
Mamba简介
Mamba是一种新型的状态空间模型(State Space Model, SSM)架构,由Albert Gu和Tri Dao于2023年提出。它在语言建模等信息密集型任务上展现出了令人瞩目的性能,弥补了之前亚二次方复杂度模型相对于Transformer的不足。Mamba基于结构化状态空间模型的研究进展,结合了高效的硬件感知设计和实现,体现了FlashAttention等工作的精神。
Mamba的核心特性
-
线性时间复杂度: Mamba模型的时间复杂度是输入序列长度的线性函数,这使得它在处理长序列时比标准Transformer更加高效。
-
选择性状态空间: Mamba引入了选择性状态空间的概念,允许模型动态地选择和更新相关的隐藏状态,从而提高了建模的灵活性和效率。
-
硬件感知设计: Mamba的设计考虑了现代硬件(如GPU)的特性,以实现高效的计算和内存使用。
-
与Transformer兼容: 尽管架构不同,Mamba在多项任务上的性能可以与同等规模的Transformer相媲美,甚至超越。
Mamba的实现
Mamba的核心实现包括以下几个主要组件:
-
选择性SSM层: 这是Mamba的核心创新,实现了动态选择和更新隐藏状态的机制。
-
Mamba块: 包装了选择性SSM层的主要模块,是构建Mamba网络的基本单元。
-
完整的语言模型: 将Mamba块堆叠并添加语言模型头,形成端到端的神经网络模型。
使用示例
以下是使用Mamba块的简单示例:
import torch
from mamba_ssm import Mamba
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
d_model=dim, # 模型维度
d_state=16, # SSM状态扩展因子
d_conv=4, # 局部卷积宽度
expand=2, # 块扩展因子
).to("cuda")
y = model(x)
assert y.shape == x.shape
预训练模型
Mamba团队提供了多个在300B token上预训练的模型,包括130M、370M、790M、1.4B和2.8B参数规模的版本。这些模型已上传至Hugging Face,可以直接下载使用。值得注意的是,这些是基础模型,没有经过下游任务的微调。
评估与推理
Mamba模型在多项零样本评估任务上展现出了与同等规模Transformer相当甚至更优的性能。研究者可以使用lm-evaluation-harness库来复现论文中的评估结果。
对于推理,Mamba提供了便捷的生成脚本,支持自动加载模型、生成文本补全以及基准测试推理速度。用户可以灵活配置采样策略、温度等参数。
Mamba-2的进展
最近,研究团队发布了Mamba-2,这是对原始Mamba架构的进一步改进。Mamba-2探索了Transformer和SSM之间的深层联系,提出了通过结构化状态空间对偶性实现的广义模型和高效算法。
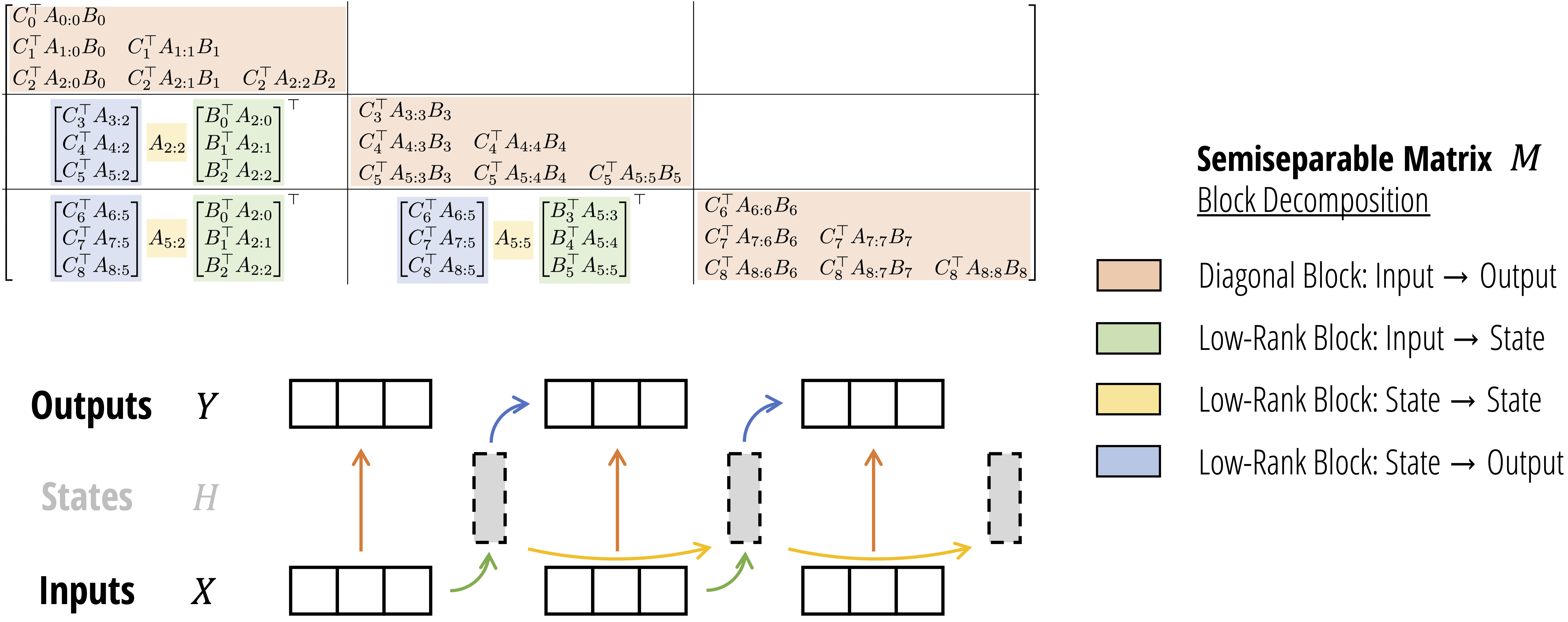
Mamba-2不仅保持了原始Mamba的高效性,还进一步提升了模型的表现力和灵活性。研究者可以像使用原始Mamba一样简单地使用Mamba-2模型。
安装与使用注意事项
安装Mamba相对简单,可以通过pip直接安装:
pip install mamba-ssm
使用时需要注意以下几点:
-
精度问题: Mamba对参数精度较为敏感,建议使用支持混合精度训练的框架。
-
初始化: 某些参数有特定的初始化方法,在使用某些训练框架时可能需要自定义初始化逻辑。
-
AMD显卡支持: 对于使用AMD显卡的用户,可能需要额外的ROCm补丁。
结语
Mamba作为一种新型的序列建模架构,展现出了强大的潜力。它不仅在理论上提出了创新的建模方法,还在实践中展示了优秀的性能和效率。随着Mamba-2的发布,这一架构的潜力得到了进一步的释放。对于研究者和开发者来说,Mamba提供了一个极具吸引力的选择,尤其是在处理长序列和信息密集型任务时。未来,我们可以期待看到更多基于Mamba的应用和进一步的理论突破。


















