
LOMO:突破内存瓶颈的大模型优化利器
在人工智能快速发展的今天,大语言模型(LLM)已成为自然语言处理领域的核心技术。然而,动辄数十亿甚至数千亿参数的模型规模,给模型训练和微调带来了巨大的计算和内存挑战。如何在有限的硬件资源下高效地训练和微调大模型,成为了学术界和工业界共同关注的重要问题。
近日,来自复旦大学的研究团队提出了一种名为LOMO(LOw-Memory Optimization)的创新优化器,为解决这一难题提供了新的思路。LOMO通过巧妙的算法设计,显著降低了模型训练的内存需求,使得在普通的消费级GPU上也能实现大模型的全参数微调。这一成果不仅有助于降低大模型应用的门槛,也为未来更大规模模型的训练提供了可能。
LOMO的核心思想:融合计算与更新
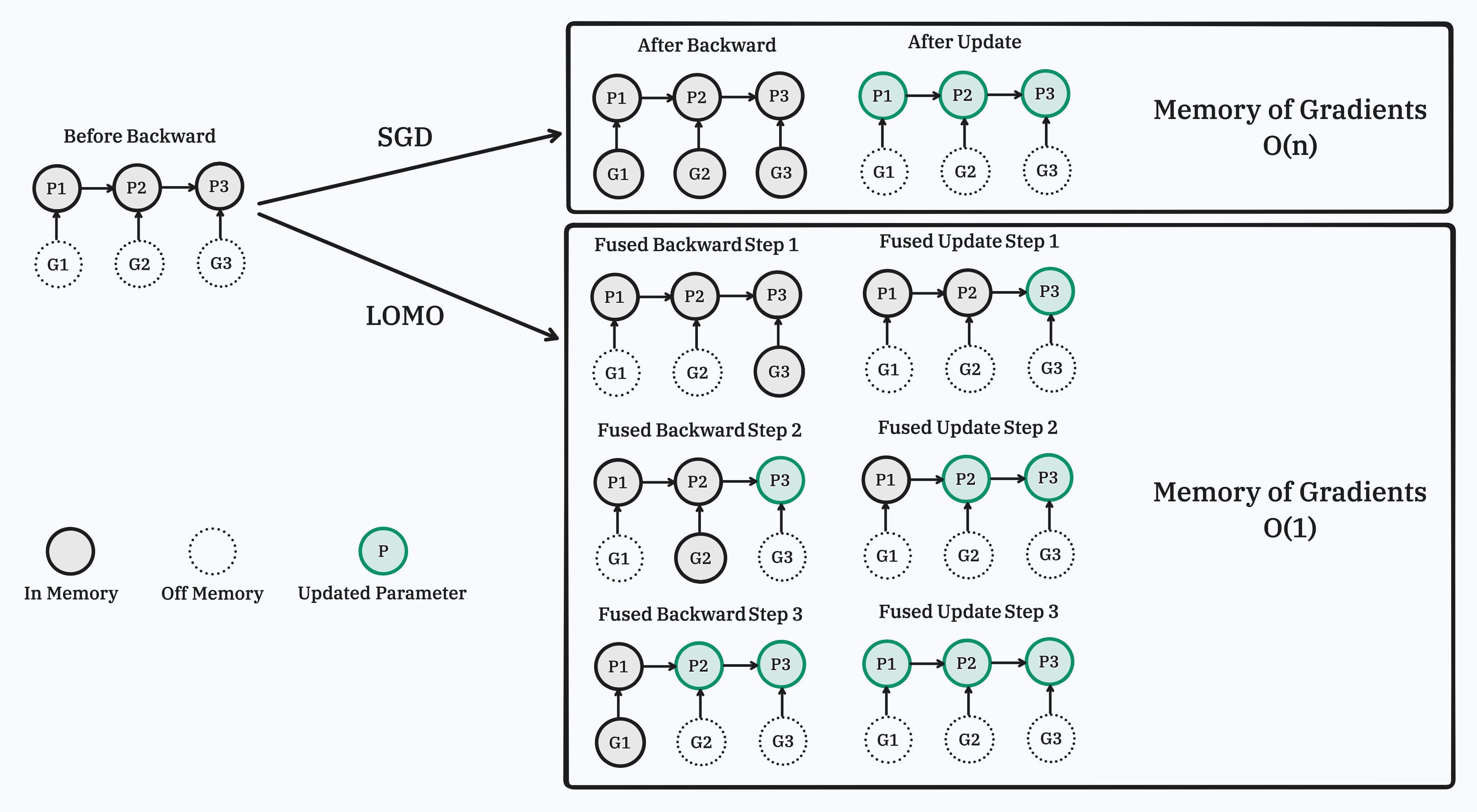
传统的深度学习优化器(如Adam)通常将梯度计算和参数更新分为两个独立的步骤。这种方式虽然直观,但在处理大模型时会占用大量内存来存储中间结果。LOMO的核心创新在于将这两个步骤巧妙地融合在一起,从而大幅减少内存占用。
具体来说,LOMO利用PyTorch的反向传播钩子(backward hook)机制,在计算每个参数梯度的同时立即进行参数更新,然后立即释放梯度内存。这种"边计算边更新"的策略,避免了存储大量中间梯度值,从而显著降低了内存需求。
LOMO的惊人效果:让普通GPU也能驾驭大模型
LOMO的效果令人印象深刻。研究表明,使用LOMO优化器,可以在单张RTX 3090显卡(24GB显存)上实现7B参数模型的全参数微调,或在8张RTX 3090组成的单机系统上微调65B参数的超大模型。这一成果大大降低了大模型应用的硬件门槛,为更多研究者和开发者提供了接触和使用大模型的机会。
AdaLomo:自适应学习率的进阶版本
在LOMO的基础上,研究团队进一步提出了AdaLomo(Adaptive LOMO)优化器。AdaLomo在保持低内存占用的同时,引入了自适应学习率机制,使得每个参数都能获得更合适的更新步长。实验表明,AdaLomo在指令微调和预训练任务上都能达到与AdamW相当的性能,同时保持较低的内存占用。

开源共享,推动技术发展
为了推动相关技术的发展和应用,研究团队将LOMO和AdaLomo的代码开源在GitHub上(https://github.com/OpenLMLab/LOMO)。同时,他们还将这些优化器集成到了多个流行的深度学习框架中:
- Hugging Face的
transformers库 - Hugging Face的
accelerate库 CoLLiE库(用于高效协作训练大语言模型)
此外,团队还发布了PyPI包lomo-optim,方便用户直接通过pip安装使用。这些举措大大降低了LOMO技术的使用门槛,使更多研究者和开发者能够便捷地应用这一创新优化器。
LOMO的工作原理深入解析
LOMO的实现依赖于PyTorch的反向传播机制。在PyTorch中,模型的反向传播是通过构建计算图,然后从输出向输入逐步计算梯度来完成的。LOMO通过为每个参数注册自定义的钩子函数,在梯度计算完成后立即进行参数更新。
具体来说,当某个参数的梯度计算完成时(在写入.grad属性之前),其对应的钩子函数会被调用。这个钩子函数会扫描所有参数,如果某个参数的.grad属性不为空,就立即进行参数更新,然后清空并释放.grad属性。
需要注意的是,由于最后一个参数的钩子函数被调用时,其.gradle属性还未设置,所以LOMO会在最后额外进行一次扫描,以更新最后一个参数。
这种设计巧妙地利用了PyTorch的内部机制,在不影响模型训练效果的前提下,最大限度地减少了内存占用。
LOMO和AdaLomo的实际应用
LOMO和AdaLomo不仅仅是理论上的创新,它们在实际应用中也展现出了强大的威力。以下是一些潜在的应用场景:
-
个人研究者和小型团队: 利用LOMO,即使只有有限的计算资源,也能进行大模型的研究和实验。这大大降低了入门门槛,使更多人能参与到大模型研究中来。
-
企业定制化: 对于需要对大模型进行定制化微调的企业,LOMO可以显著降低硬件成本,加快迭代速度。
-
边缘设备部署: AdaLomo的低内存特性使得在一些内存受限的边缘设备上也能运行相对较大的模型,为AI在物联网等领域的应用提供了可能。
-
在线学习: LOMO的即时更新特性也为大模型的在线学习提供了新的思路,有助于模型在实际应用中不断学习和改进。
未来展望
LOMO和AdaLomo的出现无疑为大模型训练和应用领域带来了新的机遇。展望未来,这项技术还有很大的发展空间:
-
进一步优化: 研究团队可能会继续改进算法,以在更低的内存占用下实现更好的性能。
-
适配更多框架: 除了已经支持的框架外,未来可能会看到LOMO被集成到更多主流深度学习框架中。
-
特定任务优化: 针对不同类型的NLP任务,可能会出现LOMO的特定变体,以获得更好的任务适应性。
-
硬件协同优化: 结合特定硬件的特性,LOMO可能会有更多针对性的优化版本,进一步提升性能。
-
跨模态应用: 虽然LOMO最初是为NLP任务设计的,但其低内存优化思想可能会被扩展到计算机视觉、多模态学习等其他AI领域。
结语
LOMO和AdaLomo的出现,为大模型训练和应用领域带来了一股清新的风。它们不仅解决了实际的技术难题,更为整个AI社区带来了新的可能性。随着这项技术的不断发展和应用,我们有理由期待看到更多创新性的大模型应用出现,推动人工智能技术向更广阔的领域扩展。
对于研究者、开发者和企业来说,现在正是深入了解和尝试LOMO技术的好时机。无论是通过直接使用开源代码,还是集成到现有项目中,LOMO都为大模型的应用提供了一个极具吸引力的选择。在未来,我们期待看到更多基于LOMO的创新应用,共同推动AI技术的进步。









