
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文Marker API
[!重要]
Marker API 提供了一个简单的端点,可以快速准确地将 PDF 文档转换为 Markdown。只需一键点击,您就可以部署 Marker API 端点并开始无缝转换 PDF。
功能特点
- 将 PDF 转换为 Markdown。
- 可同时转换多个 PDF。
- 支持广泛的文档类型,包括书籍和科学论文。
- 支持所有语言。
- 移除页眉、页脚和其他人工制品。
- 格式化表格和代码块。
- 提取并保存图像与 Markdown 一起。
- 将大多数方程转换为 LaTeX。
- 可在 GPU、CPU 或 MPS 上运行。
对比
| 原始 PDF | Marker-API | PyPDF |
|---|---|---|
 |  |  |
安装和设置
🐍 Python
要在 Python 环境中安装 Marker API,请按以下步骤操作:
- 从 GitHub 克隆 Marker API 仓库:
git clone https://github.com/adithya-s-k/marker-api
- 进入克隆的仓库目录:
cd marker-api
- 使用以下命令安装依赖:
poetry install 或 pip install -e .
安装完成后,您可以通过 marker_api 命令运行服务器
marker_api
或
python server.py
🛳️ Docker
要使用 Docker 运行 Marker API,请执行以下命令:
- 从 Docker Hub 拉取 Marker API Docker 镜像:
- 运行 Docker 容器,暴露 8000 端口: 👉🏼Docker 镜像
docker pull savatar101/marker-api:0.3
# 如果您在 GPU 上运行
docker run --gpus all -p 8000:8000 savatar101/marker-api:0.3
# 否则
docker run -p 8000:8000 savatar101/marker-api:0.3
或者,如果您更喜欢在本地构建 Docker 镜像: 然后,按如下方式运行 Docker 容器:
docker build -t marker-api .
# 如果您在 GPU 上运行
docker run --gpus all -p 8000:8000 marker-api
# 否则
docker run -p 8000:8000 marker-api
✈️ Skypilot
SkyPilot 是一个框架,用于在任何云上运行 LLM、AI 和批处理作业,提供最大的成本节省、最高的 GPU 可用性和托管执行。 要使用 Skypilot 在任何云提供商上部署 Marker API,请执行以下命令:
pip install skypilot-nightly[all]
# 使用您选择的云提供商设置 skypilot
sky launch skypilot.yaml
更多信息请参考 skypilot 文档。
使用方法
API 客户端代码:

端点
- URL:
/convert - 方法:
POST
请求
- 请求体参数:
pdf_file: 要转换的 PDF 文件。(类型: 文件)extract_images(可选): 指定是否从 PDF 中提取图像。默认为true。(类型: 布尔值)
响应
-
成功响应:
-
代码: 200 OK
-
内容: 包含转换后的 Markdown 文本、元数据和可选的提取图像数据的 JSON。
{ "markdown": "转换后的 Markdown 文本...", "metadata": {...}, "images": { "image_1": "data:image/png;base64,<base64编码的图像数据>", "image_2": "data:image/png;base64,<base64编码的图像数据>", ... } }
如果响应中包含图像,它们以 base64 编码格式提供。您可以使用这些数据在应用程序中显示图像。此外,您可以使用以下 Python 脚本 invoke.py 来调用端点,处理本地 PDF 文件并在本地保存图像
-
-
错误响应:
- 代码: 415 不支持的媒体类型
- 内容: 包含错误详情的 JSON。
调用端点
CURL
curl -X POST \
-F "pdf_file=@example.pdf;type=application/pdf" \
http://localhost:8000/convert
Python
有关如何调用 API 并将其保存为 Markdown 的示例,请参考 Notebook 和 脚本
import requests
import os
url = "http://localhost:8000/convert"
pdf_file_path = "example.pdf"
with open(pdf_file_path, 'rb') as pdf_file:
pdf_content = pdf_file.read()
files = {'pdf_file': (os.path.basename(pdf_file_path), pdf_content, 'application/pdf')}
response = requests.post(url, files=files)
print(response.json())
JavaScript
const fetch = require('node-fetch');
const fs = require('fs');
const url = "http://localhost:8000/convert";
const pdfFilePath = "example.pdf";
fs.readFile(pdfFilePath, (err, pdfContent) => {
if (err) {
console.error(err);
return;
}
const formData = new FormData();
formData.append('pdf_file', new Blob([pdfContent], { type: 'application/pdf' }), pdfFilePath);
fetch(url, {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
});
Marker 说明
Marker 能够快速准确地将 PDF 转换为 markdown。
- 支持广泛的文档类型(针对书籍和科学论文进行了优化)
- 支持所有语言
- 移除页眉/页脚/其他人工制品
- 格式化表格和代码块
- 提取并保存图像与 markdown 一起
- 将大多数方程转换为 latex
- 可在 GPU、CPU 或 MPS 上运行
工作原理
Marker 是一个深度学习模型管道:
- 提取文本,必要时进行 OCR(启发式方法,surya,tesseract)
- 检测页面布局并找到阅读顺序(surya)
- 清理和格式化每个块(启发式方法,texify)
- 合并块并对完整文本进行后处理(启发式方法,pdf_postprocessor)
它仅在必要时使用模型,从而提高速度和准确性。
示例
| 类型 | Marker | Nougat | |
|---|---|---|---|
| Think Python | 教科书 | 查看 | 查看 |
| Think OS | 教科书 | 查看 | 查看 |
| Switch Transformers | arXiv论文 | 查看 | 查看 |
| Multi-column CNN | arXiv论文 | 查看 | 查看 |
性能
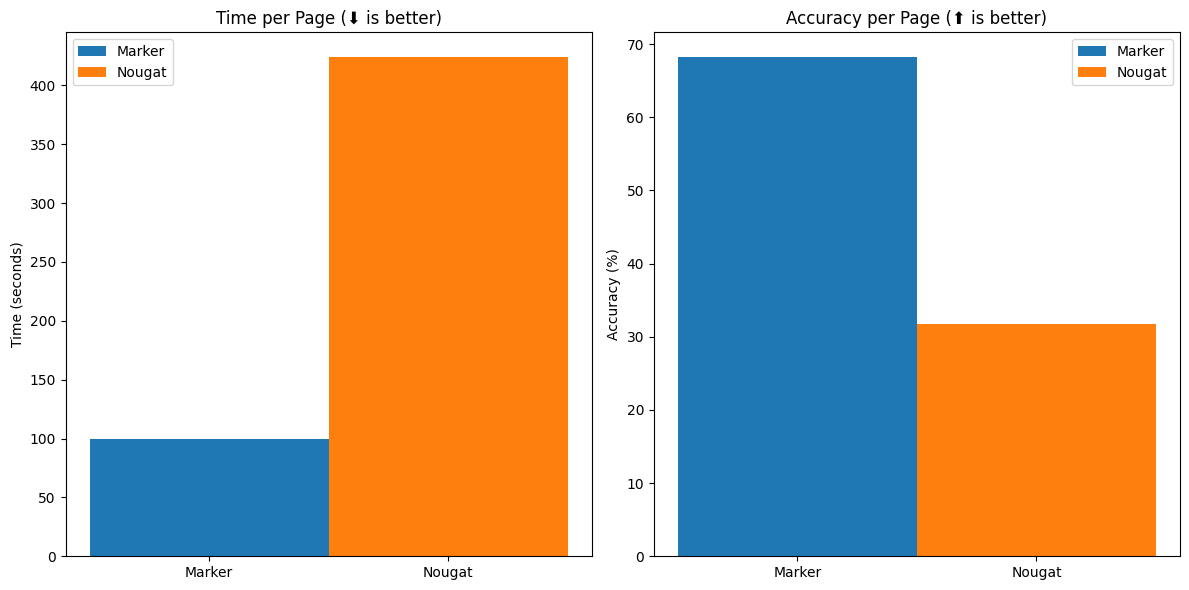
上述结果是在marker和nougat设置为每个占用A6000上约4GB显存的情况下得出的。
有关详细的速度和准确性基准测试以及如何运行自己的基准测试的说明,请参见下文。
商业用途
我希望marker能尽可能广泛地使用,同时仍能为我的开发/训练成本提供资金支持。研究和个人使用始终是允许的,但对商业使用有一些限制。
模型权重的许可为cc-by-nc-sa-4.0,但对于最近12个月内总收入低于500万美元且累计风险投资/天使投资融资额低于500万美元的任何组织,我将豁免该许可。如果您想取消GPL许可要求(双重许可)和/或在超过收入限制的情况下商业使用权重,请查看这里的选项。
社区
我们在Discord上讨论未来的开发。
局限性
PDF是一种棘手的格式,因此marker并不总是能完美工作。以下是一些已知的限制,我们计划在未来解决:
- Marker不会将100%的方程转换为LaTeX。这是因为它需要先检测再转换。
- 表格并不总是100%正确格式化 - 文本可能出现在错误的列中。
- 空白和缩进并不总是被严格遵守。
- 并非所有的行/跨度都能正确连接。
- 这最适用于不需要大量OCR处理的数字PDF。它针对速度进行了优化,并使用有限的OCR来修复错误。
安装
您需要Python 3.9+和PyTorch。如果您不使用Mac或GPU机器,可能需要先安装CPU版本的torch。有关更多详细信息,请参见此处。
使用以下命令安装:
pip install marker-pdf
可选:OCRMyPDF
仅在您想使用可选的ocrmypdf作为OCR后端时需要。请注意,ocrmypdf包含Ghostscript(一个AGPL依赖项),但通过CLI调用它,因此不会触发许可条款。
请参阅此处的说明
使用方法
首先,进行一些配置:
- 检查
marker/settings.py中的设置。您可以使用环境变量覆盖任何设置。 - 您的torch设备将被自动检测,但您可以覆盖它。例如,
TORCH_DEVICE=cuda。- 如果使用GPU,请将
INFERENCE_RAM设置为您的GPU显存(每个GPU)。例如,如果您有16 GB的显存,请设置INFERENCE_RAM=16。 - 根据您的文档类型,marker的每个任务的平均内存使用量可能略有不同。如果您注意到任务因GPU内存不足错误而失败,可以配置
VRAM_PER_TASK来调整此问题。
- 如果使用GPU,请将
- 默认情况下,marker将使用
surya进行OCR。Surya在CPU上速度较慢,但比tesseract更准确。如果您想要更快的OCR,请将OCR_ENGINE设置为ocrmypdf。这还需要外部依赖项(见上文)。如果您完全不需要OCR,请将OCR_ENGINE设置为None。
转换单个文件
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10 --langs English
--batch_multiplier是在有额外显存的情况下默认批量大小的倍数。数值越高,需要的显存越多,但处理速度越快。默认设置为2。默认批量大小将占用约3GB显存。--max_pages是要处理的最大页数。省略此选项将转换整个文档。--langs是文档中语言的逗号分隔列表,用于OCR
确保DEFAULT_LANG设置适合您的文档。OCR支持的语言列表在这里。如果您需要更多语言,可以在将OCR_ENGINE设置为ocrmypdf的情况下使用Tesseract支持的任何语言。如果您不需要OCR,marker可以处理任何语言。
转换多个文件
marker /path/to/input/folder /path/to/output/folder --workers 10 --max 10 --metadata_file /path/to/metadata.json --min_length 10000
--workers是同时转换的PDF数量。默认设置为1,但您可以增加它以提高吞吐量,代价是更多的CPU/GPU使用率。如果您使用GPU,并行度不会超过INFERENCE_RAM / VRAM_PER_TASK。--max是要转换的PDF的最大数量。省略此选项将转换文件夹中的所有PDF。--min_length是从PDF中提取的字符数的最小值,只有达到这个值才会考虑进行处理。如果您正在处理大量PDF,我建议设置此选项以避免对主要是图像的PDF进行OCR(会减慢整体速度)。--metadata_file是一个可选的JSON文件路径,包含有关PDF的元数据。如果提供,它将用于设置每个PDF的语言。如果未提供,将使用DEFAULT_LANG。格式如下:
{
"pdf1.pdf": {"languages": ["English"]},
"pdf2.pdf": {"languages": ["Spanish", "Russian"]},
...
}
您可以使用语言名称或代码。确切的代码取决于OCR引擎。有关surya代码的完整列表,请参见此处,有关tesseract的完整列表,请参见此处。
在多个GPU上转换多个文件
MIN_LENGTH=10000 METADATA_FILE=../pdf_meta.json NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
METADATA_FILE是一个可选的 json 文件路径,包含有关 PDF 的元数据。格式见上文。NUM_DEVICES是要使用的 GPU 数量。应为2或更多。NUM_WORKERS是每个 GPU 上运行的并行进程数。每个 GPU 的并行度不会超过INFERENCE_RAM / VRAM_PER_TASK。MIN_LENGTH是从 PDF 中提取的字符数量的最小值,低于此值的 PDF 将不会被处理。如果你要处理大量 PDF,我建议设置此项以避免对主要是图像的 PDF 进行 OCR(会减慢整个过程)。
请注意,上述环境变量仅适用于此脚本,不能在 local.env 中设置。
故障排除
如果things不按预期工作,以下是一些可能有用的设置:
OCR_ALL_PAGES- 设为 true 以强制对所有页面进行 OCR。如果表格布局无法正确识别或文本混乱,这很有用。TORCH_DEVICE- 设置此项以强制 marker 使用指定的 torch 设备进行推理。OCR_ENGINE- 可设置为surya或ocrmypdf。DEBUG- 设为True可在转换多个 PDF 时显示 ray 日志。- 验证你是否正确设置了语言,或传入了元数据文件。
- 如果遇到内存不足错误,请减少工作进程数量(增加
VRAM_PER_TASK设置)。你也可以尝试将长 PDF 拆分为多个文件。
通常,如果输出不符合预期,尝试对 PDF 进行 OCR 是个好的第一步。并非所有 PDF 都嵌入了良好的文本/边界框。
基准测试
对 PDF 提取质量进行基准测试很困难。我通过寻找同时有 PDF 版本和 LaTeX 源码的书籍和科学论文创建了一个测试集。我将 LaTeX 转换为文本,并将参考文本与文本提取方法的输出进行比较。这种方法有噪声,但至少方向正确。
基准测试表明,marker 比 nougat 快 4 倍,在 arXiv 之外的准确度更高(nougat 是在 arXiv 数据上训练的)。我们还展示了朴素文本提取(不经处理直接从 PDF 中提取文本)作为对比。
速度
| 方法 | 平均分数 | 每页时间 | 每文档时间 |
|---|---|---|---|
| marker | 0.613721 | 0.631991 | 58.1432 |
| nougat | 0.406603 | 2.59702 | 238.926 |
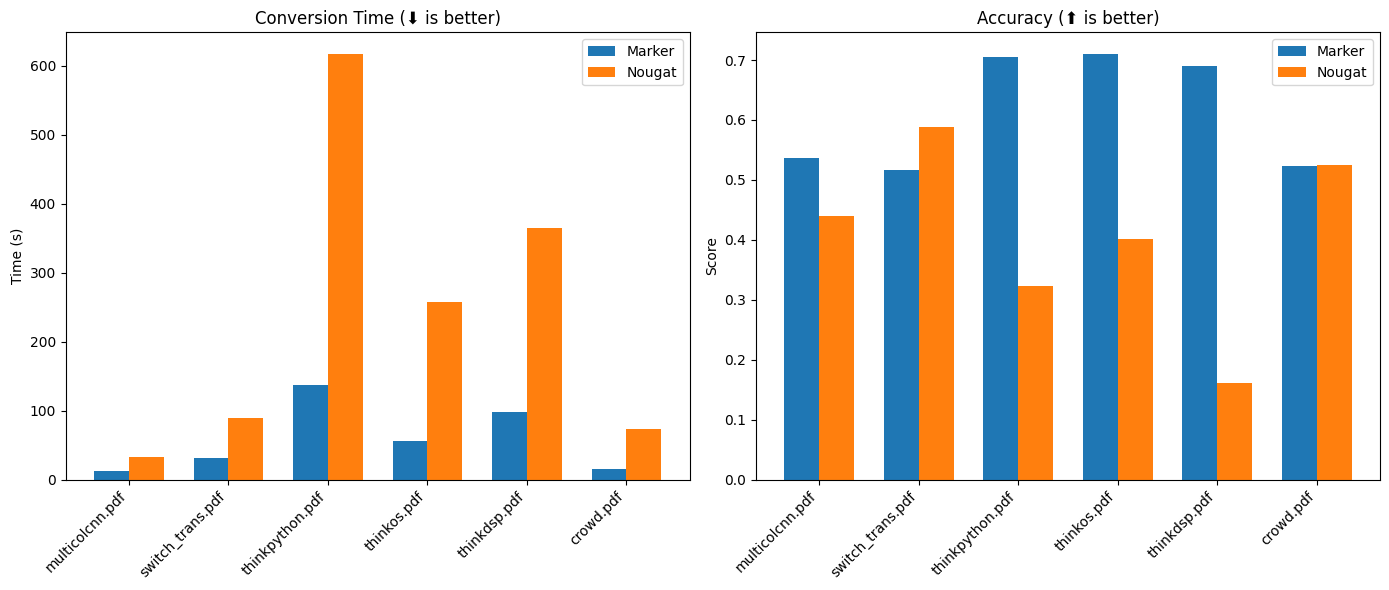
准确度
前 3 个是非 arXiv 书籍,后 3 个是 arXiv 论文。
| 方法 | multicolcnn.pdf | switch_trans.pdf | thinkpython.pdf | thinkos.pdf | thinkdsp.pdf | crowd.pdf |
|---|---|---|---|---|---|---|
| marker | 0.536176 | 0.516833 | 0.70515 | 0.710657 | 0.690042 | 0.523467 |
| nougat | 0.44009 | 0.588973 | 0.322706 | 0.401342 | 0.160842 | 0.525663 |
基准测试期间的峰值 GPU 内存使用量为 nougat 的 4.2GB 和 marker 的 4.1GB。基准测试在 A6000 Ada 上运行。
吞吐量
Marker 平均每个任务占用约 4.5GB 的 VRAM,因此你可以在 A6000 上同时转换 10 个文档。
运行你自己的基准测试
你可以在自己的机器上对 marker 的性能进行基准测试。手动安装 marker:
git clone https://github.com/VikParuchuri/marker.git
poetry install
在这里下载基准数据并解压。然后像这样运行 benchmark.py:
python benchmark.py data/pdfs data/references report.json --nougat
这将对 marker 和其他文本提取方法进行基准测试。它为 nougat 和 marker 设置批处理大小,以使每个方法使用相似数量的 GPU RAM。
省略 --nougat 可以将 nougat 排除在基准测试之外。我不建议在 CPU 上运行 nougat,因为它非常慢。
致谢
没有这些令人惊叹的开源模型和数据集,这项工作是不可能完成的,包括(但不限于):
- Surya
- Texify
- Pypdfium2/pdfium
- IBM 的 DocLayNet
- Google 的 ByT5
感谢这些模型和数据集的作者将它们提供给社区!
待办事项
- 创建服务器
- 添加单个 PDF 上传支持
- 添加多个 PDF 上传支持
- Docker 支持和 Skypilot 支持
- 实现同时处理多个 PDF 上传
- 引入切换模式,生成不包含图像的 Markdown 输出
- 提高 GPU 利用率并优化性能以提高处理效率
- 实现基于可用 VRAM 动态调整批处理大小
- 转换进度的实时更新 API
吞吐量基准测试
吞吐量基准测试的更新将很快推出。
致谢
本项目建立在 VikParuchuri 创建的出色的 marker 项目之上。我们对该项目提供的灵感和基础表示感谢。











