
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文
LLMLingua系列 | 通过提示压缩有效地向大语言模型传递信息
| 项目主页 | LLMLingua | LongLLMLingua | LLMLingua-2 | LLMLingua演示 | LLMLingua-2演示 |
https://github.com/microsoft/LLMLingua/assets/30883354/eb0ea70d-6d4c-4aa7-8977-61f94bb87438
新闻
- 🌀 [24/07/03] 我们很高兴宣布发布MInference,以加速长上下文大语言模型的推理,在A100上预填充时将推理延迟减少高达10倍,同时在100万个词元提示中保持准确性!欲了解更多信息,请查看我们的论文,访问项目页面。
- 🧩 LLMLingua已集成到Prompt flow中,这是一个用于基于大语言模型的AI应用程序的流线型工具框架。
- 🦚 我们很高兴宣布发布LLMLingua-2,比LLMLingua速度提高了3-6倍!欲了解更多信息,请查看我们的论文,访问项目页面,并探索我们的演示。
- 👾 LLMLingua已集成到LangChain和LlamaIndex中,这两个是广泛使用的RAG框架。
- 🤳 演讲幻灯片可在AI Time Jan, 24中获取。
- 🖥 EMNLP'23幻灯片可在Session 5和BoF-6中获取。
- 📚 查看我们的新博客文章,讨论通过提示压缩获得的RAG益处和成本节省。在这里查看脚本示例。
- 🎈 访问我们的项目页面,了解RAG、在线会议、CoT和代码等实际应用案例。
- 👨🦯 浏览我们的'./examples'目录,获取实际应用示例,包括LLMLingua-2、RAG、在线会议、CoT、代码和使用LlamaIndex的RAG。
简介
LLMLingua利用一个紧凑的、训练良好的语言模型(如GPT2-small、LLaMA-7B)来识别和删除提示中的非必要词元。这种方法能够实现大语言模型(LLMs)的高效推理,实现高达20倍的压缩,同时性能损失最小。
- LLMLingua:压缩提示以加速大语言模型的推理(EMNLP 2023)
姜惠强、吴千慧、林靖、杨玉清和邱莉莉
LongLLMLingua缓解了LLMs中的"丢失中间信息"问题,增强了长上下文信息处理能力。它通过提示压缩降低成本并提高效率,仅使用1/4的词元就将RAG性能提高了21.4%。
- LongLLMLingua:通过提示压缩加速和增强长上下文场景中的大语言模型(ACL 2024和ICLR ME-FoMo 2024)
姜惠强、吴千慧、罗旭芳、李东升、林靖、杨玉清和邱莉莉
LLMLingua-2是一种小型但强大的提示压缩方法,通过从GPT-4进行数据蒸馏训练,用于带有BERT级编码器的词元分类,在任务无关的压缩方面表现出色。它在处理领域外数据时超越了LLMLingua,提供3-6倍更快的性能。
- LLMLingua-2:用于高效和忠实的任务无关提示压缩的数据蒸馏(ACL 2024 Findings)
潘卓石、吴千慧、姜惠强、夏梦琳、罗旭芳、张珏、林庆伟、Victor Ruhle、杨玉清、林靖、赵红、邱莉莉、张冬梅
🎥 概览
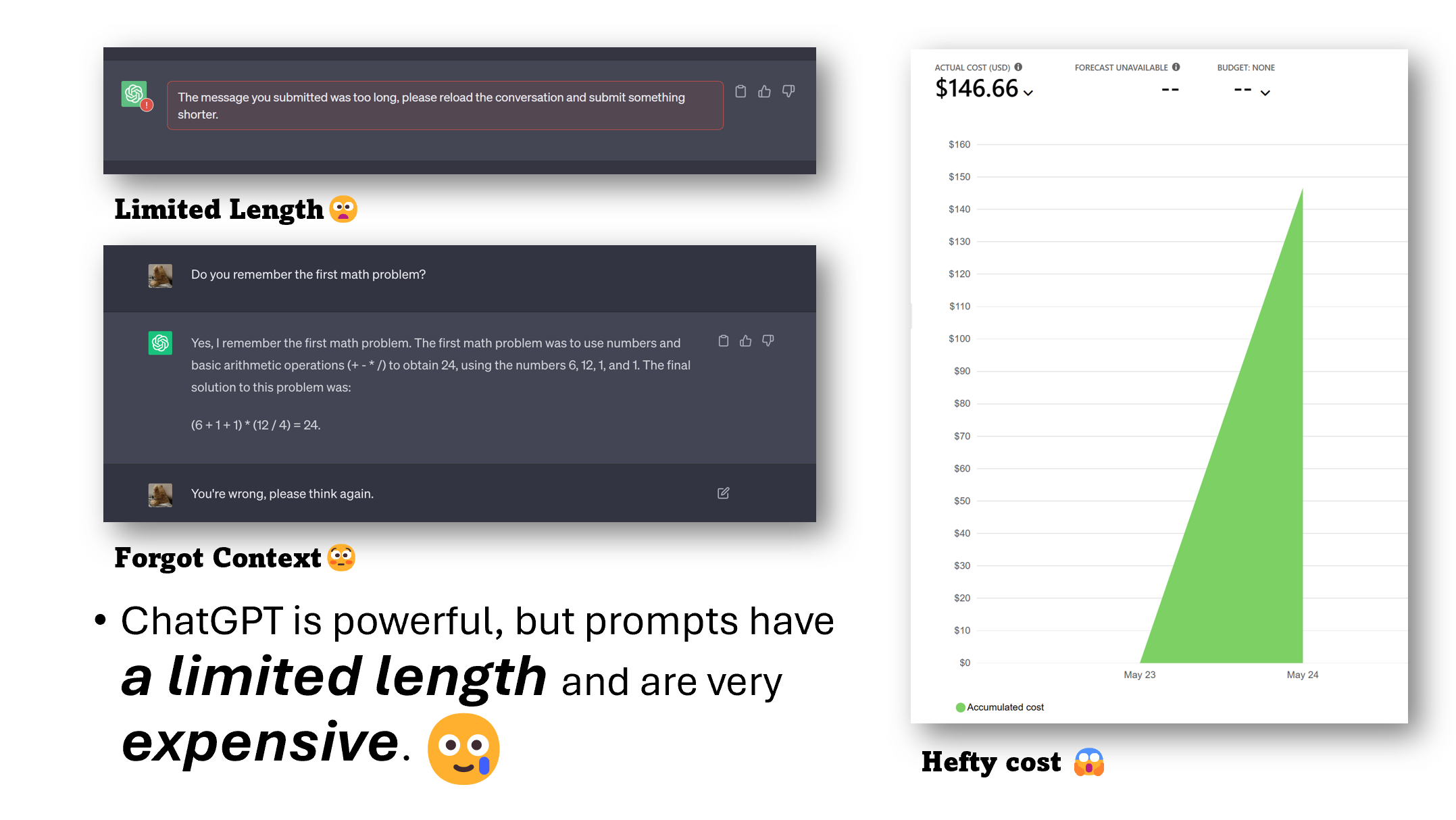
- 你是否在要求ChatGPT总结长文本时遇到过令牌限制?
- 在大量微调后ChatGPT忘记之前的指令,这让你感到沮丧吗?
- 尽管效果出色,但使用GPT3.5/4 API进行实验时却产生了高昂的费用?
虽然ChatGPT和GPT-4等大型语言模型在泛化和推理方面表现出色,但它们经常面临提示长度限制和基于提示的定价方案等挑战。
现在你可以使用LLMLingua、LongLLMLingua和LLMLingua-2了!
这些工具提供了一种高效的解决方案,可以将提示压缩高达20倍,从而提高LLM的实用性。
- 💰 节省成本:以最小的开销减少提示和生成长度。
- 📝 扩展上下文支持:增强对更长上下文的支持,缓解"迷失在中间"的问题,并提高整体性能。
- ⚖️ 稳健性:无需对LLM进行额外训练。
- 🕵️ 知识保留:保留原始提示信息,如ICL和推理。
- 📜 KV缓存压缩:加速推理过程。
- 🪃 全面恢复:GPT-4可以从压缩的提示中恢复所有关键信息。
PS: 这个演示基于alt-gpt项目。特别感谢@Livshitz的宝贵贡献。
如果您觉得这个仓库有帮助,请引用以下论文:
[引用信息省略]
🎯 快速入门
1. 安装LLMLingua:
要开始使用LLMLingua,只需使用pip安装:
pip install llmlingua
2. 使用LLMLingua系列方法进行提示压缩:
使用LLMLingua,你可以轻松压缩你的提示。以下是操作方法:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)
## 或者使用phi-2模型,
llm_lingua = PromptCompressor("microsoft/phi-2")
## 或者使用量化模型,如TheBloke/Llama-2-7b-Chat-GPTQ,只需<8GB GPU内存。
## 在此之前,你需要pip install optimum auto-gptq
llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})
要在你的场景中尝试LongLLMLingua,你可以使用
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(
prompt_list,
question=question,
rate=0.55,
# 设置LongLLMLingua的特殊参数
condition_in_question="after_condition",
reorder_context="sort",
dynamic_context_compression_ratio=0.3, # 或 0.4
condition_compare=True,
context_budget="+100",
rank_method="longllmlingua",
)
要在你的场景中尝试LLMLingua-2,你可以使用
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-xlm-roberta-large-meetingbank",
use_llmlingua2=True, # 是否使用llmlingua-2
)
compressed_prompt = llm_lingua.compress_prompt(prompt, rate=0.33, force_tokens = ['\n', '?'])
## 或使用LLMLingua-2-small模型
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",
use_llmlingua2=True, # 是否使用llmlingua-2
)
#### 3. **高级用法 - 结构化提示压缩:**
将文本分成几个部分,决定是否压缩以及压缩率。使用<llmlingua></llmlingua>标签进行上下文分段,可选择添加rate和compress参数。
```python
structured_prompt = """<llmlingua, compress=False>发言人4:</llmlingua><llmlingua, rate=0.4>谢谢。我们能处理内容的功能吗?我相信是第11、3、14、16和28项。</llmlingua><llmlingua, compress=False>
发言人0:</llmlingua><llmlingua, rate=0.4>第11项是来自议会的Price建议,建议在市政经理部门的一般基金组中增加200美元的拨款,用于向长滩公共图书馆之友提供捐助。第12项是来自议员Super Now的建议。建议在市政经理部门的特别广告和推广基金组中增加10,000美元的拨款,用于支持夏末庆祝活动。第13项是来自议员Austin的建议。建议在市政经理部门的一般基金组中增加500美元的拨款,用于向Jazz Angels提供捐款。第14项是来自议员Austin的建议。建议在市政经理部门的一般基金组中增加300美元的拨款,用于向Little Lion基金会提供捐款。第16项是来自议员Allen的建议,建议在市政经理部门的一般基金组中增加1,020美元的拨款,用于向Casa Korero、Sew Feria商业协会、长滩公共图书馆之友和Dave Van Patten提供捐助。第28项是一项建议。来自副市长Richardson和议员Muranga的建议。建议在市政经理部门的一般基金组中增加1,000美元的拨款,用于向Ron Palmer峰会篮球和学术营提供捐款。</llmlingua><llmlingua, compress=False>
发言人4:</llmlingua><llmlingua, rate=0.6>我们有一项提议和第二次发言,作为议员服务的议员Ringa和客户,他们有任何意见吗?</llmlingua>"""
compressed_prompt = llm_lingua.structured_compress_prompt(structured_prompt, instruction="", question="", rate=0.5)
print(compressed_prompt['compressed_prompt'])
# > 发言人4:我们能处理内容的功能吗?我相信是第11、、16和28项。
# 发言人0:来自议会的Price建议增加基金组中的Manager0提供a the1是议员Super Now。特别组提供夏季活动man a the Jazzels a来自议员Austin的建议。建议在市政经理部门的一般基金组中增加300美元的拨款,用于向Little Lion基金会提供捐款。第16项是来自议员Allen的建议,建议在市政经理部门的一般基金组中增加1,020美元的拨款,用于向Casa Korero、Sew Feria商业协会、长滩公共图书馆之友和Dave Van Patten提供捐助。第28项是一项建议。来自副市长Richardson和议员Muranga的建议。建议在市政经理部门的一般基金组中增加1,000美元的拨款,用于向Ron Palmer峰会篮球和学术营提供捐款。
# 发言人4:我们有一项提议和第二次发言,作为议员服务的议员Ringa和客户,他们有任何意见吗?
#### 4. **了解更多:**
要了解如何在真实场景中应用LLMLingua和LongLLMLingua,如RAG、在线会议、CoT和代码等,请参考我们的[**示例**](./examples)。如需详细指导,[**文档**](./DOCUMENT.md)提供了有关有效使用LLMLingua的广泛建议。
#### 5. **LLMLingua-2的数据收集和模型训练:**
要在您的自定义数据上训练压缩器,请参考我们的[**数据收集**](./experiments/llmlingua2/data_collection)和[**模型训练**](./experiments/llmlingua2/model_training)。
## 常见问题
欲了解更多见解和答案,请访问我们的[常见问题部分](./Transparency_FAQ.md)。
## 贡献
本项目欢迎贡献和建议。大多数贡献要求您同意贡献者许可协议(CLA),声明您有权并确实授予我们使用您贡献的权利。有关详细信息,请访问https://cla.opensource.microsoft.com。
当您提交拉取请求时,CLA机器人将自动确定您是否需要提供CLA,并适当地装饰PR(例如,状态检查、评论)。只需按照机器人提供的说明操作即可。您只需在所有使用我们CLA的仓库中执行一次此操作。
本项目已采用[Microsoft开源行为准则](https://opensource.microsoft.com/codeofconduct/)。
有关更多信息,请参阅[行为准则常见问题](https://opensource.microsoft.com/codeofconduct/faq/)或
联系[opencode@microsoft.com](mailto:opencode@microsoft.com)获取任何其他问题或意见。
## 商标
本项目可能包含项目、产品或服务的商标或标志。Microsoft商标或标志的授权使用必须遵循
[Microsoft的商标和品牌指南](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general)。
在修改后的版本中使用Microsoft商标或标志不得引起混淆或暗示Microsoft赞助。
任何第三方商标或标志的使用均受这些第三方的政策约束。











