
项目简介
modded-nanogpt是由GitHub用户KellerJordan开发的一个开源项目,旨在提高GPT-2模型的训练效率。该项目基于Andrej Karpathy的llm.c仓库中的PyTorch GPT-2训练器进行了改进。主要特点包括:
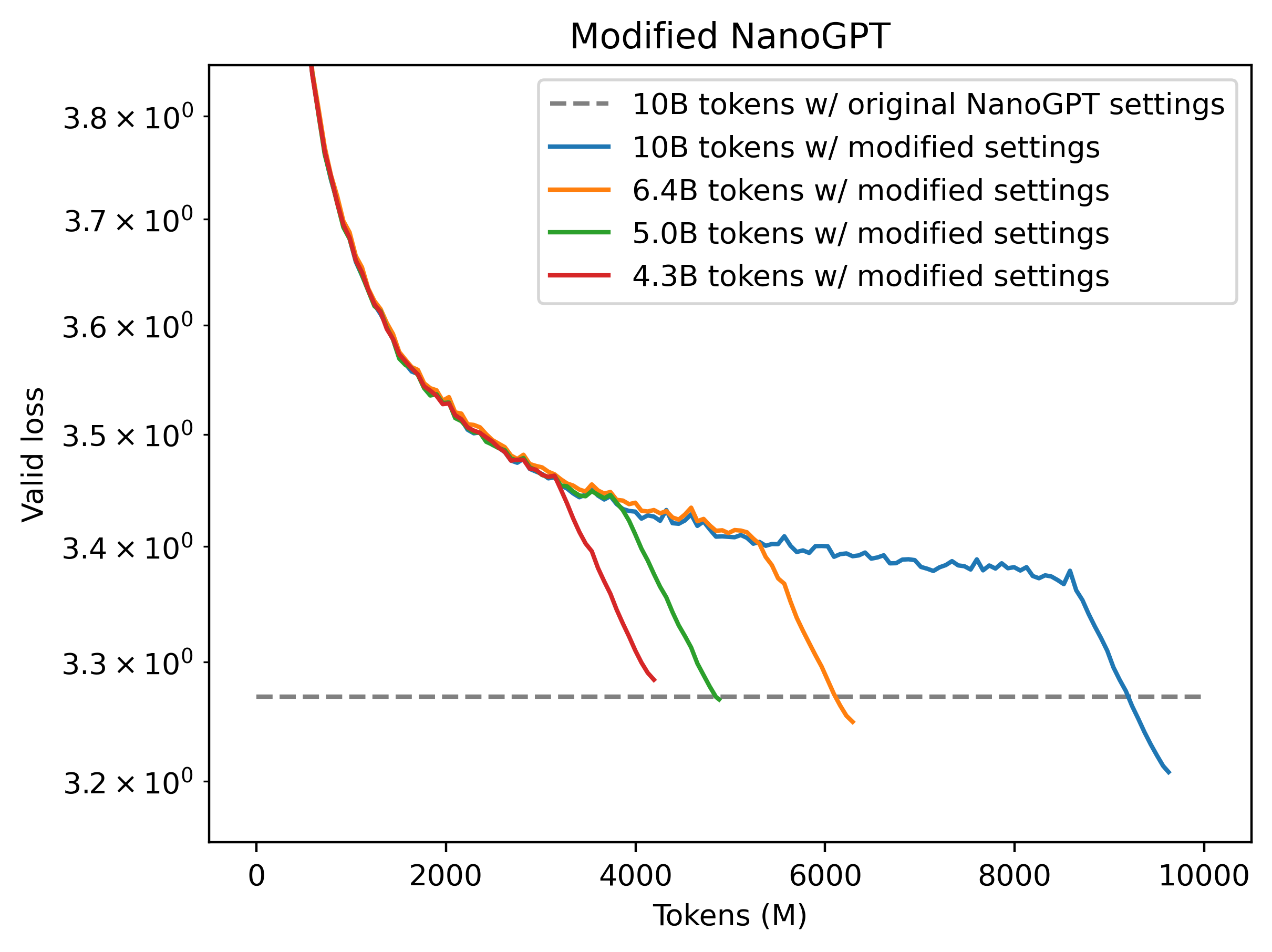
- 训练效率提高2倍,仅需5B个token就能达到原版10B个token才能实现的验证损失。
- 代码更加简洁,从858行减少到446行。
- 引入了诸如旋转位置编码等现代化技术。
核心改进
modded-nanogpt项目通过以下几个关键改进实现了训练效率的大幅提升:
- 将学习率提高了3倍。
- 采用了梯形学习率调度策略,参考了arXiv:2405.18392论文。
- 使用旋转位置编码(Rotary Embeddings)替代了原始的位置编码方式。
- 移除了残差连接前线性层的特殊初始化,转而使用固定标量来缩小注意力模块的输出。
- 简化了模型架构,去除了所有仿射缩放和偏置参数,改用RMSNorm进行归一化。
这些改进不仅提高了训练效率,还简化了代码结构,使得模型更易于理解和维护。
性能对比
根据项目描述,modded-nanogpt在Fineweb验证集上的表现令人印象深刻:
- modded-nanogpt: 在5B个token的训练后,验证损失达到3.2818。
- 原始llm.c训练器: 在10B个token的训练后,验证损失为3.2847。
这意味着modded-nanogpt不仅能够以更少的训练数据达到相似的性能,而且还略微超越了原始版本。
使用方法
要运行modded-nanogpt项目,只需执行以下两个简单的命令:
python data/fineweb.py
./run.sh
这将会训练一个124M参数的Transformer模型,使用5B个token进行训练。
技术细节
为了简化代码并提高训练速度,项目做出了一些权衡:
- 移除了部分功能,包括文本生成功能。
- 在架构和超参数方面略微偏离了GPT-2论文的严格复现。
值得注意的是,虽然使用RMSNorm替代了原有的归一化方法会导致轻微的性能下降,但开发者认为这种权衡是值得的,因为它显著降低了代码的复杂度。
项目影响
modded-nanogpt项目展示了如何通过精心的优化和现代化技术,大幅提升大型语言模型的训练效率。这对于以下几个方面具有重要意义:
- 研究加速: 允许研究人员更快地迭代和实验不同的模型架构和训练策略。
- 资源节约: 通过提高训练效率,可以显著降低计算资源的消耗,这对于环境保护和成本控制都有积极意义。
- 开源贡献: 项目的开源性质使得整个AI社区都能从中受益,促进了知识的共享和技术的进步。
未来展望
尽管modded-nanogpt已经取得了显著的进展,但仍有进一步改进和扩展的空间:
- 重新引入文本生成功能,以便更直观地展示模型的能力。
- 探索将这些优化技术应用到更大规模模型的可能性。
- 进一步优化代码,可能还有提升训练效率的空间。
- 与社区合作,收集反馈并整合更多创新想法。
总结
modded-nanogpt项目成功地展示了如何通过精心的工程优化和现代化技术,显著提高GPT-2模型的训练效率。它不仅为研究人员和开发者提供了一个高效的工具,也为整个AI领域的发展提供了有价值的启示。通过开源共享这些改进,项目为推动大型语言模型的民主化和可持续发展做出了重要贡献。
对于那些对NLP和深度学习感兴趣的开发者和研究人员来说,深入研究modded-nanogpt的代码和原理将是一个极好的学习机会。它不仅能帮助理解GPT-2模型的工作原理,还能学习到如何优化深度学习模型的训练过程。
随着AI技术的不断发展,像modded-nanogpt这样的项目将继续推动大型语言模型的边界,使它们变得更加高效、可访问和实用。我们期待看到这个项目在未来会如何演变,以及它将如何影响整个AI领域的发展方向。









