
markdown-crawler项目简介
markdown-crawler是由Paul Pierre开发的一个多线程网站爬虫工具,能够递归爬取网站内容并为每个页面创建Markdown文件。该项目主要用于大型语言模型的文档解析,可以简化大型文档的分块和处理过程,特别适用于RAG(检索增强生成)等场景。
主要特性
markdown-crawler具有以下主要特性:
- 🧵 多线程支持,爬取速度更快
- ⏯️ 支持从中断处继续爬取
- ⏬ 可设置爬取深度
- 📄 支持表格、图片等元素
- ✅ 验证URL、HTML和文件路径
- ⚙️ 可配置有效的基础路径或域名
- 🍲 使用BeautifulSoup解析HTML
- 🪵 详细的日志选项
- 👩💻 便捷的命令行界面
安装与使用
- 通过pip安装:
pip install markdown-crawler
- 使用命令行运行:
markdown-crawler -t 5 -d 3 -b ./markdown https://en.wikipedia.org/wiki/Morty_Smith
- 在代码中使用:
from markdown_crawler import md_crawl
url = 'https://en.wikipedia.org/wiki/Morty_Smith'
md_crawl(url, max_depth=3, num_threads=5, base_path='markdown')
应用场景
- RAG(检索增强生成):用于规范化大型文档,按标题、段落或句子进行分块。
- LLM微调:创建大型Markdown文件语料库,用于提取Q&A对。
- 智能体知识:结合autogen等工具,重建视频游戏或电影的知识库。
- 智能体/LLM工具:用于在线RAG学习,让聊天机器人持续学习。
学习资源
运行效果展示
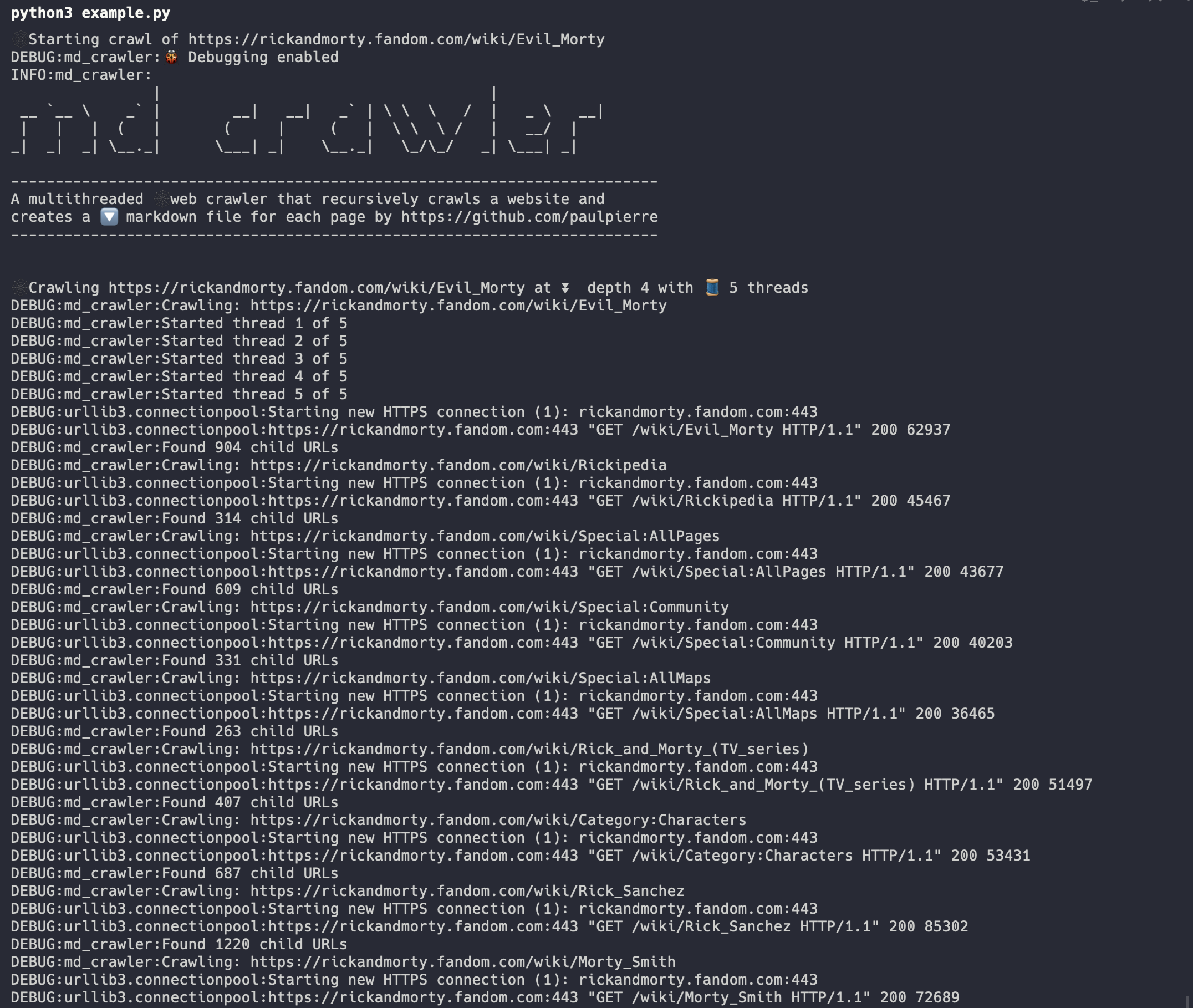
爬取过程:
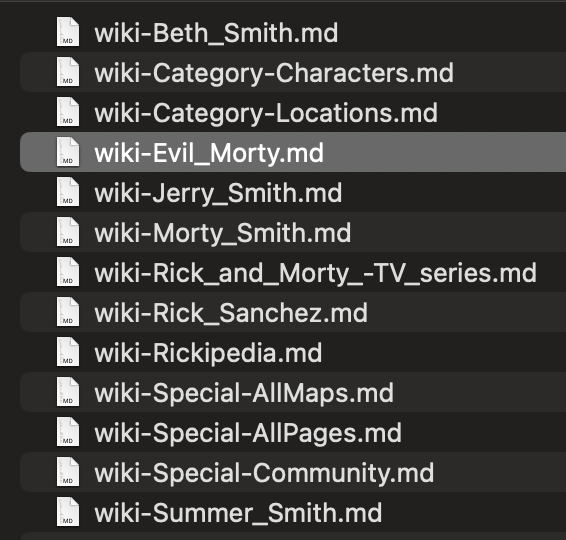
生成的Markdown文件:
总结
markdown-crawler是一个功能强大、易于使用的网站爬虫工具,特别适合用于大语言模型相关的文档处理任务。通过本文的介绍,读者可以快速了解该工具的主要特性和使用方法,并利用提供的学习资源进一步探索和应用这一工具。无论是用于个人学习还是专业项目,markdown-crawler都是一个值得尝试的选择。










