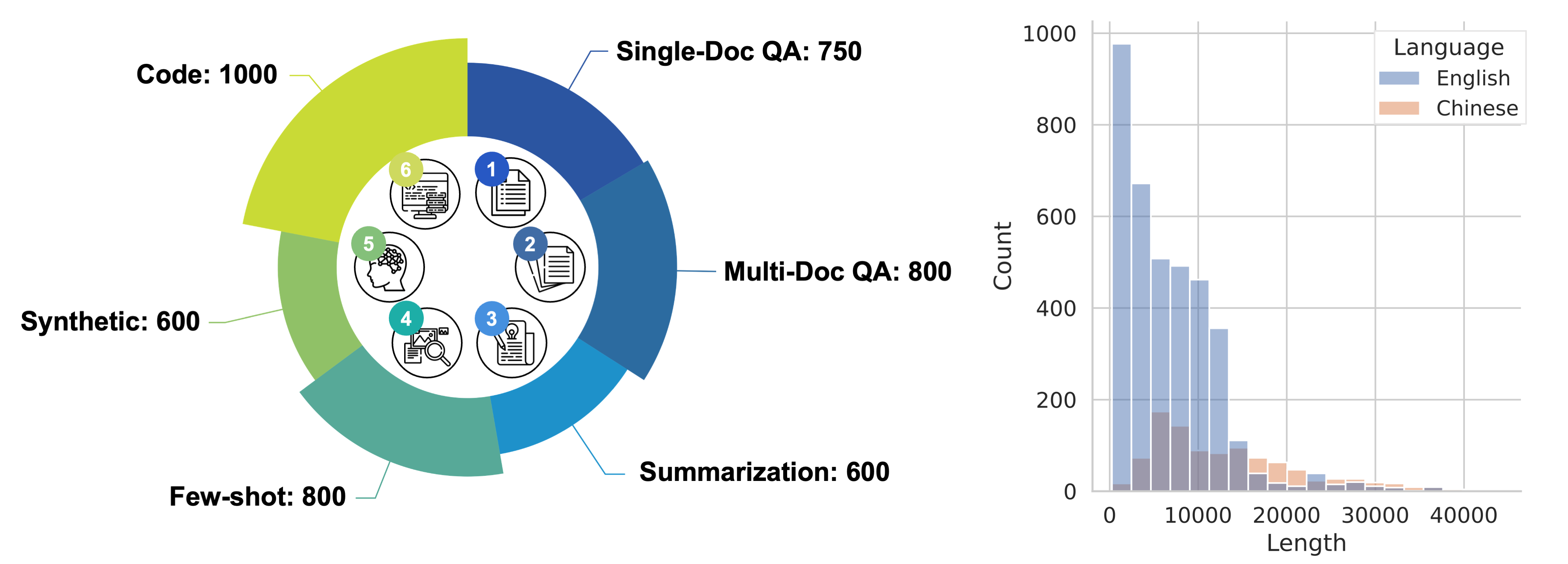
LongBench简介
LongBench是由清华大学开发的首个双语多任务长文本理解基准测试,旨在全面评估大型语言模型的长文本理解能力。它具有以下主要特点:
- 包含中英双语任务,能够全面评估模型的多语言长文本处理能力
- 涵盖6大类21个不同任务,包括单文档QA、多文档QA、摘要、少样本学习、合成任务和代码补全等
- 大多数任务的平均长度在5k到15k之间,共4,750个测试样本
- 采用全自动评估方法,降低评估成本
主要学习资源
-
GitHub仓库: https://github.com/THUDM/LongBench 包含完整的代码、数据和文档
-
论文: LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding 详细介绍了LongBench的设计和实验结果
-
Hugging Face数据集: https://huggingface.co/datasets/THUDM/LongBench 可直接下载使用LongBench数据集
-
任务详细说明: task.md 包含各项任务的统计信息和构建方法
如何使用LongBench
- 安装依赖:
pip install -r requirements.txt
- 下载数据:
from datasets import load_dataset
datasets = ["narrativeqa", "qasper", "multifieldqa_en", "multifieldqa_zh", "hotpotqa", "2wikimqa", "musique",
"dureader", "gov_report", "qmsum", "multi_news", "vcsum", "trec", "triviaqa", "samsum", "lsht",
"passage_count", "passage_retrieval_en", "passage_retrieval_zh", "lcc", "repobench-p"]
for dataset in datasets:
data = load_dataset('THUDM/LongBench', dataset, split='test')
- 运行评估:
CUDA_VISIBLE_DEVICES=0 python pred.py --model your_model_name
python eval.py --model your_model_name
- 查看结果:
评估结果将保存在
result.json文件中。
主要实验结果
LongBench对8个LLM模型进行了评估,主要发现包括:
- 商业模型(如GPT-3.5-Turbo-16k)总体表现最好,但在更长文本上仍有困难
- 扩展位置嵌入和对更长序列进行微调可以显著提升长文本理解能力
- 检索等上下文压缩技术对弱模型有帮助,但仍落后于强模型
更多详细结果请参考GitHub README。
LongBench为评估和改进大型语言模型的长文本处理能力提供了重要基准。研究人员可以利用它来开发更强大的长文本理解模型,推动NLP领域的进步。