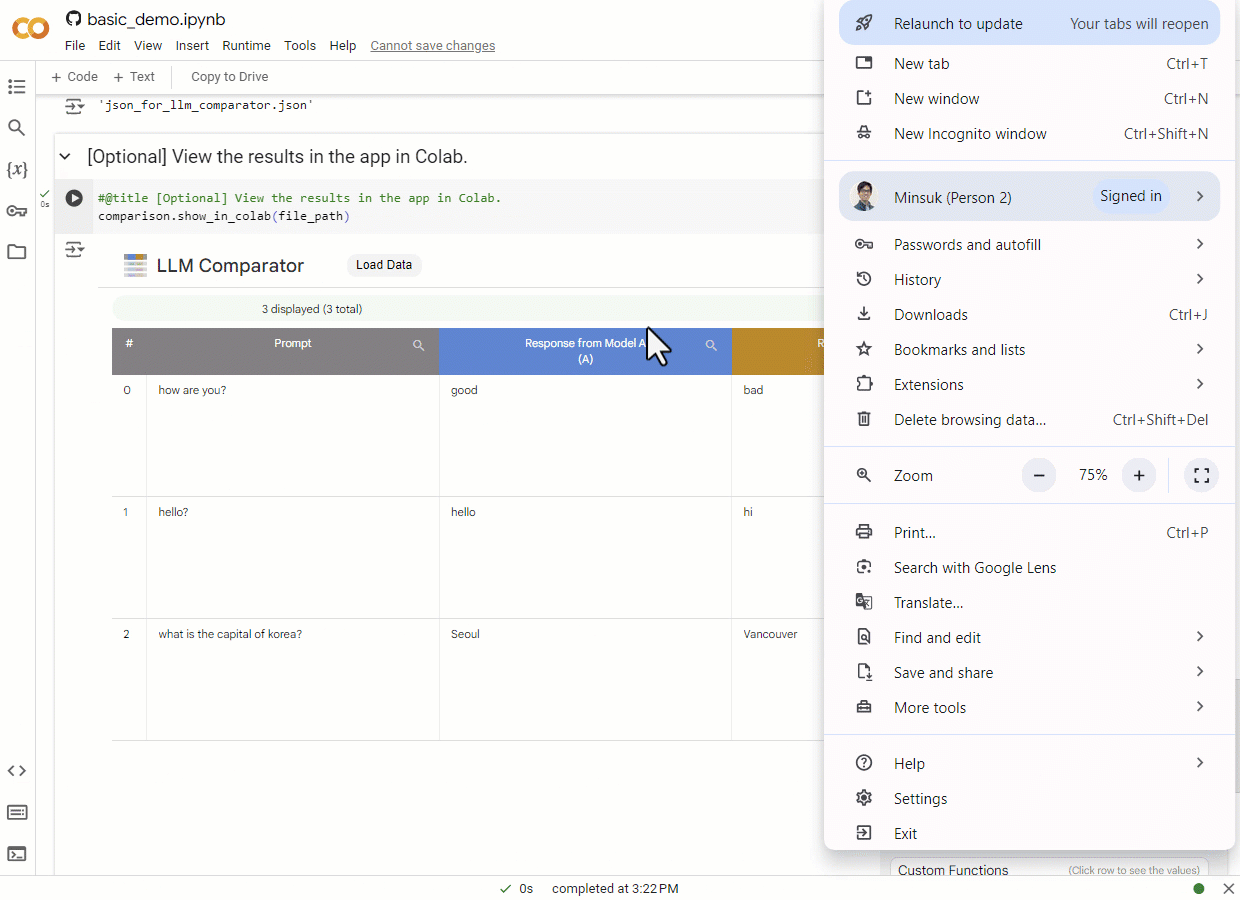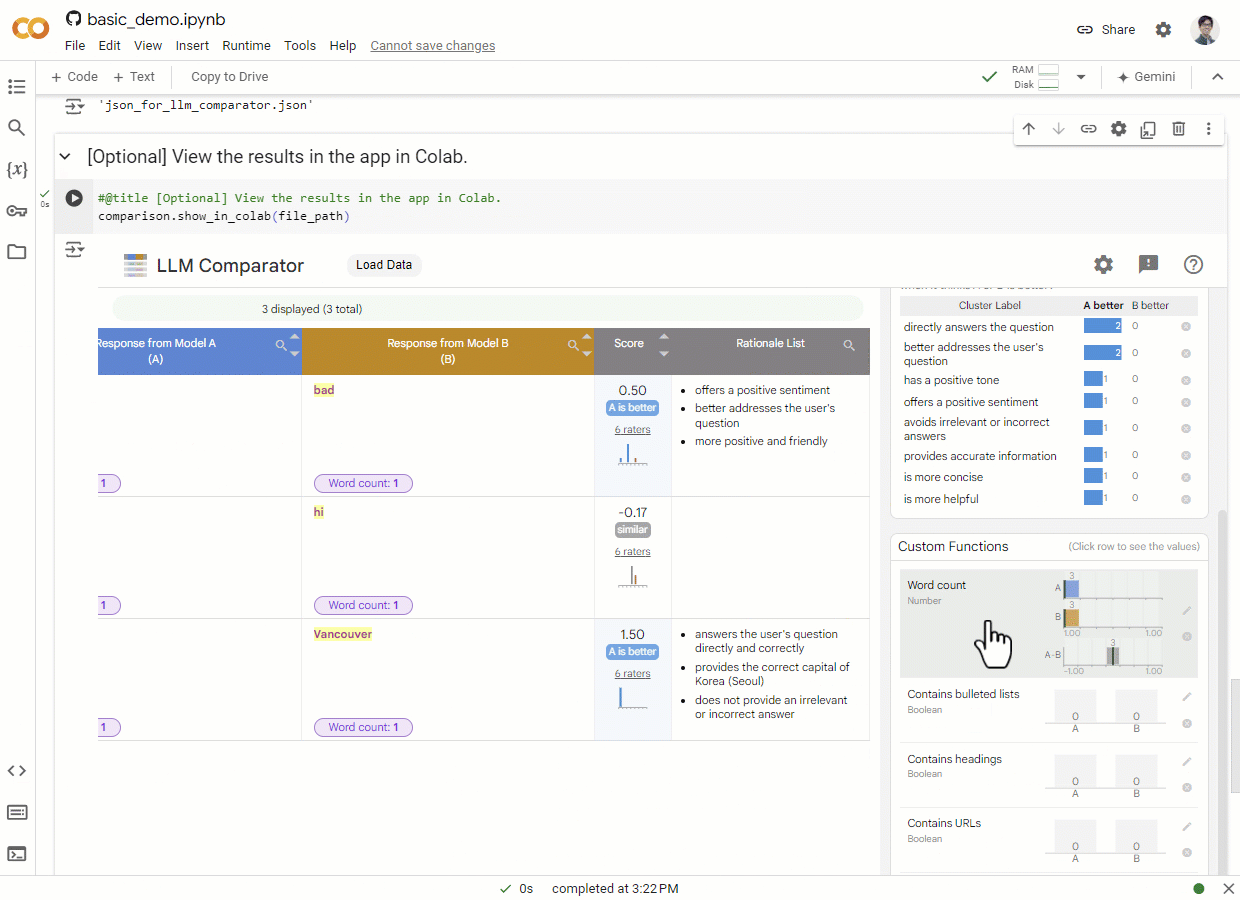
LLM比较器是一个交互式可视化工具,附带有Python库,用于分析并列的LLM评估结果。
它旨在帮助人们定性地分析两个模型的响应在示例和切片层面上的差异。用户可以交互式地发现见解,例如"模型A在电子邮件改写任务上的响应比模型B更好,因为模型A倾向于更频繁地生成项目符号列表。"
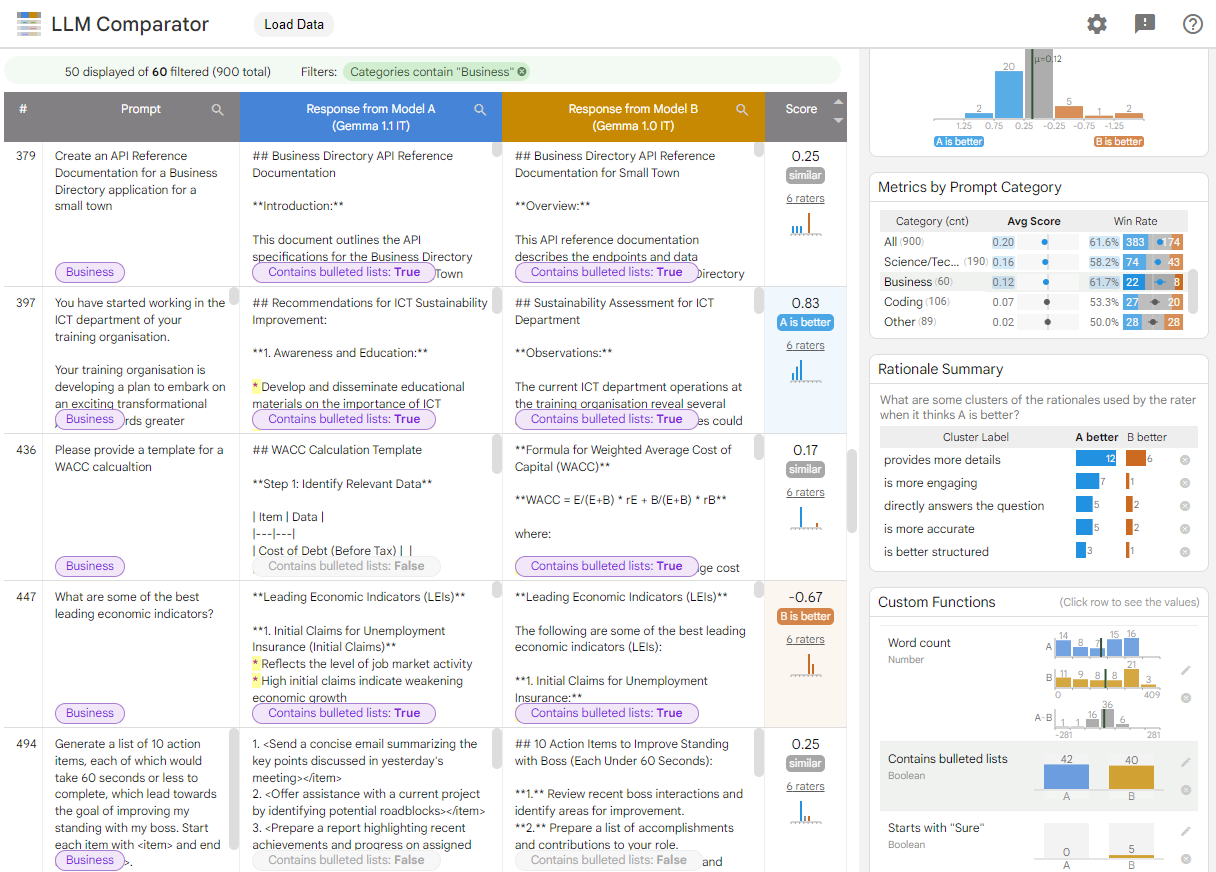
使用LLM比较器
你可以在https://pair-code.github.io/llm-comparator/尝试LLM比较器。
你可以选择我们提供的示例文件之一,也可以上传自己的JSON文件(例如最小示例文件),该文件遵循我们下面描述的格式。
比较Gemma 1.1和1.0的示例演示
我们提供了一个示例文件,用于比较Gemma 1.1和1.0之间的模型响应,这些响应来自Chatbot Arena Conversations dataset。你可以点击下面的链接尝试使用它: https://pair-code.github.io/llm-comparator/?results_path=https://pair-code.github.io/llm-comparator/data/example_arena.json
该工具帮助你分析Gemma 1.1何时和为什么比1.0更好或更差,以及两个模型的响应有何不同。
- 何时: 得分分布和按提示类别划分的指标面板显示,根据LLM评估方法(LLM-as-a-judge),模型A(Gemma 1.1)的响应质量被认为比模型B(Gemma 1.0)更好(蓝色区域比橙色区域大;胜率>50%),这在大多数提示类别(如人文、数学)中都成立。
- 为什么: 解释概括面板深入探讨了这些得分差异的原因。在本例中,LLM评判者主要关注细节程度。它也考虑了简洁性、参与度、结构等因素。
- 如何: 自定义函数面板可让你发现有趣的具体差异。例如,Gemma 1.1(模型A)在结构方面更好,因为它更频繁地使用项目符号列表。此外,Gemma 1.1更加简洁,而Gemma 1.0的响应中以"Sure"开头的更多。
用于创建JSON文件的Python库
这个项目在PyPI上提供了llm-comparator包,用于创建用于LLM比较器可视化的JSON文件。该包可以创建包括并行LLM评估和理由聚类在内的整个JSON文件,只需提供一组要运行的输入提示和要运行它们的模型。如果用户已经有提示和现有的一组模型输出,它也可以执行只有理由聚类步骤。你可以简单地运行一个notebook来创建一个JSON文件,并在basic_demo.ipynb查看结果。有关更多详细信息,请参见Python库README。
JSON数据格式
LLM比较器工具接受一个JSON文件并可视化其内容。该文件必须遵循下面描述的模式。
最小示例
我们假设用户有一组要测试的输入提示。对于每个提示,他们需要准备两个LLM(即模型A、模型B)的响应,以及从并行评估(如LLM-as-a-judge、AutoSxS)获得的数字分数。正分数表示A的响应比B更好;负分数表示B更好;零表示平局。我们假设分数在1.5到-1.5之间。
数据文件应按如下格式: 所有下面显示的字段都是必需的。
{ "metadata": [ "source_path": "您记录的任何字符串(如运行id)", "custom_fields_schema": [] ], "models": [ {"name": "您的第一个模型的简称"}, {"name": "您的第二个模型的简称"} ], "examples": [ { "input_text": "这是一个提示。", "tags": ["数学"], # 用于分类提示的关键词列表 "output_text_a": "第一个模型(A)对该提示的响应", "output_text_b": "另一个模型(B)对该提示的响应", "score": -1.25, # 来自评判LLM的分数 "individual_rater_scores": [], "custom_fields": {} }, { "input_text": "这是下一个提示。", ... } ] }
附加数据
您可以选择提供其他信息,在LLM比较器中进行分析。
自定义字段
如果您有关于每个提示的其他信息,它可以显示为表格中的列,并且聚合信息会在界面右侧的图表中可视化。它支持各种数据类型,例如:
number: 数字数据,可视化为直方图(例如,提示的字数,由外部API计算的安全分数)。category: 字符串形式的分类数据,可视化为柱状图(例如,提示的数据来源名称)。text: 用于长文本(在可滚动的容器中呈现)。string: 通用字符串(可用于ID键)。image_path: 用于图像URL。image_byte: 以base64编码的JPEG原始图像字节串。
该工具还支持从两个模型响应中获取值的情况。我们将这些称为per_model类型,包括:
per_model_boolean: 应用于每个响应的布尔值(例如, 是否包含项目符号列表)。per_model_number: 每个响应的数值(例如, 字数)。per_model_category: 应用于每个响应的分类字符串(例如, 文本的语气)。
这些信息可以格式化如下:
{
"metadata": {
"source_path": "...",
"custom_fields_schema": [
{"name": "prompt_word_count", "type": "number"},
{"name": "word_overlap_rate_between_a_b", "type": "number"},
{"name": "data_source", "type": "category"},
{"name": "unique_id", "type": "string"},
{"name": "is_over_max_token", "type": "per_model_boolean"},
{"name": "TF-IDF_between_prompt_and_response", "type": "per_model_number"},
{"name": "writing_style", "type": "per_model_category"},
]
},
"models": [{...}, {...}],
"examples": [
{
"input_text": "Which city should I visit in South Korea?",
"tags": ["Travel"],
"output_text_a": "You can visit Seoul, the capital of South Korea.",
"output_text_b": "You can visit Seoul, Busan, and Jeju.",
"score": 0.5,
"individual_rater_scores": [],
"custom_fields": {
"prompt_word_count": 8,
"word_overlap_rate_between_a_b": 0.61,
"data_source": "XYZ",
"unique_id": "abc000",
"is_over_max_token": [true, false],
"TF-IDF_between_prompt_and_response": [0.31, 0.15],
"writing_style": ["Verbose", "Neutral"]
}
},
{
"input_text": "How to draw bar charts using Python?",
...











