
Marker API简介
Marker API是一个强大的PDF转Markdown工具,它提供了一个简单的API端点,可以快速准确地将PDF文档转换为Markdown格式。只需一键部署,就可以开始无缝转换PDF文档。
主要特性
Marker API具有以下突出特点:
- 支持将PDF转换为Markdown格式
- 能够同时处理多个PDF文件
- 支持广泛的文档类型,包括书籍和科学论文
- 支持所有语言
- 可移除页眉、页脚和其他人工制品
- 格式化表格和代码块
- 提取并保存图像
- 将大部分公式转换为LaTeX格式
- 可在GPU、CPU或MPS上运行
性能对比
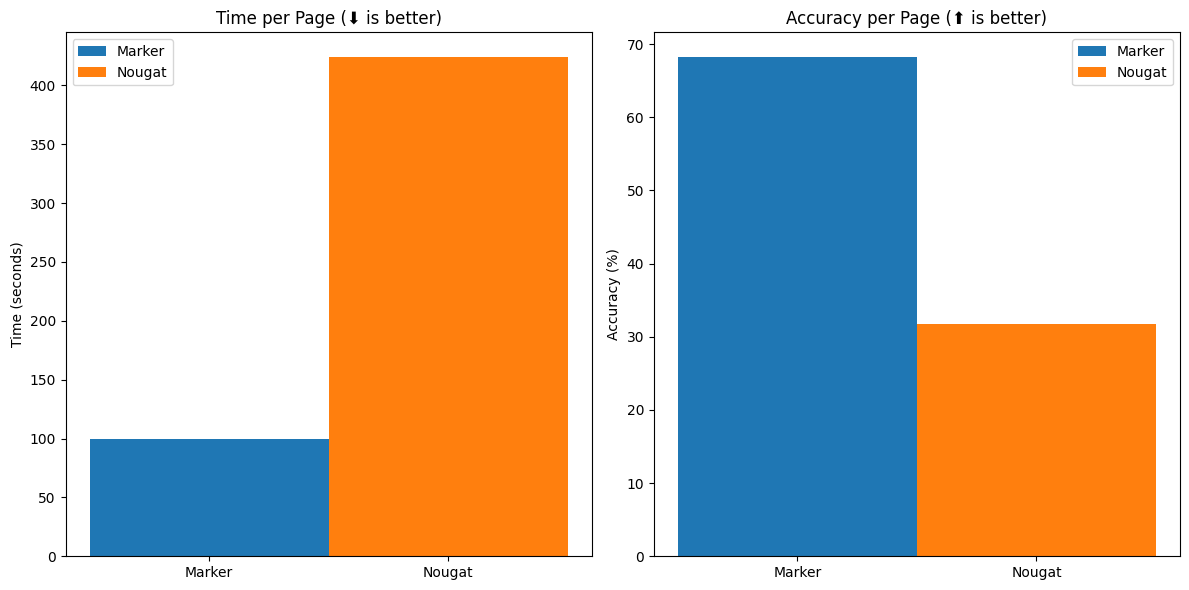
从上图可以看出,Marker API在速度和准确性方面都优于其他同类工具。与Nougat相比,Marker API的处理速度快4倍,并且在非arXiv文档上的准确性更高。
安装与设置
Marker API提供了多种安装和部署方式,以满足不同用户的需求。
Python环境安装
要在Python环境中安装Marker API,请按以下步骤操作:
- 从GitHub克隆Marker API仓库:
git clone https://github.com/adithya-s-k/marker-api
-
进入克隆的仓库目录
-
使用以下命令安装依赖:
poetry install
或
pip install -e .
安装完成后,可以通过marker_api命令运行服务器。
Docker部署
对于喜欢使用Docker的用户,可以通过以下步骤部署Marker API:
- 从Docker Hub拉取Marker API镜像:
docker pull savatar101/marker-api:0.3
- 运行Docker容器,暴露8000端口:
# 如果在GPU上运行
docker run --gpus all -p 8000:8000 savatar101/marker-api:0.3
# 否则
docker run -p 8000:8000 savatar101/marker-api:0.3
如果您想在本地构建Docker镜像,可以使用以下命令:
docker build -t marker-api .
# 如果在GPU上运行
docker run --gpus all -p 8000:8000 marker-api
# 否则
docker run -p 8000:8000 marker-api
使用Skypilot部署
Skypilot是一个框架,可以在任何云上运行LLMs、AI和批处理作业,提供最大的成本节省、最高的GPU可用性和托管执行。要使用Skypilot在任何云提供商上部署Marker API,请执行以下命令:
pip install skypilot-nightly[all]
# 使用您选择的云提供商设置skypilot
sky launch skypilot.yaml
有关更多信息,请参阅Skypilot文档。
API使用指南
Marker API提供了一个简单的REST API接口,用于将PDF文档转换为Markdown格式。以下是API的详细说明:
端点
- URL:
/convert - 方法:
POST
请求
- Body参数:
pdf_file: 要转换的PDF文件(类型:文件)extract_images(可选): 指定是否从PDF中提取图像。默认为true(类型:布尔值)
响应
- 成功响应:
- 状态码: 200 OK
- 内容: 包含转换后的Markdown文本、元数据和可选的提取图像数据的JSON
{
"markdown": "转换后的Markdown文本...",
"metadata": {...},
"images": {
"image_1": "data:image/png;base64,<base64编码的图像数据>",
"image_2": "data:image/png;base64,<base64编码的图像数据>",
...
}
}
如果响应中包含图像,它们将以base64编码格式提供。您可以使用此数据在应用程序中显示图像。
- 错误响应:
- 状态码: 415 Unsupported Media Type
- 内容: 包含错误详细信息的JSON
调用端点示例
CURL
curl -X POST \
-F "pdf_file=@example.pdf;type=application/pdf" \
http://localhost:8000/convert
Python
import requests
import os
url = "http://localhost:8000/convert"
pdf_file_path = "example.pdf"
with open(pdf_file_path, 'rb') as pdf_file:
pdf_content = pdf_file.read()
files = {'pdf_file': (os.path.basename(pdf_file_path), pdf_content, 'application/pdf')}
response = requests.post(url, files=files)
print(response.json())
JavaScript
const fetch = require('node-fetch');
const fs = require('fs');
const url = "http://localhost:8000/convert";
const pdfFilePath = "example.pdf";
fs.readFile(pdfFilePath, (err, pdfContent) => {
if (err) {
console.error(err);
return;
}
const formData = new FormData();
formData.append('pdf_file', new Blob([pdfContent], { type: 'application/pdf' }), pdfFilePath);
fetch(url, {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
});
性能基准测试
Marker API在速度和准确性方面都表现出色。以下是与其他PDF提取方法的详细比较:
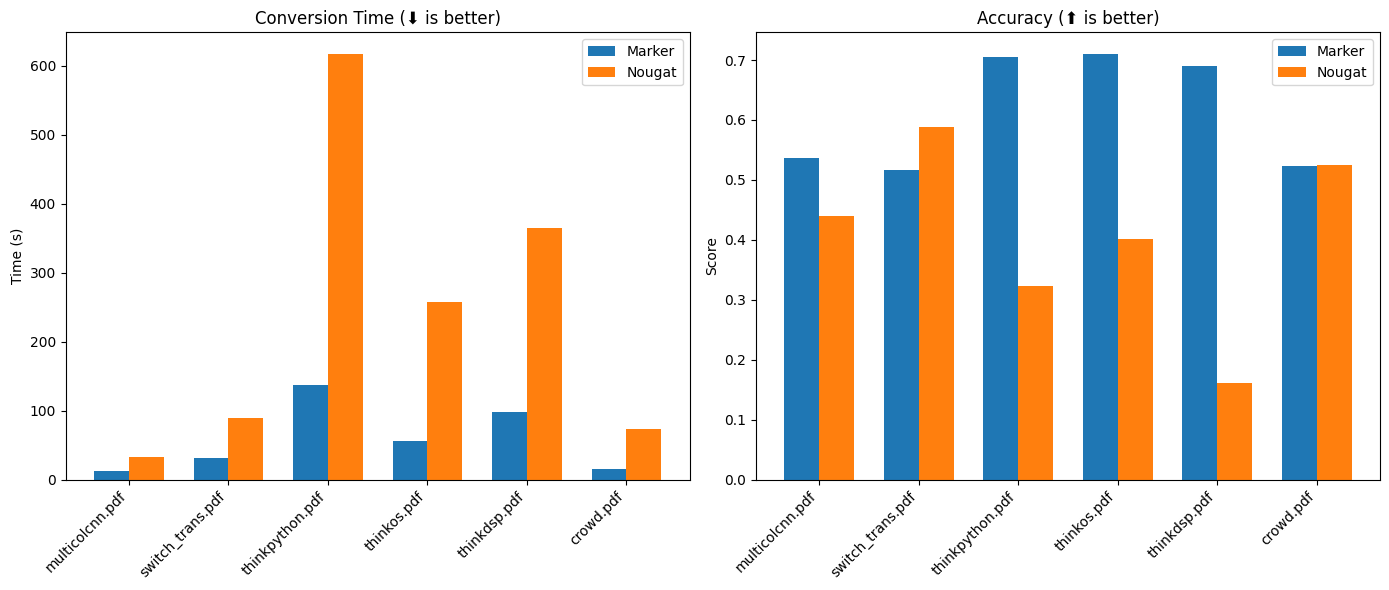
速度对比
| 方法 | 平均分数 | 每页处理时间 | 每文档处理时间 |
|---|---|---|---|
| marker | 0.613721 | 0.631991 | 58.1432 |
| nougat | 0.406603 | 2.59702 | 238.926 |
准确性对比
前3个是非arXiv书籍,后3个是arXiv论文。
| 方法 | multicolcnn.pdf | switch_trans.pdf | thinkpython.pdf | thinkos.pdf | thinkdsp.pdf | crowd.pdf |
|---|---|---|---|---|---|---|
| marker | 0.536176 | 0.516833 | 0.70515 | 0.710657 | 0.690042 | 0.523467 |
| nougat | 0.44009 | 0.588973 | 0.322706 | 0.401342 | 0.160842 | 0.525663 |
在基准测试期间,nougat的峰值GPU内存使用为4.2GB,而marker为4.1GB。基准测试在A6000 Ada上运行。
吞吐量
Marker平均每个任务占用约4.5GB的VRAM,因此在A6000上可以并行转换10个文档。
进阶使用技巧
处理多个文件
要一次性处理多个PDF文件,可以使用以下命令:
marker /path/to/input/folder /path/to/output/folder --workers 10 --max 10 --metadata_file /path/to/metadata.json --min_length 10000
--workers: 同时转换的PDF数量。默认为1,但可以增加以提高吞吐量,但会增加CPU/GPU使用率。--max: 要转换的最大PDF数量。省略此参数将转换文件夹中的所有PDF。--min_length: 从PDF中提取的最小字符数,低于此数量的PDF将不会被处理。--metadata_file: 可选的JSON文件路径,包含PDF的元数据。
使用多个GPU处理多个文件
对于需要更高处理能力的场景,可以使用多个GPU同时处理多个文件:
MIN_LENGTH=10000 METADATA_FILE=../pdf_meta.json NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
NUM_DEVICES: 要使用的GPU数量,应为2或更多。NUM_WORKERS: 每个GPU上运行的并行进程数。
故障排除
如果遇到问题,可以尝试以下设置:
OCR_ALL_PAGES: 设置为true以强制OCR所有页面。TORCH_DEVICE: 强制marker使用指定的torch设备进行推理。OCR_ENGINE: 可以设置为surya或ocrmypdf。DEBUG: 设置为True可在转换多个PDF时显示ray日志。
确保正确设置了语言或传递了元数据文件。如果遇到内存不足错误,请减少工作进程数量或增加VRAM_PER_TASK设置。
结语
Marker API为PDF到Markdown的转换提供了一个强大、高效的解决方案。它的高速度、准确性和灵活性使其成为处理各种文档类型的理想选择。无论是单个文件还是批量处理,Marker API都能满足您的需求。
随着项目的不断发展,未来还将添加更多功能,如服务器支持、单PDF和多PDF上传支持、Docker和Skypilot支持等。我们期待看到Marker API在各种应用场景中的表现,并欢迎社区成员参与到项目的改进中来。
如果您在使用过程中遇到任何问题或有任何建议,欢迎在GitHub仓库上提出issue或贡献代码。让我们一起努力,使Marker API成为PDF转Markdown领域的最佳选择!










