
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

MInference: 长上下文大语言模型的百万级令牌提示推理
https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-7123c81d6b19
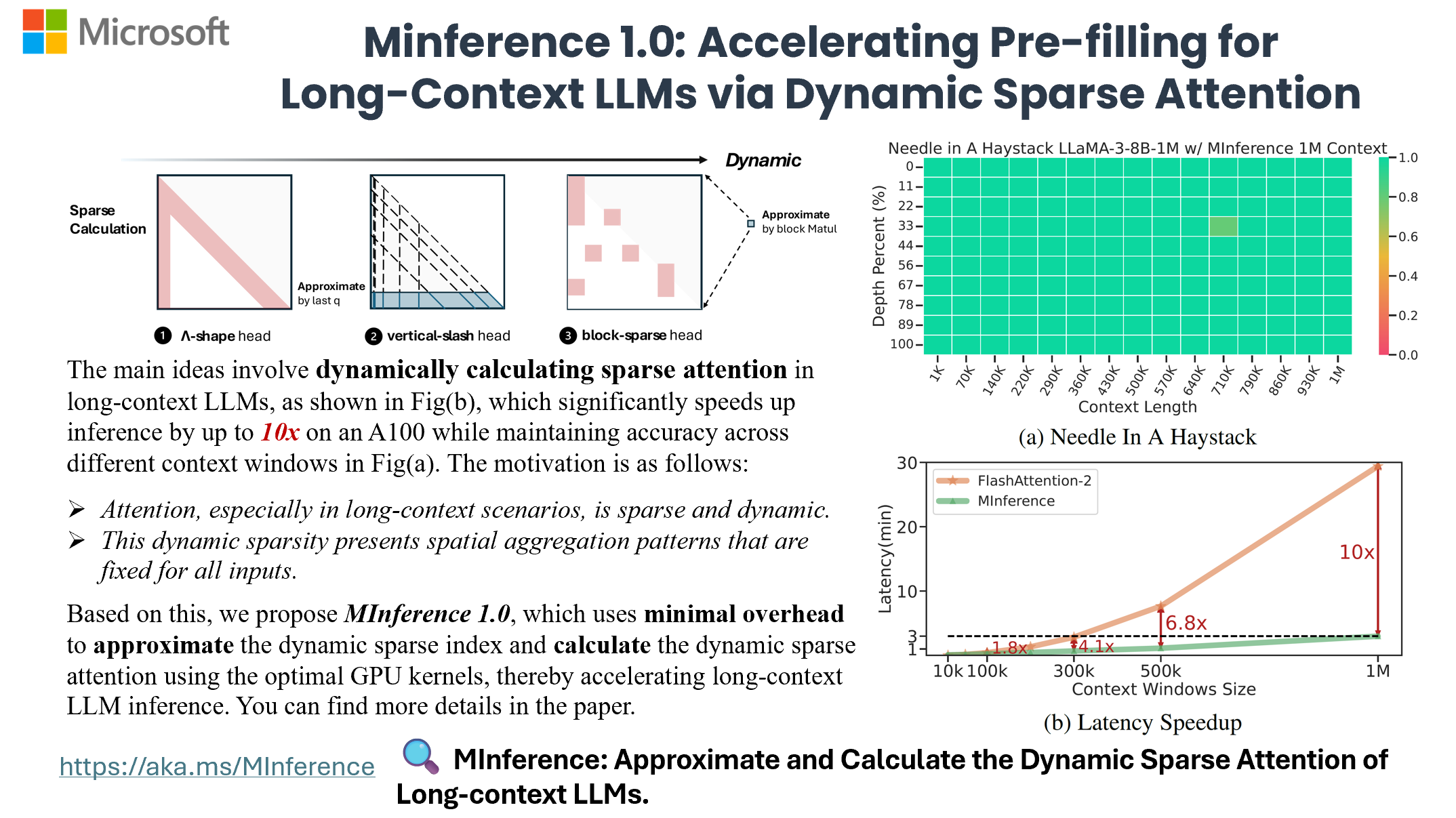
现在,您可以使用单个A100处理100万上下文的速度提高10倍,同时使用像LLaMA-3-8B-1M、GLM-4-1M这样的长上下文大语言模型,甚至精度更高,立即尝试MInference 1.0吧!
新闻
- 🥤 [24/07/24] MInference现已支持meta-llama/Meta-Llama-3.1-8B-Instruct。
- 🪗 [24/07/07] 感谢@AK的赞助。您现在可以在HF演示中使用ZeroGPU在线体验MInference。
- 📃 [24/07/03] 由于arXiv的问题,PDF目前无法在那里获取。您可以在此链接找到论文。
- 🧩 [24/07/03] 我们将在ICML'24的_微软展台和ES-FoMo_上展示MInference 1.0。维也纳见!
简介
MInference 1.0利用大语言模型注意力机制的动态稀疏性(具有一些静态模式)来加速长上下文大语言模型的预填充。它首先离线确定每个注意力头属于哪种稀疏模式,然后在线近似稀疏索引,并使用最优的自定义内核动态计算注意力。这种方法在A100上实现了预填充速度提升多达10倍,同时保持精度。
- MInference 1.0:通过动态稀疏注意力加速长上下文大语言模型的预填充(审稿中,ES-FoMo @ ICML'24)
Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
🎥 概览
🎯 快速开始
要求
- Torch
- FlashAttention-2(可选)
- Triton == 2.1.0
要开始使用MInference,只需使用pip安装:
pip install minference
支持的模型
通用MInference 支持任何解码大语言模型,包括LLaMA风格的模型和Phi模型。 我们已经适配了市场上几乎所有可用的开源长上下文大语言模型。 如果您的模型不在支持列表中,请随时在问题中告诉我们,或者您可以按照指南手动生成稀疏头配置。
您可以通过运行以下命令获取支持的大语言模型的完整列表:
from minference import get_support_models
get_support_models()
目前,我们支持以下大语言模型:
- LLaMA-3.1: meta-llama/Meta-Llama-3.1-8B-Instruct
- LLaMA-3: gradientai/Llama-3-8B-Instruct-262k, gradientai/Llama-3-8B-Instruct-Gradient-1048k, gradientai/Llama-3-8B-Instruct-Gradient-4194k, gradientai/Llama-3-70B-Instruct-Gradient-262k, gradientai/Llama-3-70B-Instruct-Gradient-1048k
- GLM-4: THUDM/glm-4-9b-chat-1m
- Yi: 01-ai/Yi-9B-200K
- Phi-3: microsoft/Phi-3-mini-128k-instruct
- Qwen2: Qwen/Qwen2-7B-Instruct
如何使用MInference
对于HF,
from transformers import pipeline
+from minference import MInference
pipe = pipeline("text-generation", model=model_name, torch_dtype="auto", device_map="auto")
# 添加MInference模块,
# 如果使用本地路径,请在初始化MInference时使用HF的model_name。
+minference_patch = MInference("minference", model_name)
+pipe.model = minference_patch(pipe.model)
pipe(prompt, max_length=10)
对于vLLM,
目前,请使用vllm>=0.4.1
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, max_num_seqs=1, enforce_eager=True, max_model_len=128000)
# 添加MInference模块,
# 如果使用本地路径,请在初始化MInference时使用HF的model_name。
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)
仅使用内核,
from minference import vertical_slash_sparse_attention, block_sparse_attention, streaming_forward
attn_output = vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
attn_output = block_sparse_attention(q, k, v, topk)
attn_output = streaming_forward(q, k, v, init_num, local_window_num)
对于本地gradio演示

git clone https://huggingface.co/spaces/microsoft/MInference
cd MInference
pip install -r requirments.txt
pip install flash_attn
python app.py
更多详情,请参考我们的示例和实验。您可以在这篇论文和GitHub上找到更多关于动态编译器PIT的信息。
常见问题
如需更多见解和答案,请访问我们的常见问题部分。
问题1:如何有效评估动态稀疏注意力对长上下文大语言模型能力的影响? 为了评估像LLaMA-3-8B-Instruct-1M和GLM-4-9B-1M这样的长上下文LLM的能力,我们测试了:1) 使用RULER测试上下文窗口,2) 使用InfiniteBench测试一般任务,3) 使用Needle in a Haystack测试检索任务,以及4) 使用PG-19测试语言模型预测。
我们发现传统方法在检索任务中表现不佳,难度级别如下:KV检索 > Needle in a Haystack > 数字检索 > 密码检索。主要挑战在于针与干草堆之间的语义差异。当这种差异较大时,传统方法表现更好,如在密码任务中。KV检索需要更高的检索能力,因为任何键都可能是目标,而多针任务更加复杂。
我们将在未来版本中继续更新更多模型和数据集的结果。
问题2:这种动态稀疏注意力模式是否只存在于未完全训练的长上下文LLM中?
首先,注意力本质上是动态稀疏的,这是该机制固有的特征。我们选择了最先进的长上下文LLM,GLM-4-9B-1M和LLaMA-3-8B-Instruct-1M,它们的有效上下文窗口分别为64K和16K。使用MInference,这些可以分别扩展到64K和32K。我们将继续调整我们的方法以适应其他先进的长上下文LLM并更新结果,同时探索这种动态稀疏注意力模式的理论基础。
问题3:这种动态稀疏注意力模式是否只存在于自回归语言模型或基于RoPE的LLM中?
类似的垂直和斜线稀疏模式已在BERT[1]和多模态LLM[2]中被发现。我们对T5注意力模式的分析(如图所示)揭示了这些模式在不同头部中持续存在,即使在双向注意力中也是如此。 [1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021. [2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.
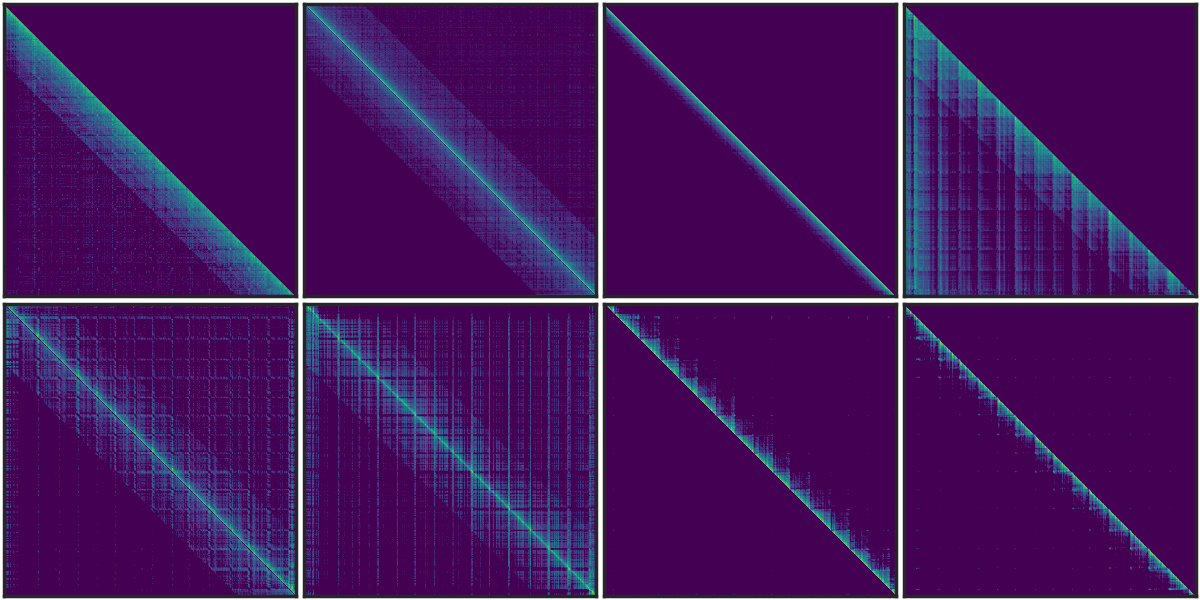
图1. T5编码器中的稀疏模式。
问题4:MInference、SSM、线性注意力和稀疏注意力之间的关系是什么?
这四种方法(MInference、SSM、线性注意力和稀疏注意力)都有效地优化了Transformer中的注意力复杂度,但各自以不同方式引入了归纳偏置。后三种方法需要从头开始训练。最近的工作如Mamba-2和统一隐式注意力表示将SSM和线性注意力统一为静态稀疏注意力,其中Mamba-2本身就是一种分块稀疏方法。虽然这些方法由于注意力中的稀疏冗余而显示出潜力,但静态稀疏注意力可能难以处理复杂任务中的动态语义关联。相比之下,动态稀疏注意力更适合管理这些关系。
引用
如果您发现MInference对您的项目和研究有用或相关,请引用我们的论文:
@article{jiang2024minference,
title={MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention},
author={Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili},
journal={arXiv preprint arXiv:2407.02490},
year={2024}
}
贡献
本项目欢迎贡献和建议。大多数贡献需要您同意贡献者许可协议(CLA),声明您有权并实际授予我们使用您贡献的权利。有关详细信息,请访问https://cla.opensource.microsoft.com。
当您提交拉取请求时,CLA机器人将自动确定您是否需要提供CLA,并适当地修饰PR(例如,状态检查、评论)。只需按照机器人提供的说明操作即可。您只需在所有使用我们CLA的仓库中执行一次此操作。
本项目已采用Microsoft开源行为准则。有关更多信息,请参阅行为准则常见问题解答或联系opencode@microsoft.com获取任何其他问题或意见。
商标
本项目可能包含项目、产品或服务的商标或标志。Microsoft商标或标志的授权使用必须遵循Microsoft的商标和品牌指南。在本项目的修改版本中使用Microsoft商标或标志不得引起混淆或暗示Microsoft赞助。任何第三方商标或标志的使用均受这些第三方的政策约束。











