LoraHub: 开启大语言模型微调的新篇章
在人工智能和自然语言处理领域,大语言模型(LLMs)的微调一直是一个热门而又具有挑战性的话题。随着模型规模的不断扩大,如何在保持模型性能的同时实现高效的任务适应成为了研究者们关注的焦点。在这样的背景下,来自新加坡国立大学和字节跳动AI Lab的研究团队提出了一个名为LoraHub的创新框架,为大语言模型的跨任务泛化能力开辟了一条全新的道路。
LoraHub的核心理念
LoraHub的核心思想是通过动态组合多个预先训练好的LoRA(Low-Rank Adaptation)模块,来实现对新任务的快速适应。LoRA是一种广受欢迎的参数高效微调技术,它通过在原始模型中插入可训练的低秩矩阵来实现模型的任务特定适应。LoraHub进一步拓展了这一理念,提出了一种可以组合多个LoRA模块的方法,从而在不增加额外参数和训练的情况下,实现对未见任务的高效泛化。

LoraHub的工作流程
LoraHub的工作流程主要包含两个阶段:组合阶段(Compose)和适应阶段(Adapt)。
-
组合阶段:在这个阶段,LoraHub会将多个预先训练好的LoRA模块整合成一个统一的模块。这个过程使用一组权重(w)作为系数来调节各个模块的贡献。
-
适应阶段:整合后的LoRA模块会在新任务的少量样本上进行评估。随后,LoraHub采用一种无梯度算法来优化权重w。经过K次迭代后,系统就能得到一个高度适应于目标任务的LoRA模块。
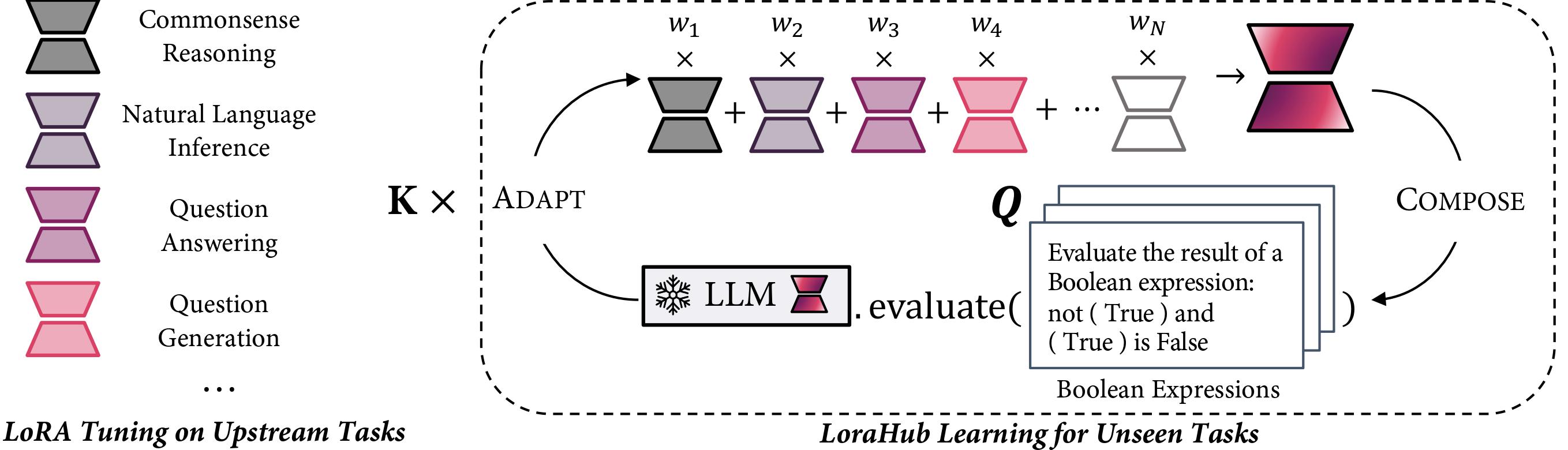
LoraHub的关键特性
-
高效的跨任务泛化:通过组合多个LoRA模块,LoraHub能够在不需要额外参数或训练的情况下,对新任务实现良好的泛化性能。
-
少样本学习能力:LoraHub只需要少量的示例就能快速适应新任务,这在资源受限或数据稀缺的场景下尤为重要。
-
灵活的模块组合:用户可以根据具体需求选择和组合不同的LoRA模块,实现任务的个性化适配。
-
计算效率高:LoraHub的推理吞吐量接近于零样本学习,同时性能表现可以媲美少样本上下文学习。
-
易于使用和集成:LoraHub提供了简洁的API接口,可以轻松地集成到现有的深度学习框架中。
LoraHub的实际应用
LoraHub在BIG-Bench Hard (BBH)基准测试中展现出了优异的性能。实验结果表明,LoraHub在少样本场景下的表现可以接近传统的上下文学习(ICL)方法,同时保持了较高的推理效率。
这种方法特别适用于以下场景:
-
快速原型开发:研究人员可以快速尝试不同任务的组合,加速模型迭代。
-
个性化AI应用:开发者可以根据用户需求动态组合不同的LoRA模块,提供定制化的语言服务。
-
资源受限环境:在计算资源有限的情况下,LoraHub可以实现高效的模型适应和部署。
-
持续学习系统:LoraHub为构建能够不断学习和适应新任务的AI系统提供了可能性。
LoraHub的未来展望
LoraHub的提出不仅为大语言模型的微调提供了一种新的思路,也为构建更加灵活和高效的AI系统开辟了新的可能性。研究团队表示,他们希望通过LoraHub建立一个开放的生态系统,让用户可以分享和交换训练好的LoRA模块,从而促进整个社区的协作和创新。
未来,LoraHub可能会在以下几个方向继续发展:
-
模块市场:建立一个类似App Store的LoRA模块市场,让开发者可以上传、下载和交易专门训练的LoRA模块。
-
自动化模块选择:开发智能算法,根据任务特性自动选择最适合的LoRA模块组合。
-
跨模态扩展:将LoraHub的思想扩展到其他模态,如视觉-语言模型的跨任务适应。
-
硬件优化:针对LoraHub的特点,开发专门的硬件加速方案,进一步提高推理效率。
结语
LoraHub的出现为大语言模型的应用开辟了新的可能性。它不仅提高了模型的适应性和效率,也为构建更加灵活和智能的AI系统提供了新的思路。随着技术的不断发展和社区的共同努力,我们有理由相信,LoraHub将在未来的AI领域发挥越来越重要的作用,推动自然语言处理技术向更高的水平迈进。
🔗 相关资源:
- LoraHub GitHub仓库:https://github.com/sail-sg/lorahub
- LoraHub论文:LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition
- LoraHub在线演示:Hugging Face Space
对于那些希望深入了解或尝试LoraHub的研究者和开发者,建议查阅项目的官方文档和示例代码。LoraHub的开源性质意味着整个社区都可以参与到这项技术的改进和应用中来,让我们共同期待LoraHub在推动AI技术发展方面带来的更多惊喜。









