
LLM-Search: 革新本地文档检索的高级RAG系统
在人工智能和自然语言处理领域不断发展的今天,如何高效地从海量本地文档中检索信息并生成准确回答,成为了一个备受关注的挑战。LLM-Search应运而生,作为一款基于大型语言模型(LLM)的高级检索增强生成(RAG)系统,它为这一挑战提供了一个创新而全面的解决方案。
什么是LLM-Search?
LLM-Search是一个开源项目,旨在提供一个便捷、强大的问答系统,能够与多个本地文档集合进行交互。它的核心目标是在基础RAG系统的基础上,通过一系列创新功能来提升文档检索和问答的质量。该项目由GitHub用户snexus开发,目前已获得458颗星和57次fork,显示出其在开发者社区中的受欢迎程度。
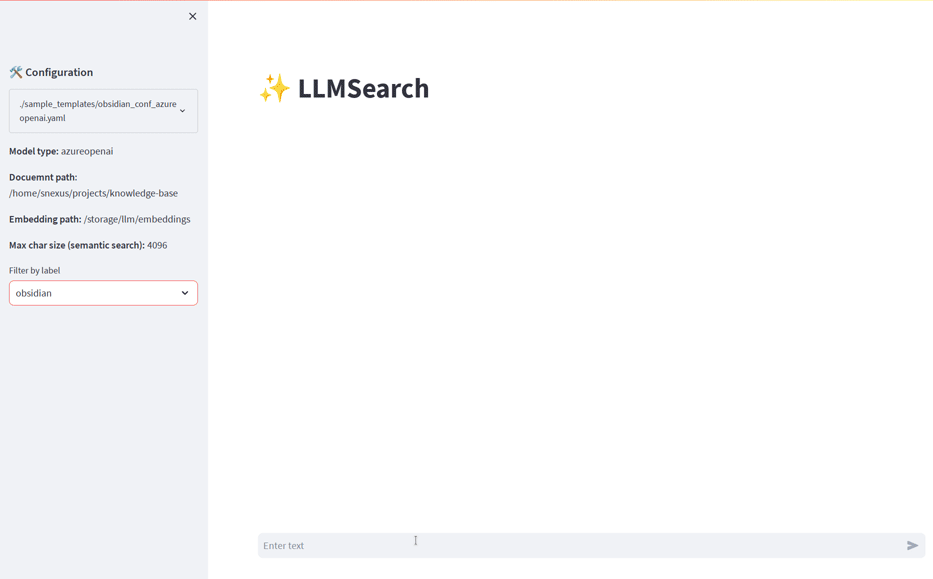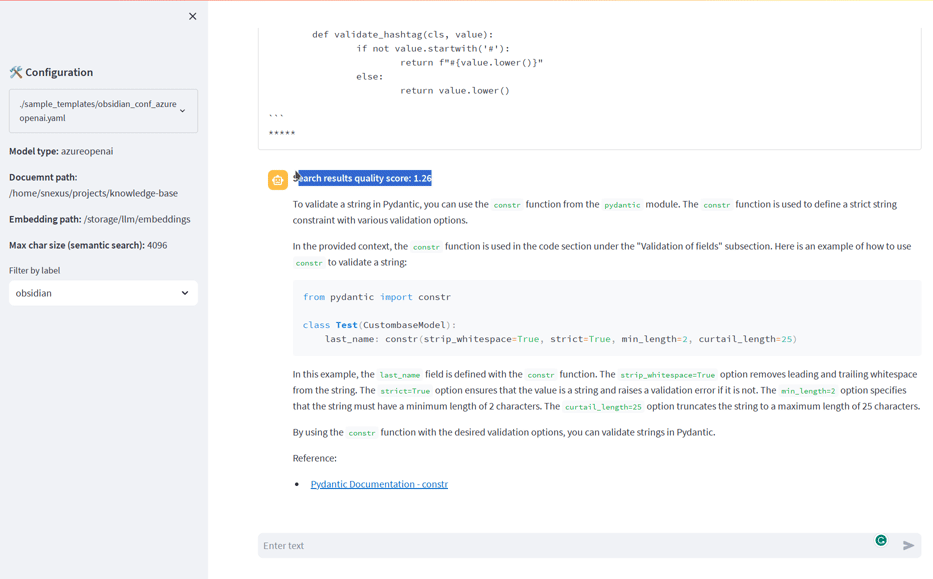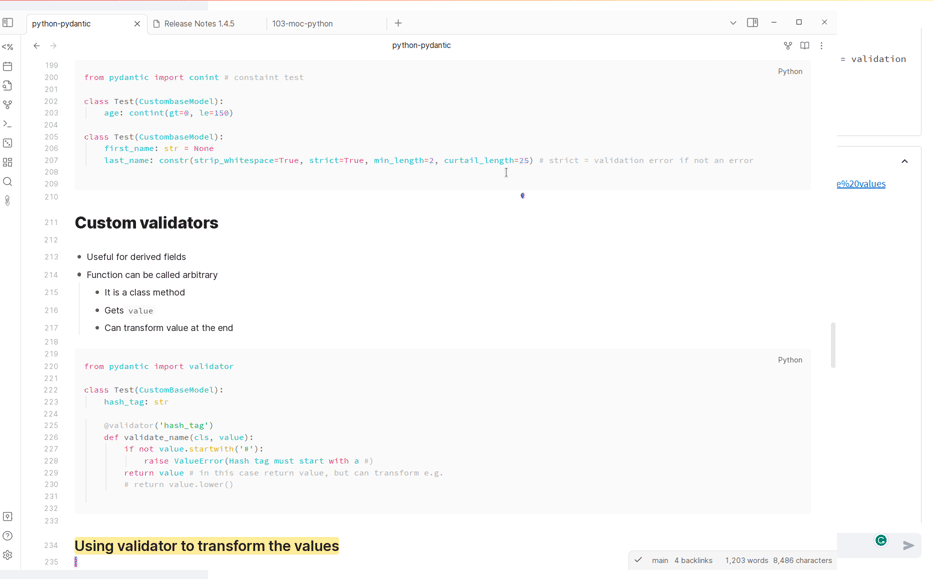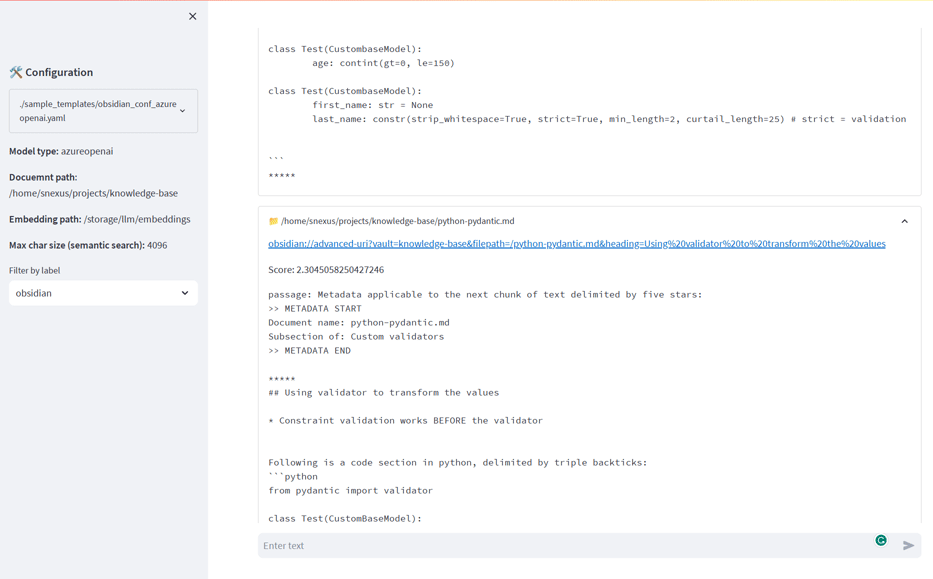
LLM-Search的主要特性
-
多格式文档支持: LLM-Search内置了对Markdown、PDF和Word文档的解析器,同时通过Unstructured预处理器支持其他常见格式。这使得系统能够处理各种类型的文档,提高了其适用性。
-
多文档集合管理: 系统支持多个文档集合,并允许用户根据集合筛选搜索结果。这一功能对于管理大量不同主题或领域的文档特别有用。
-
增量更新嵌入: LLM-Search允许增量更新文档嵌入,无需重新索引整个文档库。这大大提高了系统的效率,尤其是在处理频繁更新的大型文档集时。
-
高级嵌入和搜索技术:
- 使用ChromaDB存储密集嵌入
- 支持多种嵌入模型,如Hugging Face、Sentence-transformers和Instructor-based模型
- 使用SPLADE生成稀疏嵌入,实现混合搜索
- 支持"检索和重排"策略,提高语义搜索的准确性
-
HyDE (Hypothetical Document Embeddings): 这是一项创新功能,可以显著提升输出质量,特别是在用户难以使用领域特定语言formulate问题时。
-
多查询支持: 受RAG Fusion启发,LLM-Search可以生成原始查询的多个变体,从不同角度探索问题,提高检索的全面性。
-
聊天历史和上下文理解: 系统支持可选的聊天历史功能,能够理解问题的上下文,提供更连贯的对话体验。
-
多样化的LLM支持: LLM-Search可以与多种语言模型交互,包括OpenAI模型、HuggingFace模型、Llama cpp支持的模型等。通过LiteLLM和Ollama的OpenAI API,它还支持数百种不同的模型。
-
其他实用功能:
- 简洁的命令行和Web界面
- 文档深度链接,可直接跳转到PDF页面或Markdown文件的特定标题
- 离线数据库存储响应,便于后续分析
- 实验性API
LLM-Search的技术实现
LLM-Search的核心是其先进的文档处理和检索pipeline。首先,系统会解析不同格式的文档,将其转换为统一的格式。然后,使用选定的嵌入模型生成文档的向量表示,并存储在ChromaDB中。
当用户提出查询时,系统会执行以下步骤:
- 生成查询的向量表示
- 在向量数据库中搜索相似的文档片段
- 如果启用了HyDE,系统会生成假设性文档嵌入来增强搜索
- 使用"检索和重排"策略进一步优化搜索结果
- 将检索到的相关文档片段与原始查询一起发送给选定的LLM
- LLM生成最终的回答
整个过程中,LLM-Search还会考虑聊天历史(如果启用),以提供更加连贯和上下文相关的回答。
LLM-Search的应用场景
LLM-Search的设计使其适用于多种场景:
-
企业知识管理: 公司可以使用LLM-Search来索引和查询内部文档、报告和政策,提高信息获取效率。
-
学术研究: 研究人员可以利用该系统快速检索和分析大量学术文献。
-
客户支持: 企业可以将产品手册和常见问题解答集成到系统中,为客户提供快速、准确的自助服务。
-
法律和合规: 法律专业人士可以使用LLM-Search来检索和分析大量法律文件和判例。
-
个人知识管理: 个人用户可以用它来组织和检索自己的笔记、文档和学习材料。
使用LLM-Search的注意事项
尽管LLM-Search提供了强大的功能,但用户在使用时仍需注意以下几点:
-
数据隐私: 由于系统处理本地文档,用户应确保敏感信息得到适当保护。
-
模型选择: 不同的LLM和嵌入模型可能会影响系统的性能和准确性,用户应根据具体需求选择合适的模型。
-
资源消耗: 处理大量文档和运行复杂模型可能需要较高的计算资源,用户应考虑硬件配置。
-
结果验证: 尽管系统能提供高质量的回答,但用户仍应对重要信息进行验证。
-
持续更新: 为了保持系统的有效性,用户需要定期更新文档库和模型。
LLM-Search的未来发展
作为一个活跃的开源项目,LLM-Search有望在未来得到进一步的发展和完善。可能的发展方向包括:
- 支持更多的文档格式和语言
- 改进多模态处理能力,如图像和视频内容的检索
- 增强隐私保护和安全特性
- 优化性能,降低资源消耗
- 提供更多的自定义选项和插件系统
结语
LLM-Search代表了RAG系统的一个重要进步,它将先进的NLP技术与灵活的文档管理相结合,为用户提供了一个强大的本地文档问答解决方案。无论是企业、研究机构还是个人用户,都可以从这个创新系统中受益,提高信息检索和知识管理的效率。随着项目的不断发展和社区的贡献,我们可以期待LLM-Search在未来带来更多令人兴奋的功能和改进。
对于那些希望深入了解或贡献到LLM-Search项目的开发者,可以访问GitHub仓库获取更多信息。同时,项目的详细文档也提供了丰富的使用指南和技术细节,值得探索。
在人工智能和自然语言处理技术不断进步的今天,LLM-Search无疑为我们展示了一个充满可能性的未来,一个我们可以更智能、更高效地与海量信息交互的未来。让我们拭目以待,看看这个创新项目将如何继续推动文档检索和问答技术的边界。


















