
LLMLingua: 释放大语言模型的无限潜力
在人工智能快速发展的今天,大语言模型(LLM)如 ChatGPT 和 GPT-4 凭借其强大的泛化能力和推理能力,正在各个领域掀起一场技术革命。然而,这些模型在实际应用中也面临着一些挑战,如输入长度限制、高昂的使用成本等。为了解决这些问题,微软研究院开发了一项突破性技术 - LLMLingua。
LLMLingua 系列简介
LLMLingua 系列包括三个主要版本:LLMLingua、LongLLMLingua 和 LLMLingua-2。这些工具都致力于通过提示压缩技术来提高大语言模型的效率和性能。
-
LLMLingua: 最初版本,能够将提示压缩高达 20 倍,同时保持模型性能。
-
LongLLMLingua: 专门针对长文本场景优化,解决了 LLM 在处理长文本时的"中间遗忘"问题。
-
LLMLingua-2: 最新版本,在压缩速度上比 LLMLingua 提升了 3-6 倍,并在处理领域外数据方面表现更佳。
LLMLingua 的工作原理
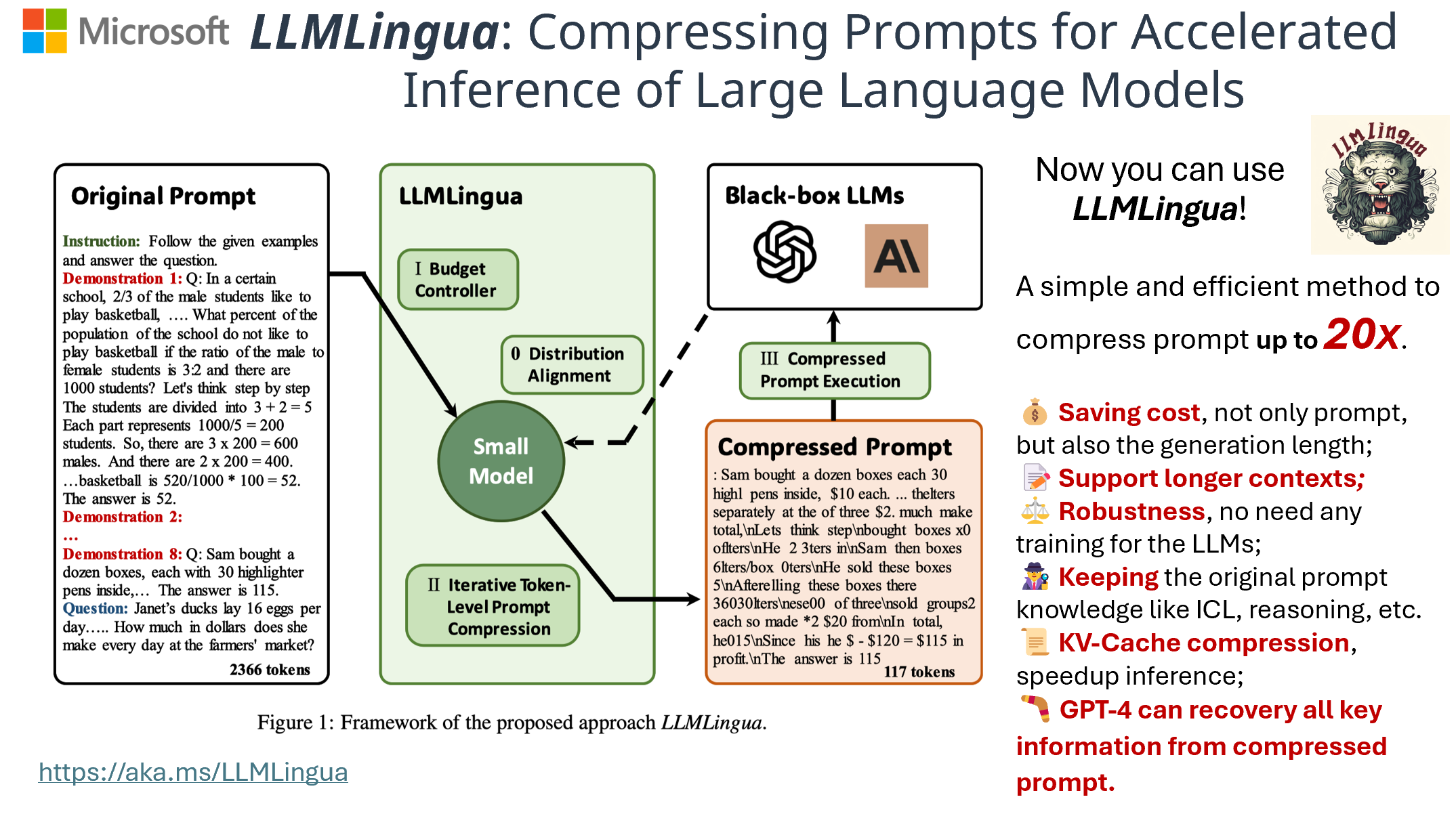
LLMLingua 的核心思想是利用一个小型但训练良好的语言模型(如 GPT2-small 或 LLaMA-7B)来识别和移除提示中的非必要信息。这种方法不仅能大幅降低输入的 token 数量,还能保留关键信息,确保大语言模型的推理性能不受影响。
LLMLingua 带来的优势
-
💰 成本节约: 通过减少输入和生成的 token 数量,显著降低了 API 调用成本。
-
📝 扩展上下文支持: 增强了对长文本的处理能力,缓解了"中间遗忘"问题。
-
⚖️ 稳健性: 无需对大语言模型进行额外训练,即插即用。
-
🕵️ 知识保留: 能够保留原始提示中的关键信息,如少样本学习(ICL)和推理过程。
-
📜 KV-Cache 压缩: 加速了推理过程,提高了整体效率。
-
🪃 全面恢复能力: GPT-4 等高级模型能够从压缩后的提示中恢复所有关键信息。
实际应用案例
LLMLingua 系列在多个实际场景中展现了其强大的效果:
- 检索增强生成(RAG): 在保持性能的同时,显著降低了 token 使用量,提高了检索效率。
- 在线会议: 能够快速压缩和处理大量会议记录,提取关键信息。
- 链式思考(CoT): 在复杂推理任务中,保留了关键的推理步骤,同时减少了冗余信息。
- 代码生成: 在保持代码质量的同时,减少了输入的 token 数量,提高了生成效率。
快速上手指南
要开始使用 LLMLingua,只需通过 pip 安装即可:
pip install llmlingua
然后,您可以轻松地使用 LLMLingua 来压缩提示:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)
对于 LongLLMLingua 和 LLMLingua-2,也有类似的简单使用方法,可以根据不同的应用场景选择合适的版本。
未来展望
LLMLingua 系列的发展为大语言模型的应用开辟了新的可能性。随着技术的不断进步,我们可以期待:
- 更高效的压缩算法,进一步提高压缩比和处理速度。
- 针对特定领域和任务的优化版本,如医疗、法律等专业领域。
- 与其他 AI 技术的深度集成,如多模态模型、自动化 AI 系统等。
LLMLingua 的出现无疑为 AI 应用开发者和研究人员提供了一个强大的工具,它不仅解决了当前大语言模型面临的一些关键挑战,还为未来 AI 技术的发展指明了方向。随着更多研究者和开发者加入到 LLMLingua 的生态系统中,我们有理由相信,这项技术将继续evolve,为 AI 领域带来更多突破性的创新。
结语
LLMLingua 系列技术的出现,标志着大语言模型应用进入了一个新的阶段。它不仅解决了实际应用中的效率和成本问题,还为未来 AI 技术的发展提供了新的思路。无论您是 AI 研究者、开发者还是企业用户,LLMLingua 都值得您深入了解和尝试。让我们共同期待 LLMLingua 为 AI 世界带来的更多可能性!









