
LLM数据创建:使用大型语言模型生成高质量合成数据
在人工智能和机器学习领域,高质量的训练数据至关重要。然而,对于许多任务来说,获取大规模的人工标注数据集既耗时又昂贵。为了解决这一问题,微软研究院最近提出了一种创新的方法 - LLM数据创建框架,可以利用大型语言模型(LLM)生成高质量的合成数据。本文将深入探讨这一框架的原理、优势以及潜在应用。
LLM数据创建框架概述
LLM数据创建是一个使用大型语言模型为下游应用生成合成数据的过程。该框架的独特之处在于,它只需要一个格式示例作为输入,就能生成大量符合该格式的高质量数据。
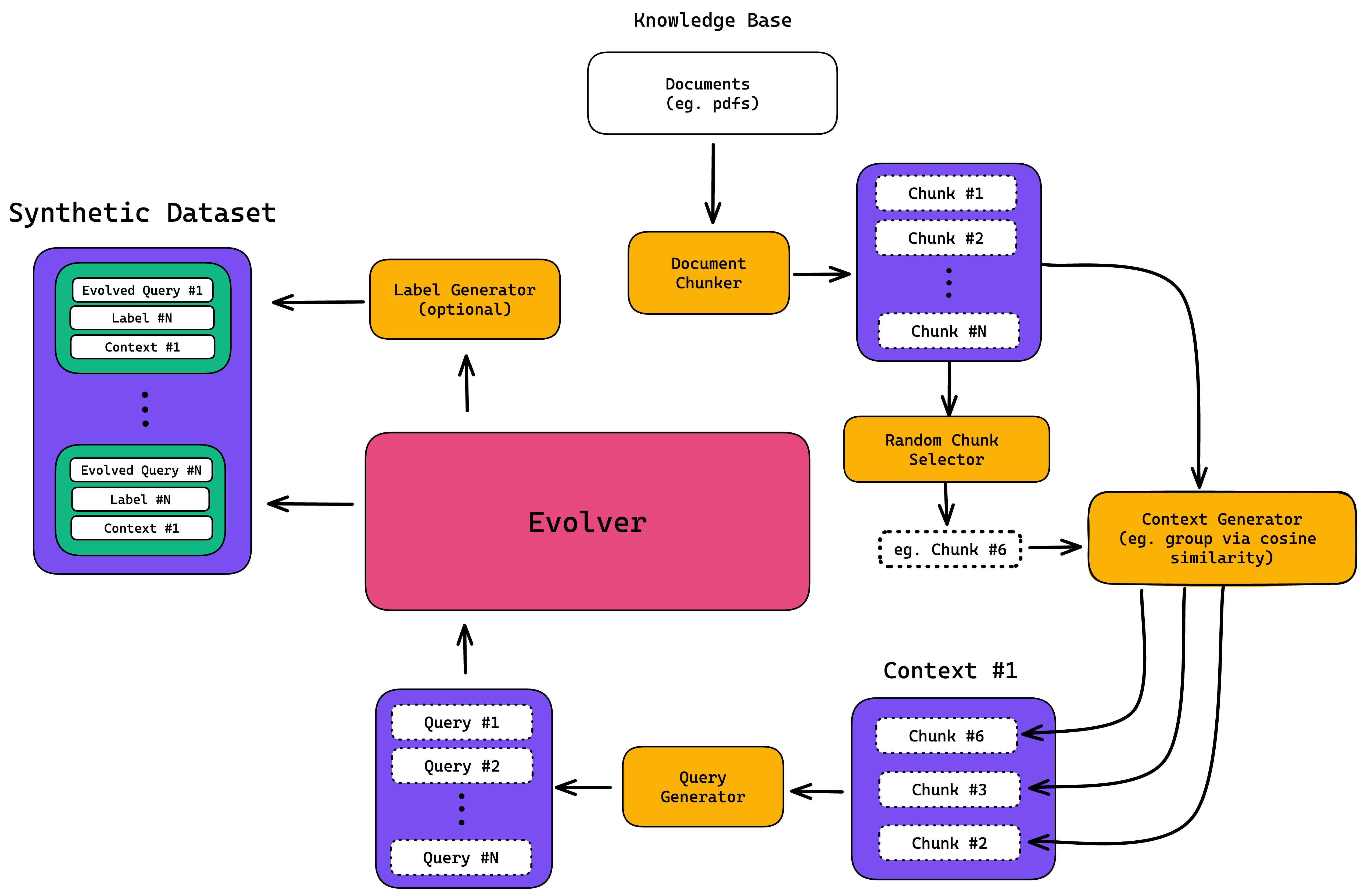
如上图所示,整个过程包括以下几个关键步骤:
- 输入一个格式示例(如多项选择题、开放式问答等)
- LLM根据示例生成更多同格式的数据
- 对生成的数据进行迭代优化
- 输出大规模的高质量合成数据集
这种方法的主要优势在于:
- 速度快:相比人工标注,可以在短时间内生成海量数据
- 成本低:无需大规模人工标注,显著降低数据获取成本
- 质量高:经过优化的LLM可以生成多样化、高质量的数据
- 灵活性强:可以根据需要定制各种格式的数据
框架实现细节
Microsoft的LLM数据创建框架主要包含以下几个关键组件:
-
数据目录结构 框架支持多种数据类型,如多项选择题(mcqa)、是非题(yesno)等。数据按类型和子类型组织在不同目录下。
-
超参数设置
可以通过设置多个超参数来控制数据生成过程,如:
- data_dir:数据目录
- data_name:具体数据集名称
- num_examples:每次迭代生成的样本数
- seed:随机种子
- setting:生成策略(naive/random/diverse/similar)
- 数据创建过程 通过运行data_creation.py脚本来执行数据生成:
python data_creation.py \
--data_dir {data_dir} \
--data_name {data_name} \
--num_examples {num_examples} \
--seed {seed} \
--setting {setting}
- 模型微调 生成数据后,可以使用这些数据来训练和评估小型任务特定模型:
./script/train.sh {data_dir} {data_name} {setting} {learning_rate} {output_directory}
评估结果
研究人员在10个公开基准数据集上评估了LLM数据创建的效果。结果表明:
-
在跨领域设置下,使用LLM创建的数据训练的小型模型表现甚至优于使用人工标注数据训练的模型。
-
在领域内任务上,LLM创建的数据也能达到与人工标注数据相当的性能。
这些结果充分证明了LLM数据创建方法的有效性和潜力。它不仅可以大幅降低数据获取成本,还能在某些情况下生成比人工标注更好的训练数据。
使用技巧与注意事项
尽管LLM数据创建方法强大,但在使用时也需要注意以下几点:
-
输入示例的选择很关键,它会影响生成数据的领域和内容。用户需要根据具体任务精心设计示例。
-
LLM的参数设置(如temperature、top_p等)会影响输出。研究中将这些参数设为1以鼓励最大创造性,但在实际应用中可能需要调整以平衡数据质量和多样性。
-
生成的数据可能存在潜在的有害、错误或偏见问题。用户应该了解这些风险,并采取相应的缓解策略,如设置安全guardrails、进行后处理过滤等。
未来展望
LLM数据创建开启了一个全新的数据获取范式。随着大型语言模型的不断进步,这种方法有望在更多领域发挥重要作用。未来的研究方向可能包括:
- 提高生成数据的质量和多样性
- 扩展到更多类型的任务和数据格式
- 探索半监督学习等结合人工标注和LLM生成的混合方法
- 研究如何更好地控制和缓解生成数据中的偏见问题
总的来说,LLM数据创建为解决数据瓶颈问题提供了一个极具前景的方向。它有潜力彻底改变机器学习领域的数据获取方式,推动AI技术在更多领域的应用与发展。
研究者们鼓励感兴趣的读者尝试使用这个开源框架,并欢迎社区贡献改进意见。随着更多人的参与,相信这项技术会变得更加成熟和强大,为AI的发展注入新的活力。


















