
mLoRA:高效的多LoRA适配器训练与推理框架
在大型语言模型(LLM)蓬勃发展的今天,如何高效地对这些模型进行定制化微调成为了一个关键问题。mLoRA(Multi-LoRA)作为一个创新的开源框架,为这个问题提供了一个优雅的解决方案。本文将深入介绍mLoRA的设计理念、核心特性、使用方法以及其在提高训练效率方面的显著优势。
mLoRA的核心理念与特性
mLoRA的设计初衷是为了解决在同时训练多个LoRA(Low-Rank Adaptation)适配器时所面临的计算资源和内存消耗问题。它的核心思想是通过智能的资源管理和并行计算,在一个共享的基础模型上同时训练多个LoRA适配器。这种方法不仅大大提高了资源利用率,还显著加快了训练速度。
mLoRA的主要特性包括:
- 并发训练多个LoRA适配器
- 多个适配器共享基础模型
- 高效的流水线并行算法
- 支持多种LoRA变体算法和基础模型
- 支持多种强化学习偏好对齐算法
这些特性使得mLoRA能够在有限的硬件资源下,高效地训练和管理多个定制化的语言模型。
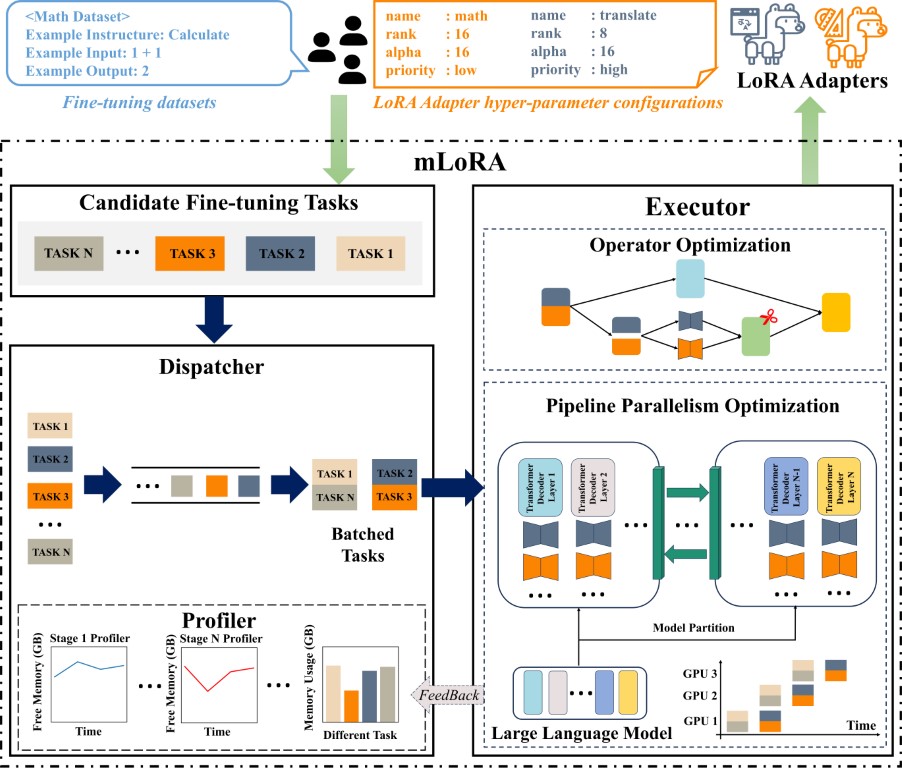
上图展示了mLoRA的端到端架构。我们可以看到,mLoRA通过巧妙的设计,实现了多个LoRA适配器的并行训练,同时保持了对基础模型的共享。
快速上手mLoRA
要开始使用mLoRA,首先需要克隆项目仓库并安装依赖:
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
pip install .
mLoRA提供了一个名为mlora_train.py的脚本作为批量微调LoRA适配器的入口点。以下是一个基本的使用示例:
python mlora_train.py \
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4 \
--config demo/lora/lora_case_1.yaml
在这个例子中,我们使用TinyLlama作为基础模型,并通过配置文件指定了LoRA适配器的训练参数。
使用流水线并行部署
mLoRA还支持使用流水线并行来进一步提高训练效率。以下是在两个节点环境中启动训练的示例命令:
# 在第一个节点上
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py \
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4 \
--config demo/lora/lora_case_1.yaml \
--pipeline \
--device "cuda:0" \
--rank 0 \
--balance 12 13 \
--recompute False \
--precision fp32
# 在第二个节点上
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py \
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4 \
--config demo/lora/lora_case_1.yaml \
--pipeline \
--device "cuda:1" \
--rank 1 \
--balance 12 13 \
--recompute False \
--precision fp32
这种配置允许跨多个GPU或机器分配模型层,从而实现更高效的并行训练。
使用Docker快速部署
为了简化部署过程,mLoRA提供了官方Docker镜像。您可以通过以下步骤使用Docker快速开始:
- 拉取最新的镜像:
docker pull yezhengmaolove/mlora:latest
- 运行容器并挂载必要的卷:
docker run -itd --runtime nvidia --gpus all \
-v ~/your_dataset_dir:/dataset \
-v ~/your_model_dir:/model \
-p <host_port>:22 \
--name mlora \
yezhengmaolove/mlora:latest
- 通过SSH登录容器并运行mLoRA:
ssh root@localhost -p <host_port>
cd /mLoRA
git pull
python mlora_train.py \
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4 \
--config demo/lora/lora_case_1.yaml
将mLoRA部署为服务
mLoRA还可以部署为一个持续接收用户请求并执行微调任务的服务。以下是部署mLoRA服务器的步骤:
- 拉取最新的Docker镜像:
docker pull yezhengmaolove/mlora:latest
- 部署mLoRA服务器:
docker run -itd --runtime nvidia --gpus all \
-v ~/your_dataset_cache_dir:/cache \
-v ~/your_model_dir:/model \
-p <host_port>:8000 \
--name mlora_server \
-e "BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4" \
-e "STORAGE_DIR=/cache" \
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh
- 安装并使用
mlora_cli与服务器交互:
pip install mlora-cli
mlora_cli
(mLoRA) set port <host_port>
(mLoRA) set host http://<host_ip>
通过这种方式,您可以轻松地将mLoRA部署为一个可持续运行的服务,随时接收并处理微调请求。
mLoRA的性能优势
mLoRA在消费级硬件上展现出了优秀的性能。以下是使用四张A6000显卡,采用fp32精度且不使用检查点和任何量化技术的情况下,mLoRA与其他方法的性能对比:
| 模型 | mLoRA (tokens/s) | PEFT-LoRA with FSDP (tokens/s) | PEFT-LoRA with TP (tokens/s) |
|---|---|---|---|
| llama-2-7b (32fp) | 2364 | 1750 | 1500 |
| llama-2-13b (32fp) | 1280 | OOM | 875 |
从表中可以看出,mLoRA在处理速度上显著优于其他方法,特别是在处理较大模型时,其优势更为明显。
支持的模型和算法
mLoRA目前支持以下模型和算法:
-
支持的模型:
- LLaMA
-
支持的LoRA变体:
- QLoRA (NIPS 2023)
- LoRA+ (ICML 2024)
- VeRA (ICLR 2024)
- DoRA (ICML 2024)
-
支持的偏好对齐算法:
- DPO (NeurIPS 2024)
- CPO (ICML 2024)
- CIT (arXiv 2024)
这种广泛的支持使得mLoRA能够适应各种不同的模型微调需求。
贡献与开源社区
mLoRA是一个开源项目,欢迎社区成员参与贡献。如果您想为mLoRA做出贡献,可以遵循以下步骤:
- Fork 仓库
- 创建新的分支用于开发新功能或修复bug
- 提交pull request,并详细说明您的更改
项目使用pre-commit来检查代码质量,您可以通过以下方式安装和使用:
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commit
或者直接运行检查脚本:
.github/workflows/pre-commit
总结
mLoRA作为一个高效的多LoRA适配器训练与推理框架,为大型语言模型的定制化微调提供了一个强大的解决方案。通过其创新的设计,mLoRA不仅大大提高了训练效率,还显著降低了资源消耗,使得即使在有限的硬件条件下也能进行复杂的模型微调任务。
随着AI技术的不断发展,像mLoRA这样的工具将在推动大型语言模型的个性化和专业化应用方面发挥越来越重要的作用。无论是对于研究人员还是工程师,mLoRA都提供了一个值得深入探索和使用的强大平台。
最后,作为一个开源项目,mLoRA的成功离不开社区的支持和贡献。我们鼓励更多的开发者和研究者参与到mLoRA的开发中来,共同推动这个项目的发展,为AI领域的进步贡献力量。









