
MInference:突破长上下文LLM推理瓶颈的新方法
在人工智能快速发展的今天,大语言模型(LLM)的应用越来越广泛。然而,随着模型规模的不断扩大和上下文长度的增加,LLM在推理阶段面临着严重的性能瓶颈。为了解决这一问题,微软研究院推出了一项名为MInference的创新技术,旨在显著提升长上下文LLM的推理速度,同时保持模型的准确性。
MInference的核心原理
MInference的核心思想是利用LLM注意力机制中存在的动态稀疏性。研究人员发现,在LLM的注意力计算中,并非所有的注意力都是同等重要的。实际上,大部分注意力权重都集中在少数关键位置上,而其他位置的权重则相对较小。基于这一观察,MInference采用了两个关键策略:
- 离线确定稀疏模式:MInference首先对模型的每个注意力头进行分析,确定它们各自属于哪种稀疏模式。这些模式可能包括垂直线、斜线或块状等形式。
- 在线近似和动态计算:在推理过程中,MInference使用优化的自定义内核来近似稀疏索引,并动态地计算注意力。这种方法既保留了关键信息,又大大减少了计算量。
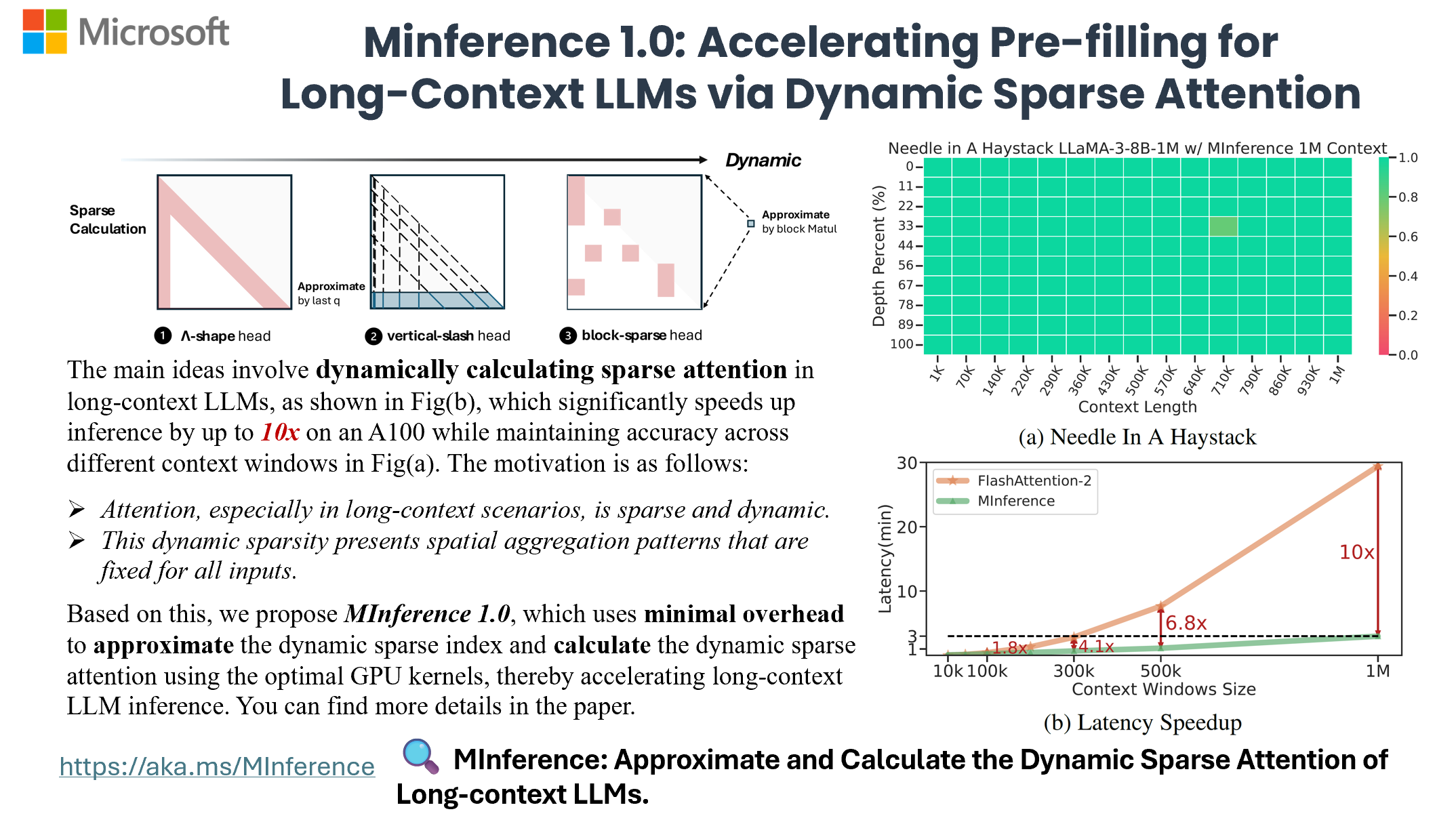
MInference的性能表现
根据微软的研究报告,MInference在性能方面取得了令人瞩目的成果:
-
速度提升:在A100 GPU上,MInference可以将长上下文LLM的预填充阶段速度提高多达10倍。这意味着原本需要数分钟处理的长文本,现在可能只需要几秒钟。
-
准确性保持:尽管大幅提升了速度,MInference并没有牺牲模型的准确性。这一点对于保持LLM的实际应用价值至关重要。
-
适用范围广:MInference不仅限于特定类型的模型,它支持多种流行的长上下文LLM,包括LLaMA-3、GLM-4、Yi、Phi-3和Qwen2等。
MInference的应用前景
MInference的出现为长上下文LLM的实际应用打开了新的可能性:
- 提升用户体验:更快的推理速度意味着用户可以获得更快的响应,这对于需要实时交互的应用场景尤为重要。
- 降低计算成本:通过减少推理时间,MInference可以帮助企业和研究机构降低GPU使用成本,使大规模部署长上下文LLM变得更加经济可行。
- 扩展应用场景:更高效的推理性能使得长上下文LLM可以在更多领域发挥作用,如复杂文档分析、大规模信息检索等。
MInference的技术细节
为了更好地理解MInference的工作原理,我们来深入探讨一些技术细节:
-
动态稀疏注意力模式:MInference识别出的主要稀疏模式包括垂直线、斜线和块状。这些模式反映了不同类型的注意力头在处理长序列时的不同行为特征。
-
自定义CUDA内核:为了实现高效的稀疏注意力计算,MInference开发了专门的CUDA内核。这些内核针对不同的稀疏模式进行了优化,可以快速执行近似计算。
-
动态编译器PIT:MInference利用了一个名为PIT的动态编译器,它可以根据运行时的具体情况生成最优的执行代码,进一步提升性能。
MInference与其他技术的比较
在探讨MInference的优势时,我们不能忽视它与其他相关技术的比较:
-
状态空间模型(SSM):与SSM相比,MInference不需要从头训练模型,可以直接应用于现有的预训练LLM。
-
线性注意力:MInference保留了传统注意力机制的非线性特性,可能在处理复杂语义关系时表现更好。
-
静态稀疏注意力:相比于静态方法,MInference的动态特性使其能够更好地适应不同输入的语义结构。
MInference的实际应用示例
为了帮助开发者和研究人员更好地理解和使用MInference,微软提供了详细的应用指南:
- 与Hugging Face集成:
from transformers import pipeline
from minference import MInference
pipe = pipeline("text-generation", model=model_name, torch_dtype="auto", device_map="auto")
# 应用MInference补丁
minference_patch = MInference("minference", model_name)
pipe.model = minference_patch(pipe.model)
pipe(prompt, max_length=10)
- 与vLLM集成:
from vllm import LLM, SamplingParams
from minference import MInference
llm = LLM(model_name, max_num_seqs=1, enforce_eager=True, max_model_len=128000)
# 应用MInference补丁
minference_patch = MInference("vllm", model_name)
llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)
这些示例展示了MInference如何轻松集成到现有的LLM应用框架中,使开发者能够快速享受到性能提升的好处。
MInference的未来发展
虽然MInference已经展现出了巨大的潜力,但研究团队并未就此止步。他们计划在以下几个方向继续推进研究:
-
扩展模型支持:持续适配更多的长上下文LLM,以满足不同应用场景的需求。
-
理论基础研究:深入探讨动态稀疏注意力模式背后的理论基础,为未来的模型设计提供指导。
-
多模态扩展:探索将MInference的思想应用到多模态LLM中,如视觉-语言模型等。
-
硬件优化:与硬件厂商合作,开发专门针对动态稀疏注意力计算的加速器。
结语
MInference的出现无疑为长上下文LLM的发展注入了新的活力。它不仅解决了推理速度的瓶颈问题,还为LLM的实际应用开辟了新的可能性。随着技术的不断完善和应用范围的扩大,我们有理由相信,MInference将在推动AI技术向前发展的过程中发挥重要作用。
对于研究人员和开发者来说,深入了解和应用MInference不仅可以提升自己的技术水平,还能为未来的AI应用创新奠定基础。随着更多的实际应用案例出现,我们期待看到MInference在各个领域发挥其变革性的力量,为人工智能的发展贡献一份力量。









