
 Github
Github Huggingface
Huggingface 论文
论文这是Full Parameter Fine-Tuning for Large Language Models with Limited Resources和AdaLomo: Low-memory Optimization with Adaptive Learning Rate的实现。
新闻
- LOMO和AdaLomo已集成到
transformers和accelerate中。 - PyPI包
lomo-optim已发布。 - LOMO和AdaLomo已集成到
CoLLiE库中,该库支持以高效方式协作训练大型语言模型。
使用方法
你可以使用pip从PyPI安装lomo-optim。
pip install lomo-optim
然后,导入Lomo或AdaLomo。
from lomo_optim import Lomo
from lomo_optim import AdaLomo
Lomo和AdaLomo的使用方法类似但不完全相同于PyTorch的优化器
(示例)。
我们建议使用不带gradnorm的AdaLomo以获得更好的性能和更高的吞吐量。
LOMO: 低内存优化
在这项工作中,我们提出了一种新的优化器,LOw-Memory Optimization (LOMO),它将梯度计算和参数更新融合在一个步骤中以减少内存使用。 我们的方法使得在单个RTX 3090上可以对7B模型进行全参数微调,或在具有8个RTX 3090(每个24GB内存)的单台机器上对65B模型进行全参数微调。
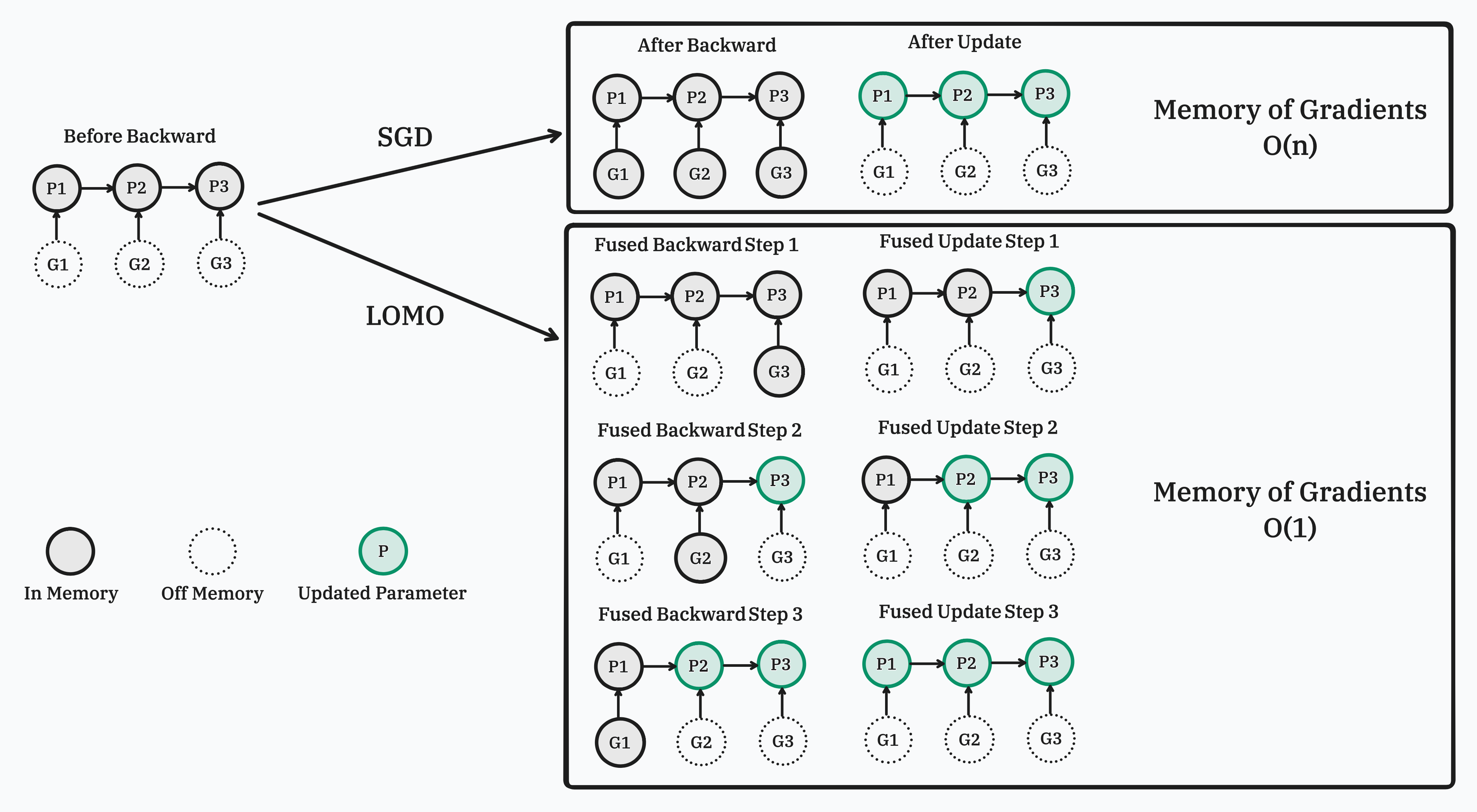
实现
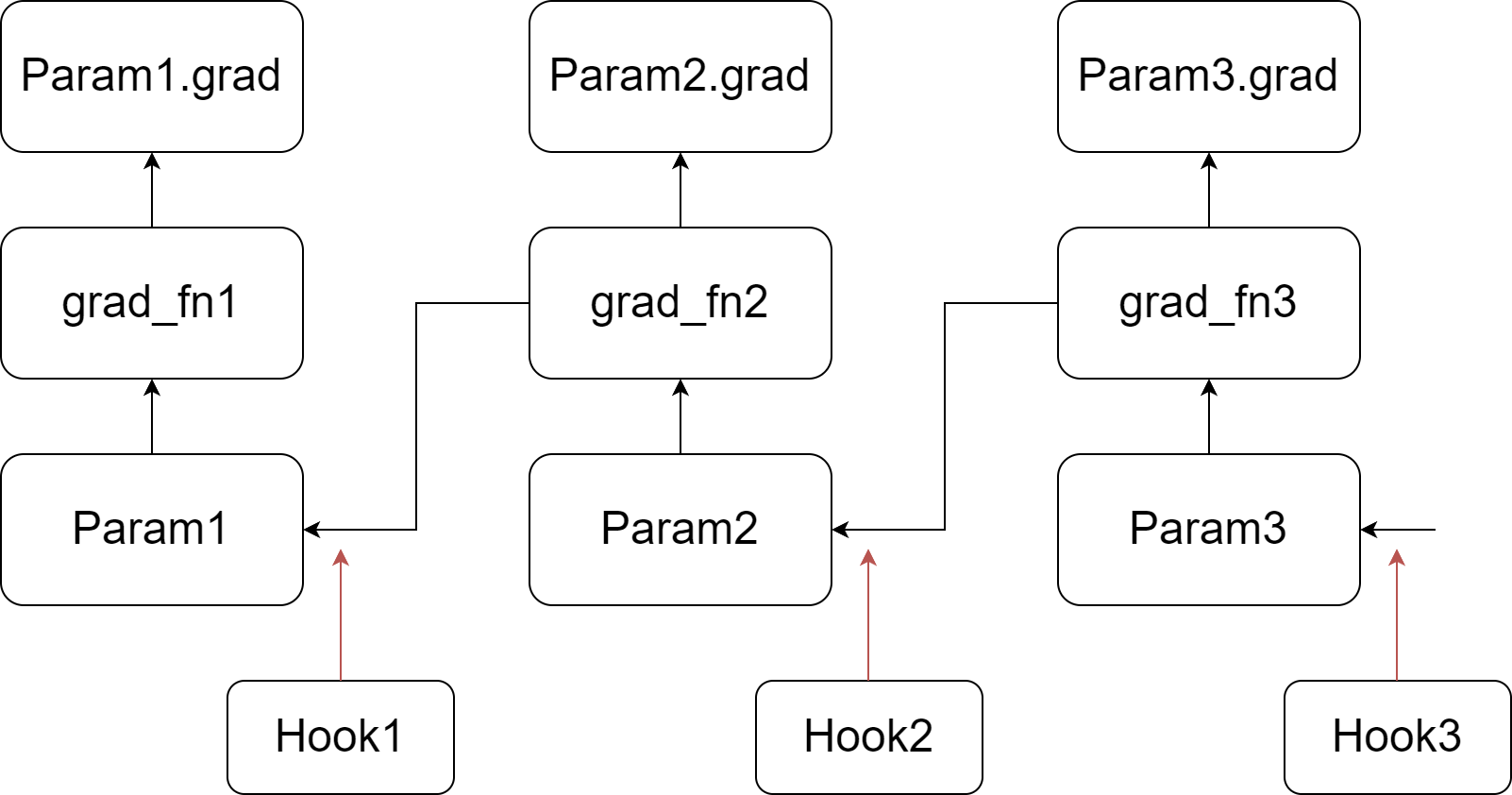 我们的实现依赖于在PyTorch的反向传播中注入钩子函数。如图所示,我们为每个参数注册一个自定义的钩子函数。当计算参数的梯度时(在将其写入.grad属性之前),会调用其对应的钩子函数。有关钩子函数和自动求导图的反向传播的更多信息,请参阅PyTorch文档。总之,在反向传播过程中,我们遍历张量及其grad_fn,将梯度写入.grad属性,然后传递到下一个张量。
我们的实现依赖于在PyTorch的反向传播中注入钩子函数。如图所示,我们为每个参数注册一个自定义的钩子函数。当计算参数的梯度时(在将其写入.grad属性之前),会调用其对应的钩子函数。有关钩子函数和自动求导图的反向传播的更多信息,请参阅PyTorch文档。总之,在反向传播过程中,我们遍历张量及其grad_fn,将梯度写入.grad属性,然后传递到下一个张量。
我们的自定义钩子函数扫描所有参数,如果参数的.grad属性不为空,则更新该参数,然后清除并释放.grad属性。由于参数的钩子函数在其.grad属性设置之前被调用,因此当调用最后一个钩子函数时,自动求导图中最后一个参数的.grad属性尚未准备就绪。因此,我们执行额外的扫描以更新最后一个参数。
LOMO的代码在lomo文件夹中。
AdaLomo: 具有自适应学习率的低内存优化
在这项工作中,我们研究了LOMO和Adam优化技术之间的区别,并引入了AdaLomo,它为每个参数提供自适应学习率,并使用分组更新归一化,同时保持内存效率。 AdaLomo在指令微调和进一步预训练中都达到了与AdamW相当的结果,同时具有更小的内存占用。

AdaLomo的代码在adalomo文件夹中。
引用
@article{lv2023full,
title={Full Parameter Fine-tuning for Large Language Models with Limited Resources},
author={Lv, Kai and Yang, Yuqing and Liu, Tengxiao and Gao, Qinghui and Guo, Qipeng and Qiu, Xipeng},
journal={arXiv preprint arXiv:2306.09782},
year={2023}
}
@article{lv2023adalomo,
title={AdaLomo: Low-memory Optimization with Adaptive Learning Rate},
author={Lv, Kai and Yan, Hang and Guo, Qipeng and Lv, Haijun and Qiu, Xipeng},
journal={arXiv preprint arXiv:2310.10195},
year={2023}
}











