
MaskDINO简介
MaskDINO是由IDEA研究团队开发的一个统一的基于Transformer的目标检测和分割框架。它的名字中的"DINO"代表"DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection",而"Mask"则表明它扩展了DINO的能力,使其能够处理各种分割任务。
MaskDINO的主要目标是提供一个统一的架构,能够同时处理目标检测、全景分割、实例分割和语义分割等多个视觉任务。这种统一的方法不仅简化了模型的设计和训练过程,还实现了任务和数据之间的协同效应,从而在各项任务上都取得了优异的性能。
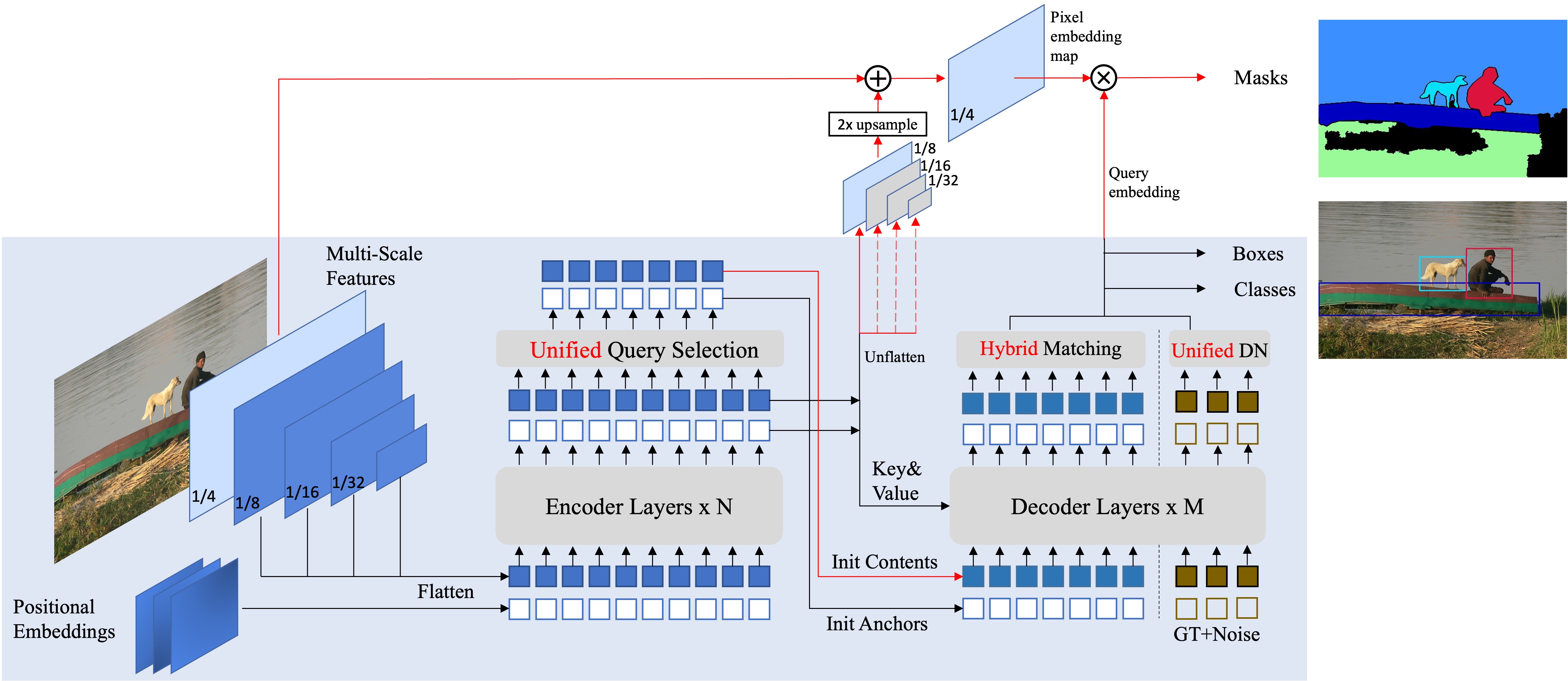
MaskDINO的主要特点
-
统一架构: MaskDINO提供了一个统一的架构,可以同时处理目标检测、全景分割、实例分割和语义分割任务。这种设计大大简化了模型的复杂性,同时也提高了各任务之间的协同效应。
-
任务和数据协同: 通过统一的架构,MaskDINO实现了不同视觉任务之间的协同效应,同时也能更好地利用来自不同数据集的信息。
-
最先进的性能: 在相同的设置下,MaskDINO在多个基准测试中都达到了最先进的性能水平。
-
广泛的数据集支持: MaskDINO支持多个主要的检测和分割数据集,包括COCO、ADE20K和Cityscapes等。
-
灵活的模型组件: MaskDINO由三个主要组件构成:backbone、像素解码器和Transformer解码器。用户可以根据需要轻松替换这些组件,以适应不同的应用场景。
MaskDINO的技术细节
模型架构
MaskDINO的架构主要包含三个部分:
-
Backbone: 负责提取图像的基本特征。MaskDINO支持多种backbone,如ResNet和Swin Transformer等。
-
像素解码器: 实际上是DINO和Deformable DETR中的多尺度编码器。它负责处理backbone提取的特征,生成多尺度的特征图。
-
Transformer解码器: 主要遵循DINO解码器的设计,用于执行检测和分割任务。
掩码增强的框初始化
MaskDINO引入了一种新的技术,称为掩码增强的框初始化(Mask-enhanced box initialization)。这种方法通过利用预测的掩码来初始化解码器的框,从而提高了模型的性能。用户可以选择不同的转换方式,如"mask2box"或"bitmask"。
灵活的组件替换
MaskDINO的设计允许用户轻松替换各个组件。例如,可以在maskdino/modeling/backbone下定义和注册新的backbone,或者在maskdino/modeling/pixel_decoder中修改像素解码器的实现。这种灵活性使得研究人员和开发者可以根据具体需求定制模型。
MaskDINO的性能表现
MaskDINO在多个视觉任务和数据集上都展现出了优异的性能:
-
COCO实例分割和目标检测:
- 使用ResNet-50作为backbone,在50个epoch的训练后,MaskDINO达到了46.3的Mask AP和51.7的Box AP。
- 使用Swin-L作为backbone,在50个epoch的训练后,MaskDINO达到了52.3的Mask AP和59.0的Box AP。
-
COCO全景分割:
- 使用ResNet-50作为backbone,MaskDINO达到了53.0的PQ(Panoptic Quality)。
- 使用Swin-L作为backbone,MaskDINO达到了58.3的PQ。
-
语义分割:
- 在ADE20K数据集上,使用ResNet-50作为backbone,MaskDINO达到了48.7的mIoU。
- 在Cityscapes数据集上,使用ResNet-50作为backbone,MaskDINO达到了79.8的mIoU。
这些结果表明,MaskDINO在各种视觉任务上都取得了最先进的性能,展示了其作为统一视觉框架的强大能力。
MaskDINO的应用和潜力
MaskDINO的统一框架为计算机视觉领域带来了新的可能性:
-
多任务学习: 通过同时处理多个视觉任务,MaskDINO可以学习到更加通用和鲁棒的特征表示,这对于实际应用中的复杂场景非常有利。
-
迁移学习: MaskDINO的统一架构使得在不同任务和数据集之间进行知识迁移变得更加容易,这对于解决数据稀缺的问题特别有帮助。
-
实时视觉系统: 虽然MaskDINO的计算复杂度较高,但其统一的架构为未来开发更高效的实时视觉系统提供了可能性。
-
自动驾驶: MaskDINO在目标检测和各种分割任务上的优异表现使其非常适合用于自动驾驶场景,可以同时处理车辆检测、道路分割等多个任务。
-
医学影像分析: 在医学影像领域,MaskDINO可以用于同时进行器官检测和分割,提高诊断的准确性和效率。
-
遥感图像分析: MaskDINO的多任务能力使其成为处理复杂遥感图像的理想选择,可以同时进行地物分类、目标检测等任务。
未来展望
尽管MaskDINO已经取得了令人印象深刻的成果,但研究团队仍在不断改进和扩展这个框架:
-
模型效率优化: 未来的研究可能会关注如何在保持高性能的同时降低模型的计算复杂度和内存需求。
-
更大规模的预训练: 随着计算资源的增加,可以期待看到在更大规模的数据集上预训练的MaskDINO模型,这可能会进一步提升其性能和泛化能力。
-
跨模态学习: 将MaskDINO扩展到处理图像之外的其他模态,如视频或点云数据,是一个有趣的研究方向。
-
自监督学习: 探索如何在无标注或少量标注的数据上训练MaskDINO,以减少对大规模标注数据的依赖。
-
与其他AI技术的结合: 将MaskDINO与自然语言处理或强化学习等其他AI技术结合,可能会开启新的应用场景。
结论
MaskDINO作为一个统一的基于Transformer的目标检测和分割框架,展示了深度学习模型在处理复杂视觉任务时的巨大潜力。它不仅在多个基准测试中取得了最先进的性能,还为未来的计算机视觉研究和应用提供了一个强大的基础。随着持续的改进和创新,我们可以期待MaskDINO在各种实际应用中发挥越来越重要的作用,推动计算机视觉技术的进一步发展。
研究人员、开发者和企业可以利用MaskDINO来构建更加智能和高效的视觉系统,解决从自动驾驶到医疗诊断等广泛领域的挑战。同时,MaskDINO的开源特性也为整个计算机视觉社区提供了一个宝贵的资源,促进了知识的共享和技术的进步。
随着人工智能和计算机视觉技术的不断发展,像MaskDINO这样的统一框架将继续推动着技术的前沿,为我们创造一个更加智能和互联的世界。









